DeepMind Researchers Introduce Reinforced Self-Training (ReST): A Simple algorithm for Aligning LLMs with Human Preferences Inspired by Growing Batch Reinforcement Learning (RL)
Large language models (LLMs) are outstanding at producing well-written content and resolving various linguistic problems. These models are trained using vast volumes of text and computation to increase the chance of the following token autoregressively. Former research, however, shows that creating text with high probability only sometimes corresponds well with human preferences on different tasks. The language models may produce dangerous material with detrimental effects if not properly aligned. Additionally, aligning LLMs enhances the performance of other downstream operations. Utilizing human preferences, reinforcement learning from feedback seeks to solve the alignment issue.
A reward model is typically learned via human input and then used to fine-tune LLM using a reinforcement learning (RL) goal. RLHF techniques frequently use online RL techniques like PPO and A2C. The modified policy must be sampled during online training, and samples must be scored repeatedly using the reward model. Online approaches are constrained by the computational expense of handling a constant stream of fresh data, particularly as the sizes of the policy and reward networks expand. Additionally, previous studies examined model regularisation to address the “hacking” problem that these approaches are prone to. As an alternative, offline RL algorithms are more computationally efficient and less vulnerable to reward hacking because they learn from a predefined dataset of samples.
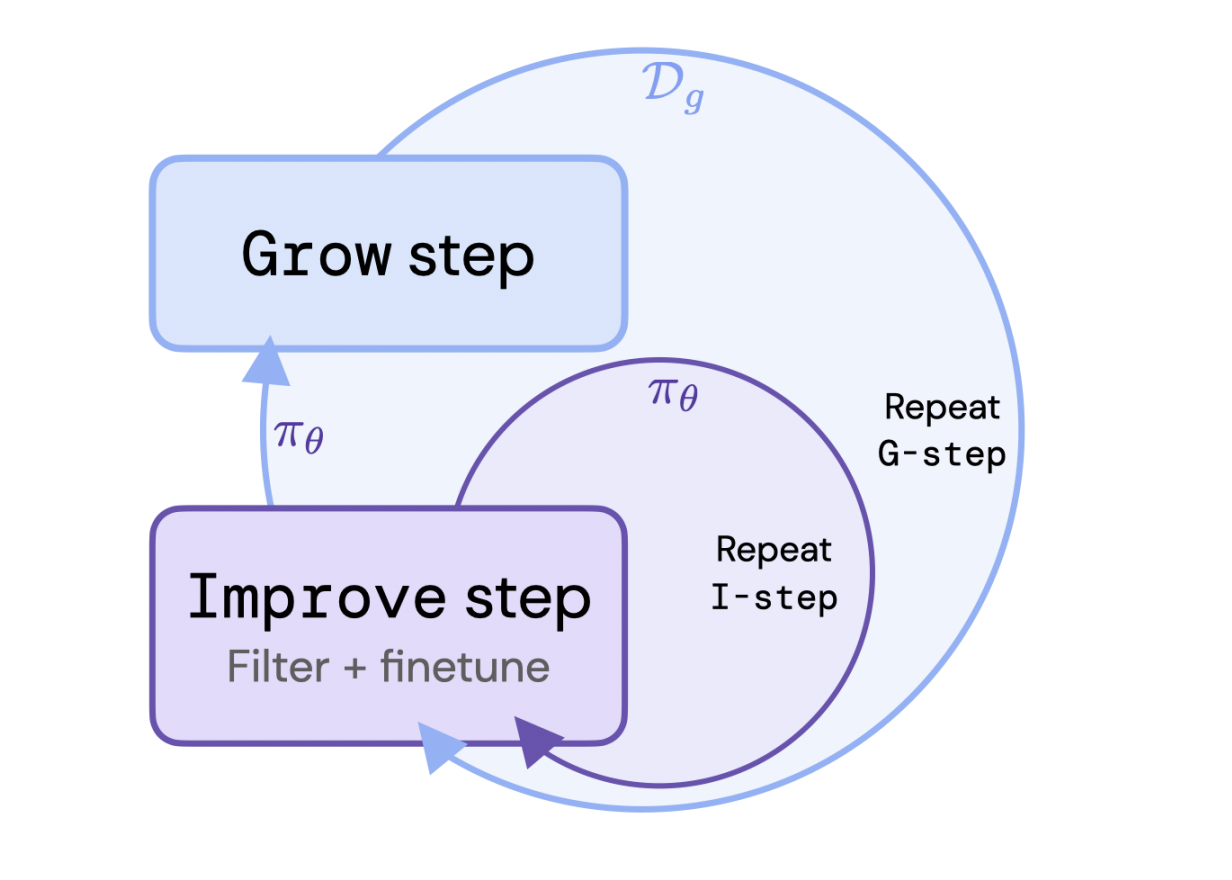
However, the characteristics of the offline dataset are inextricably linked to the quality of the policy learned offline. Because of this, well-selected datasets are crucial to the success of offline RL. Otherwise, the improvements in performance above supervised learning can be modest. They also put forth a technique known as DPO (Direct Preference Optimisation), which may use offline data to match an LM with human preferences. Researchers from Google present the language model alignment issue as a rising batch RL issue and their Reinforced Self-Training (ReST) technique consists of two loops: the inner loop (Improve) improves the policy on a given dataset. In contrast, the outer circle (Grow) expands the dataset by taking samples from the most recent policy (see Figure 1).

The phases of ReST are as follows after considering conditional language modeling in this work: 1. Grow (G): To supplement the training dataset, numerous output predictions are produced for each scenario using the language model policy (at first, a supervised policy). 2. Enhance (I): They rank and filter the enriched dataset using a scoring formula. As the scoring function in their studies, they employ a learning reward model trained on consumer preferences. The filtered dataset adjusts the language model using an offline RL goal. With an increasing filtering threshold, repeat this process. The next Grow step uses the final policy after that. ReST is a general approach that allows different offline RL losses to be used in the inner loop when executing the Improve steps. ReST is a broad strategy that enables various offline RL losses in the inner circle when carrying out the Improve stages.
It just requires the capacity to 1) effectively sample from a model and 2) score the model’s samples to be put into practice. ReST has several benefits over the standard RLHF approach using either online or offline RL:
• The output of the Grow phase is utilized over numerous Improve stages, greatly reducing the computing cost compared to online RL.
• Since new training data is sampled from an improved policy during the Grow step, the quality of the policy is not constrained by the quality of the original dataset (unlike in offline RL).
• It is simple to inspect the data quality and potentially diagnose alignment problems, such as reward hacking, as the Grow and Improve steps are decoupled.
• There are few hyperparameters to tweak, and the technique is straightforward and reliable.
Machine translation is a sequence-to-sequence learning issue typically expressed as conditional language modelling, with a phrase in a foreign language serving as the conditioning context (source). They choose machine translation because (a) it is a useful application with solid baselines and a clear assessment process, and (b) several credible current scoring and evaluation methods may be used as a reward model. They compare several offline RL algorithms in their studies on the IWSLT 2014 and WMT 2020 benchmarks, as well as more challenging, high-fidelity internal benchmarks on the Web Domain. ReST dramatically raises reward model results on test and validation sets in their trials. ReST produces better quality translations than a supervised learning baseline, according to human raters.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.