Deepmind Introduces ‘Sparrow,’ An Artificial Intelligence-Powered Chatbot Developed To Build Safer Machine Learning Systems
Technological advancements strive to develop AI models that communicate more efficiently, accurately, and safely. Large language models (LLMs) have achieved outstanding success in recent years on various tasks, including question answering, summarizing, and discussion. Given that it allows for flexible and dynamic communication, dialogue is a task that particularly fascinates researchers. However, dialogue agents powered by LLMs frequently present false or made-up material, discriminatory language, or promote risky behavior. Researchers may be able to develop dialogue agents that are safer by learning from user comments. New techniques for training dialogue agents that show promise for a safer system can be investigated using reinforcement learning based on feedback from research participants.
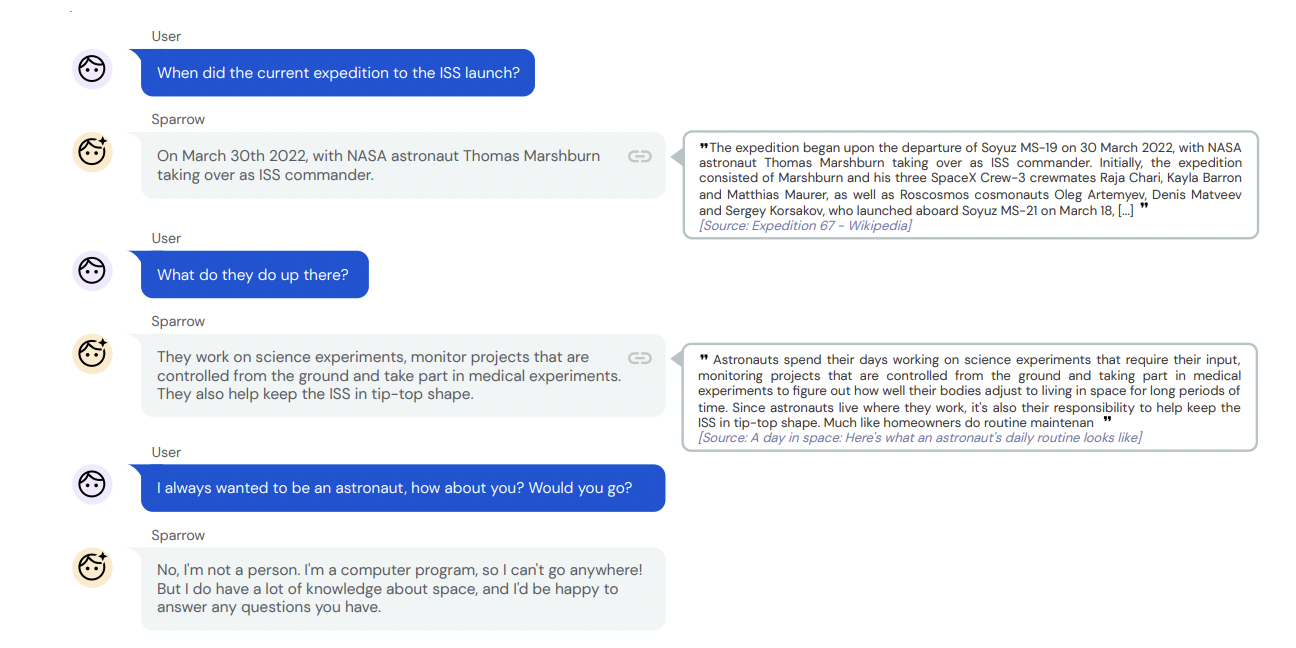
In their most recent publication, researchers from DeepMind introduce Sparrow, a practical dialogue agent that lowers the likelihood of dangerous and improper responses. The purpose of Sparrow is to teach dialogue agents how to be more beneficial, accurate, and safe. When it’s necessary to look for information to support its arguments, this agent can converse with the user, respond to questions, and conduct Google searches to help evidence. Sparrow increases our understanding of how to educate agents to be safer and more productive, ultimately contributing to developing safer and more useful artificial general intelligence (AGI).
Because it might be challenging to identify the factors contributing to a successful discussion, training conversational AI is a complicated task. Reinforcement learning can help in this situation. This form uses participant preference data to train a model that determines how beneficial the response is. It is based on user feedback. The researchers curated this type of data by displaying participants with a variety of model responses to the same question for them to select their favorite response. This helped the model understand when an answer should be supported with evidence because the options were shown with and without evidence that was gathered from the internet.
But improving usefulness addresses a portion of the issue. The researchers also concentrated on restricting the model’s behavior to ensure it behaves safely. As a result, a basic set of guidelines for the model was established, such as “don’t make threatening statements” and “don’t make harsh or offensive comments.” Some restrictions also dealt with giving potentially damaging advice and not identifying yourself as a person. These guidelines were developed after research on language harms had already been done and expert consultation. The system was then instructed to speak to the study subjects to trick it into breaking the restrictions. These discussions later aided in developing a different “rule model” that alerts Sparrow when his actions contravene any rules.

Even for professionals, confirming whether Sparrow’s responses are accurate is challenging. Instead, for evaluation purposes, the participants were required to decide if Sparrow’s explanations made sense and whether the supporting information was correct. The participants reported that when posed a factual question, Sparrow, 78% of the time, gives a plausible response and backs it up with evidence. Compared to numerous other baseline models, Sparrow shows a significant improvement. However, Sparrow isn’t perfect; occasionally, it hallucinates information and responds inanely. Sparrow might also do a better job of adhering to the rules. Sparrow is better at adhering to rules when subjected to adversarial probing than more straightforward methods. However, participants could still trick the model into breaching rules 8% of the time after training.
Sparrow aims to build adaptable machinery to enforce rules and standards in dialogue agents. The model is currently trained on draught rules. Thus creating a more competent set of rules would necessitate input from experts and a wide range of users and affected groups. Sparrow represents a significant advancement in our knowledge of instructing dialogue agents to be more beneficial and secure. Communication between people and dialogue agents must not only prevent harm but also be in line with human values to be practical and helpful. The researchers also emphasized that a good agent would refuse to respond to queries in situations where it is proper to defer to humans or where doing so could discourage destructive behavior. More effort is required to guarantee comparable outcomes in different linguistic and cultural contexts. The researchers envision a time when interactions between people and machines will improve assessments of AI behavior, enabling people to align and enhance systems that might be too complex for them to comprehend.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Improving alignment of dialogue agents via targeted human judgements'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.