DeepMind Researchers Introduce AlphaStar Unplugged: A Leap Forward in Large-Scale Offline Reinforcement Learning by Mastering the Real-Time Strategy Game StarCraft II
Games have long served as crucial testing grounds for evaluating the capabilities of artificial intelligence (AI) systems. As AI technologies have evolved, researchers have sought more complex games to assess various intelligence facets relevant to real-world challenges. StarCraft, a Real-Time Strategy (RTS) game, has emerged as a “grand challenge” for AI research due to its intricate gameplay, pushing the boundaries of AI techniques to navigate its complexity.
In contrast to earlier AI achievements in video games like Atari, Mario, Quake III Arena Capture the Flag, and Dota 2, which were based on online reinforcement learning (RL), often involved constraining game rules, providing superhuman abilities, or utilizing simplified maps, StarCraft’s complexity has proven a formidable obstacle for AI methods. However, these online reinforcement learning (RL) algorithms have succeeded significantly in this domain. Yet, their interactive nature poses challenges for real-world applications, demanding high interaction and exploration.
This research introduces a transformative shift towards offline RL, allowing agents to learn from fixed datasets – a more practical and safer approach. While online RL excels in interactive domains, offline RL harnesses existing data to create deployment-ready policies. The introduction of the AlphaStar program by DeepMind researchers marked a significant milestone by becoming the first AI to defeat a top professional StarCraft player. AlphaStar has mastered StarCraft II’s gameplay, using a deep neural network trained through supervised learning and reinforcement learning on raw game data.
Leveraging an expansive dataset of human player replays from StarCraft II; this framework enables agent training and evaluation without requiring direct environment interaction. StarCraft II, with its distinctive challenges such as partial observability, stochasticity, and multi-agent dynamics, makes for an ideal testing ground to push the boundaries of offline RL algorithm capabilities. “AlphaStar Unplugged” establishes a benchmark tailored to intricate, partially observable games like StarCraft II by bridging the gap between traditional online RL methods and offline RL.
The core methodology of “AlphaStar Unplugged” revolves around several key contributions that establish this challenging offline RL benchmark:
