Deepmind Proposes LASER-NV: A Conditional Generative Model of Neural Radiance Fields Capable of Efficient Inference of Large and Complex Scenes Under Partial Observability Conditions
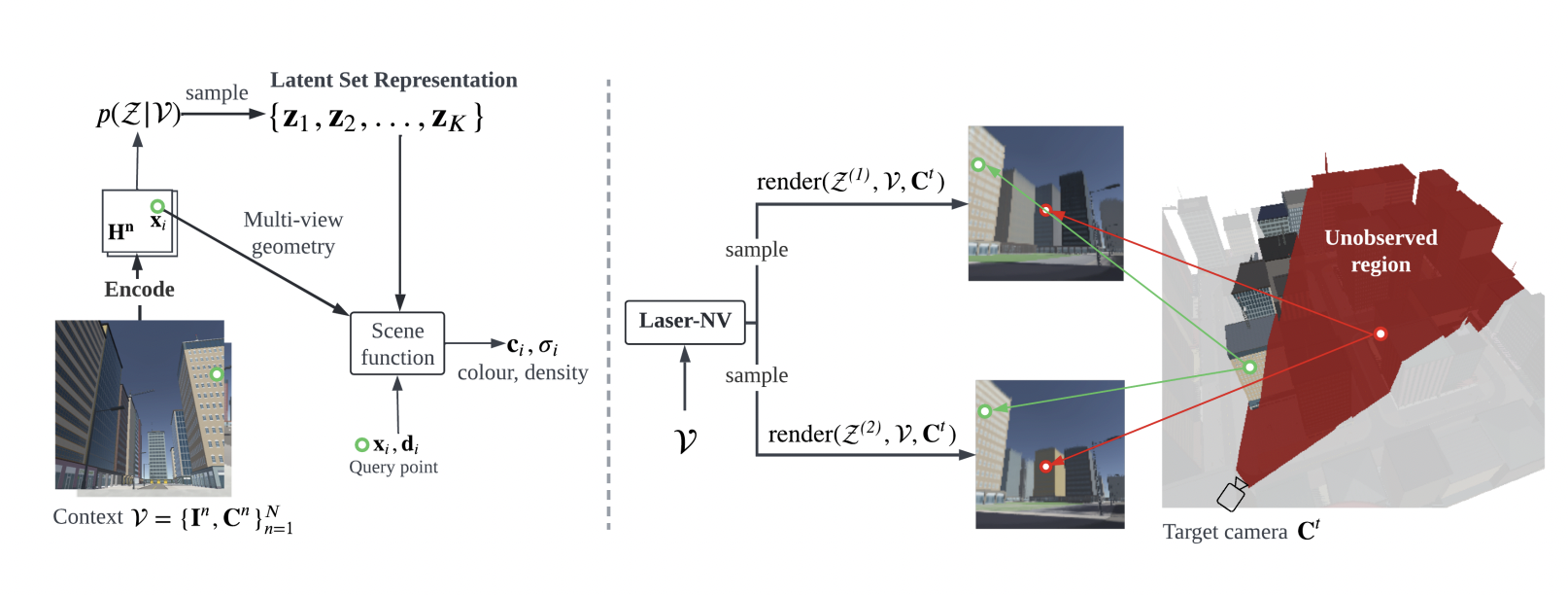
Modeling and rendering 3D scenes can have immense applications in the fields like VR, Game development, and Design and Animation. Neural Radian Field (NeRF) is a machine learning model that can generate 3D scenes from an arbitrary viewpoint with very high fidelity. But there are certain limitations of NeRF. It requires a large number of views that covers the scene to understand the scene completely. Some further modifications of NeRF are proposed in future works that try to solve this problem by learning a prior over scenes. But, these approaches apply it only on very simple scene synthesis tasks and fails at synthesizing unobserved part of the scene.
To address this problem, a team of scientists from DeepMind proposed LASER-NV: Latent Set Representations for High-Fidelity Novel View Synthesis. LASER-NV is a conditional generative model of NeRF capable of generating large and complex scenes with few arbitrary viewpoints only. It can also generate diverse and plausible views for the unobserved areas meanwhile being consistent with the observed ones. To maintain this consistency over the observed views, LASER-NV uses a geometry-informed attention mechanism over the observed views. In addition, LASER-NV is evaluated on three datasets: the ShapeNet dataset, Multi-ShapeNet, and a novel “City” dataset (large simulated urban areas).
LASER-NV works in the following manner (as shown in Figure 1): LASER-NV infers a set-valued latent Z based on n- Image and Camera pairs using an encoder. A prior P(Z|(context)) is learned over the latents. For query, a point in space with coordinates xi and direction di are passed as a query to the scene function; simultaneously, the latents from the prior are combined with the local features Hn that are back-projected from the context views- producing color and density.
For inference, we pass latents, context from observed views, and camera as input to the renderer. It generates diverse plausible views for different latents consistent with the observation.
The results of the experiments are presented in Table 1, 2 and 3.
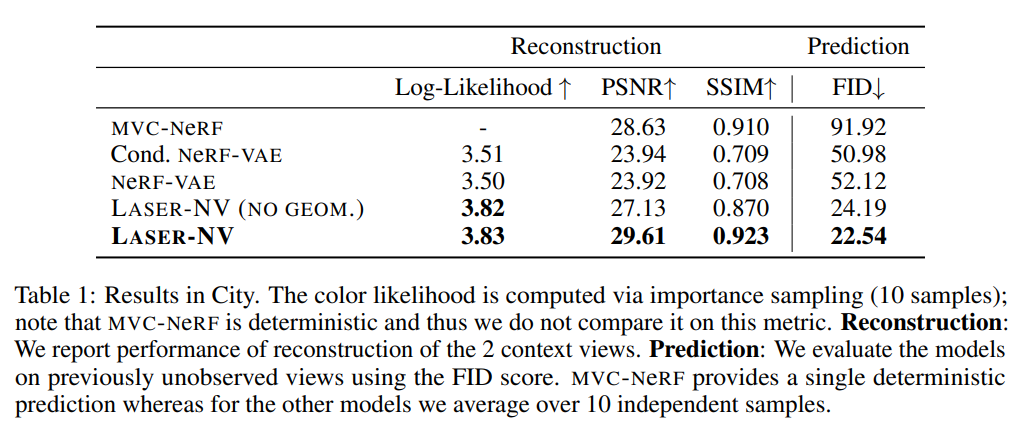


In conclusion, LASER-NV is a conditional generative model of neural radiance fields that is capable of efficient inference of large and complex scenes under partial observability conditions. They experimentally showed that LASER-NV is capable of modeling scenes of different scale and uncertainty structures. However, LASER-NV also inherits some of the drawbacks of NeRF, including computational cost and the need for accurate GT camera information. Despite these challenges, this work is an important step towards learning a generative scene model of real scenes. Future research directions include incorporating fast NeRF implementations, object-centric structure and dynamics, and localization methods.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.