Deepmind Introduces Flamingo: An Open-Ended Single Visual Language Model (VLM) For Multimodal Machine Learning Research
This Article Is Based On The Research Paper 'Flamingo: a Visual Language Model for Few-Shot Learning'. All Credit For This Research Goes To The Deepmind Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Intelligence measures how quickly a person can adjust to a new situation using only a few simple instructions. Despite the contrasts between the two, children may recognize real animals in the zoo after seeing a few photographs of the animals in a book. On the other hand, Typical visual models do not yet reflect this level of human intellect. They need to be trained on tens of thousands of examples that have been explicitly annotated for that task. If the goal is to count and identify animals in an image, such as “three zebras,” thousands of photographs must be collected and each image annotated with their numbers and species. The requirement to train a new model each time it is confronted with a new job is the most predominant drawback, making the process inefficient, costly, and resource-intensive due to the vast quantity of annotated data required.
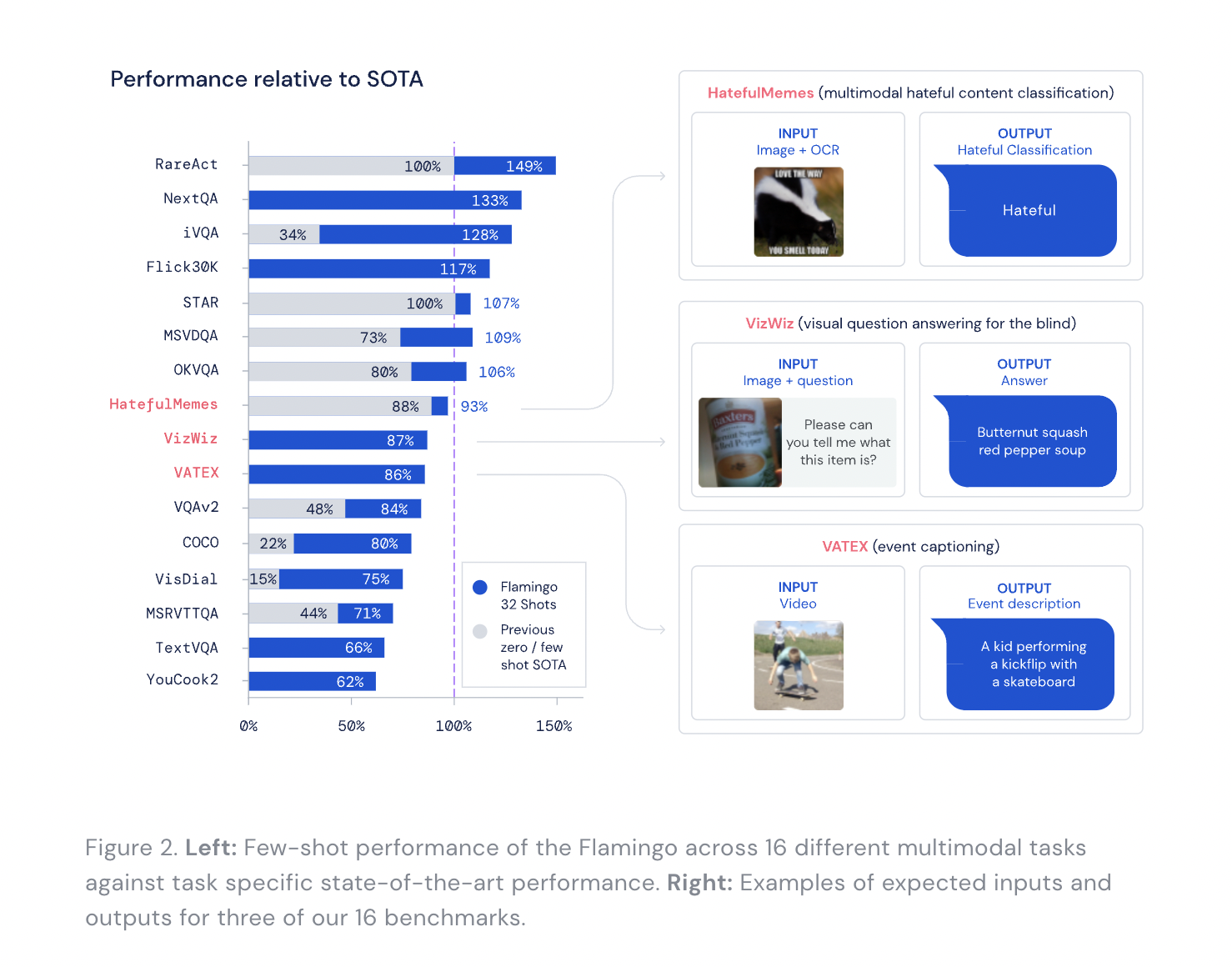
In its most recent paper, Google’s Deepmind presented a family of machine learning models called Flamingo to address this challenge by getting better results with less intensive training. Flamingo is a single visual language model (VLM) that sets a new state-of-the-art in few-shot learning on a wide range of open-ended multimodal tasks. Flamingo can solve several complex issues using only a few task-specific examples and no extra training. Flamingo takes a prompt of multimodal data consisting of interleaved images, videos, and text as input and gives a text-only output with affiliated language using its simple interface. In other words, Flamingo can do an inference task by returning the input’s explanation text with only a few samples given during training. It outperforms all previous few-shot learning algorithms, according to the Deepmind researchers, even ones fine-tuned with orders of magnitude more data.
Flamingo combines pre-trained language models individually with powerful visual representations and unique architecture components in practice. Deepmind trains Flamingo using Chinchilla, its recently released 70 billion parameter language model, obviating the need for any extra task-specific fine-tuning. The model can be directly applied to visual tasks after this training. The 43.3 million-item training dataset was amassed entirely from the internet and comprised of a mix of complementing unlabeled multimodal data.


The model’s qualitative capabilities were tested by captioning photographs with gender and skin color, and the captions were then run through Google’s Perspective API to assess text toxicity. While the preliminary findings were encouraging, the team believes that more study into evaluating ethical risks in multimodal systems is required before deployment to address AI bias. Flamingo outperforms all previous few-shot learning algorithms when given as few instances per challenge. The model also faces certain limitations regarding few-shot training, primarily when there are too many variables to account for when the training dataset is so small.
Flamingo is not just for unlabeled data; it can also improve the condition of machine learning in general, which is grappling with the rising cost of energy and processing required to train newer models. Deepmind concluded that the model is “computationally expensive to train,” although it does not explicitly mention the energy costs needed to train it. On the other hand, according to the team, Flamingo can be quickly adapted to low-resource environments and activities, such as analyzing data for PII, societal prejudices, stereotypes, and other variables. Even if Flamingo is not quite ready for prime time, models like this have much potential to improve society practically. Continuous research is being conducted to improve their flexibility and capacities so that they can be deployed safely for all.
Paper: https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/tackling-multiple-tasks-with-a-single-visual-language-model/flamingo.pdf
References:
- https://www.deepmind.com/blog/tackling-multiple-tasks-with-a-single-visual-language-model
- https://www.theregister.com/2022/04/29/flamingo_deepmind_ai/
Credit: Source link
Comments are closed.