DeepMind Introduces the Perception Test, a New Multimodal Benchmark Using Real-World Videos to Help Evaluate the Perception Capabilities of a Machine Learning Model
Benchmarks have influenced artificial intelligence (AI) in defining research goals and enabling researchers to track progress toward those goals.
An important component of intelligence is perception, the process of experiencing the world through the senses. It is becoming more crucial in fields like robotics, self-driving cars, personal assistants, and medical imaging, which develop agents with human-level perceptual comprehension of the world.
Perceiver, Flamingo, and BEiT-3 are a few examples of multimodal models that seek to be more inclusive models of perception. But because no designated benchmark was available, their assessments were based on several specialized datasets. These benchmarks include Kinetics for video action recognition, an Audio set for audio event classification, MOT for object tracking, and VQA for image question answering.
Many other perception-related benchmarks are also currently being used in AI research. Although these benchmarks have enabled incredible advancements in the design and development of AI model architectures and training methodologies, each exclusively focuses on a small subset of perception: Visual question-answering tasks typically focus on high-level semantic scene understanding. Object-tracking tasks typically capture the lower-level appearance of individual objects, like color or texture. Image benchmarks do not include temporal aspects. And only a small number of benchmarks provide tasks across visual and aural modalities.

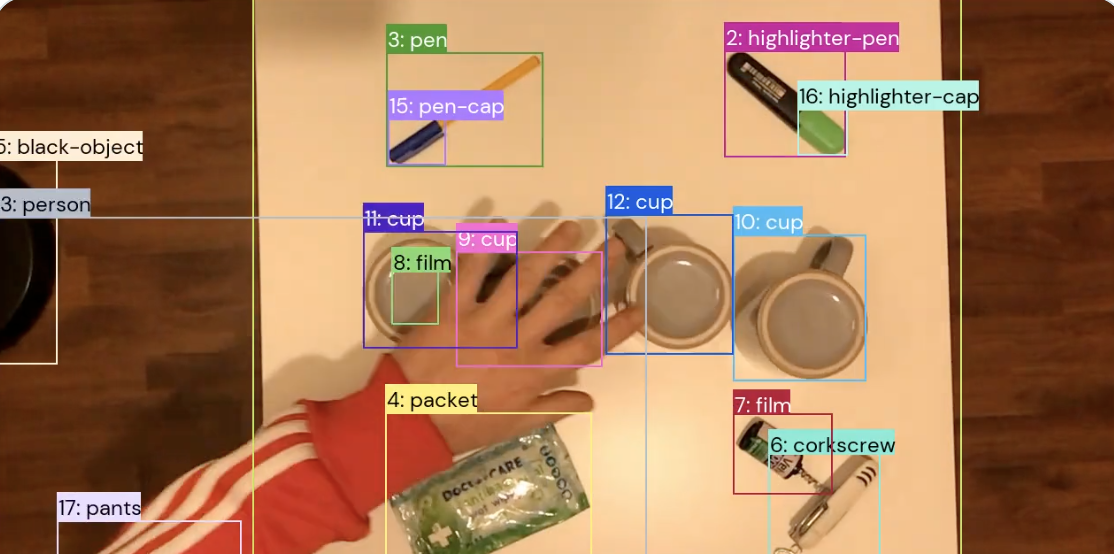
A new DeepMind research produced a collection of films of real-world events that were specifically constructed and labeled according to six different sorts of tasks to address many of these problems. They are:
- Item tracking: A box is drawn around an object at the beginning of the movie, and the model is required to return a complete track throughout the film.
- Localization of temporal actions: The model must categorize and localize a predetermined set of actions in time.
- Temporal sound localization: The model must localize and categorize a series of sounds in time.
- Multiple-choice video question-answering consists of text questions concerning the video, each of which has three possible responses.
- Answering textual questions about the video using a model that must return one or more object tracks is known as grounded video question-answering.
To create a balanced dataset, the researchers used datasets like CATER and CLEVRER and created 37 video scripts with various permutations. The videos feature straightforward games or everyday tasks, enabling them to specify the tasks that call on the knowledge of semantics, understanding of physics, temporal reasoning or memory, and abstraction capabilities.
The model developers may use the tiny fine-tuning set (20%) in the Perception Test to explain the nature of the tasks to the models. The remaining data (80%) comprises a held-out test split where performance can only be assessed through our evaluation server and a public validation split.
The researchers test their work throughout the six computing tasks, and the evaluation results are comprehensive across numerous aspects. For a more thorough study, they also mapped questions across different situational kinds depicted in the videos and different types of reasoning needed to answer the questions for the visual question-answering activities.
When creating the benchmark, making sure that the participants and the scenes in the videos were diverse was crucial. To achieve this, they chose volunteers from several nations who represented various racial and ethnic groups and genders to have varied representation in each type of video screenplay.
The Perception Test is intended to stimulate and direct future investigation into broad perception models. In the future, they hope to work with the multimodal research community to add more measures, tasks, annotations, or even languages to the benchmark.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Perception Test: A Diagnostic Benchmark for Multimodal Models'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.