- The training setup employed a fixed dataset and defined rules to ensure fair comparisons between methods.
- A novel set of evaluation metrics is introduced to measure agent performance accurately.
- A range of well-tuned baseline agents is provided as starting points for experimentation.
- Recognizing the considerable engineering effort required to build effective agents for StarCraft II, the researchers furnish a well-tuned behavior cloning agent that forms the foundation for all agents detailed in the paper.
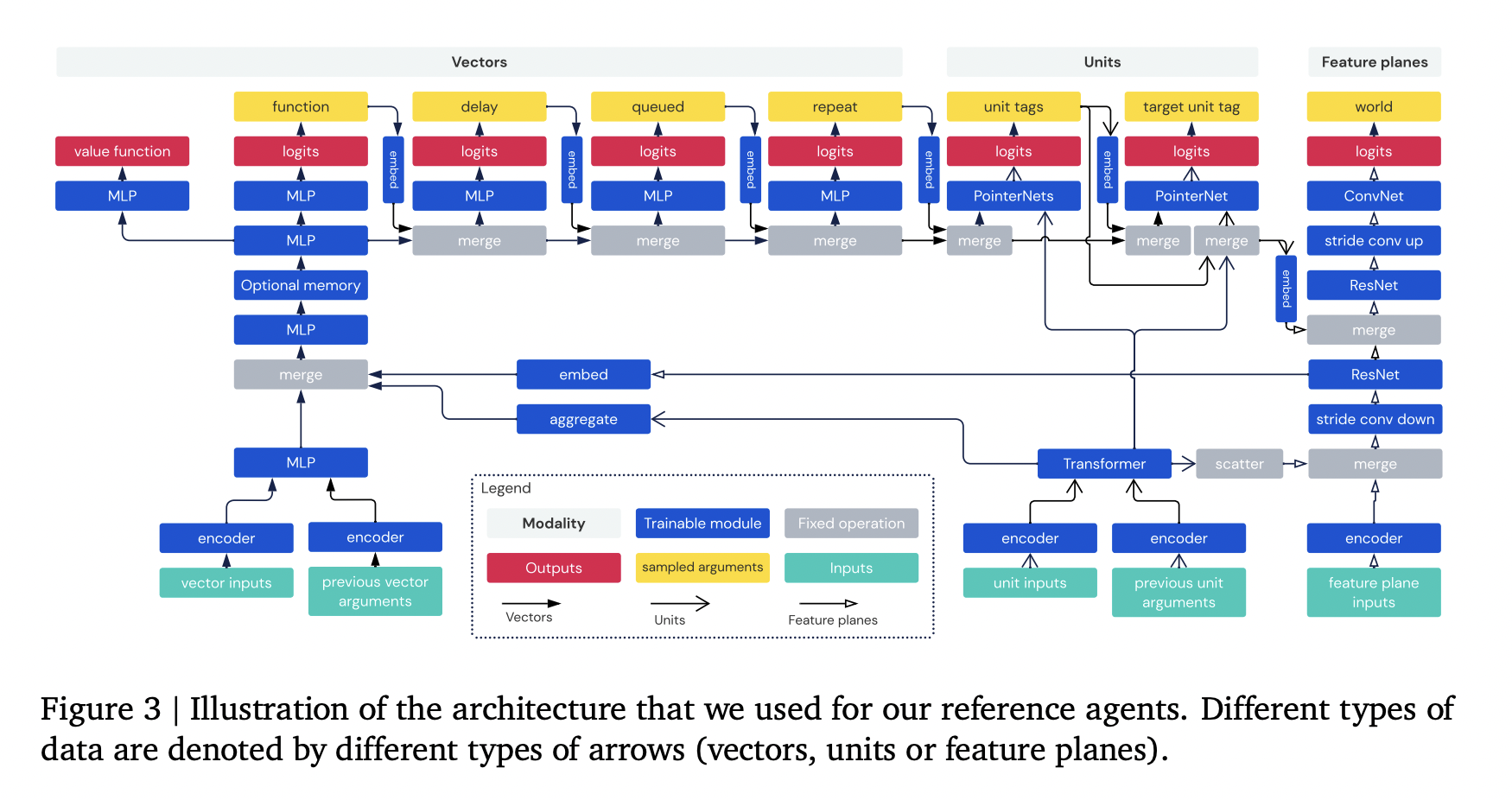
The “AlphaStar Unplugged” architecture involves several reference agents for baseline comparisons and metric evaluations. Inputs to the StarCraft II API are structured around three modalities: vectors, units, and feature planes. The actions consist of seven modalities: function, delay, queued, repeat, unit tags, target unit tag, and world action. Multi-layer perceptrons (MLP) encode and process vector inputs, transformers handle unit inputs, and residual convolutional networks manage feature planes. Modalities are interconnected through unit scattering, vector embedding, convolutional reshaping, and memory usage. Memory is incorporated into the vector modality, and a value function is employed alongside action sampling.

The experimental results underscore the remarkable achievement of offline RL algorithms, demonstrating a 90% win rate against the previously leading AlphaStar Supervised agent. Notably, this performance is achieved solely through the utilization of offline data. The researchers envision their work will significantly advance large-scale offline reinforcement learning research.

The matrix shows normalized win rates of reference agents, scaled between 0 and 100. Note that draws can affect totals, and AS-SUP represents the original AlphaStar Supervised agent.
In conclusion, DeepMind’s “AlphaStar Unplugged” introduces an unprecedented benchmark that pushes the boundaries of offline reinforcement learning. By harnessing the intricate game dynamics of StarCraft II, this benchmark sets the stage for improved training methodologies and performance metrics in the realm of RL research. Furthermore, it highlights the promise of offline RL in bridging the gap between simulated and real-world applications, presenting a safer and more practical approach to training RL agents for complex environments.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.