Deepmind Researchers Propose A Machine Learning-Based Framework For Doing Research On Hour-Long Films Using The Same Technology That Can Presently Analyze Second-Long Videos
Raw movies are massive and must be compressed before being saved on a disc; once loaded, they are decompressed and placed in device memory before being used as inputs to neural networks. Because vision pipelines do not scale well beyond that point, most computer vision research focuses on short time scales of two to ten seconds at 25fps (frames-per-second). In this context, and with present technology, training models on minute-long raw films might require excessive time or physical memory. Loading such films onto GPU or TPU may become impractical, as it necessitates decompression and transmission, frequently over bandwidth-limited network infrastructure.
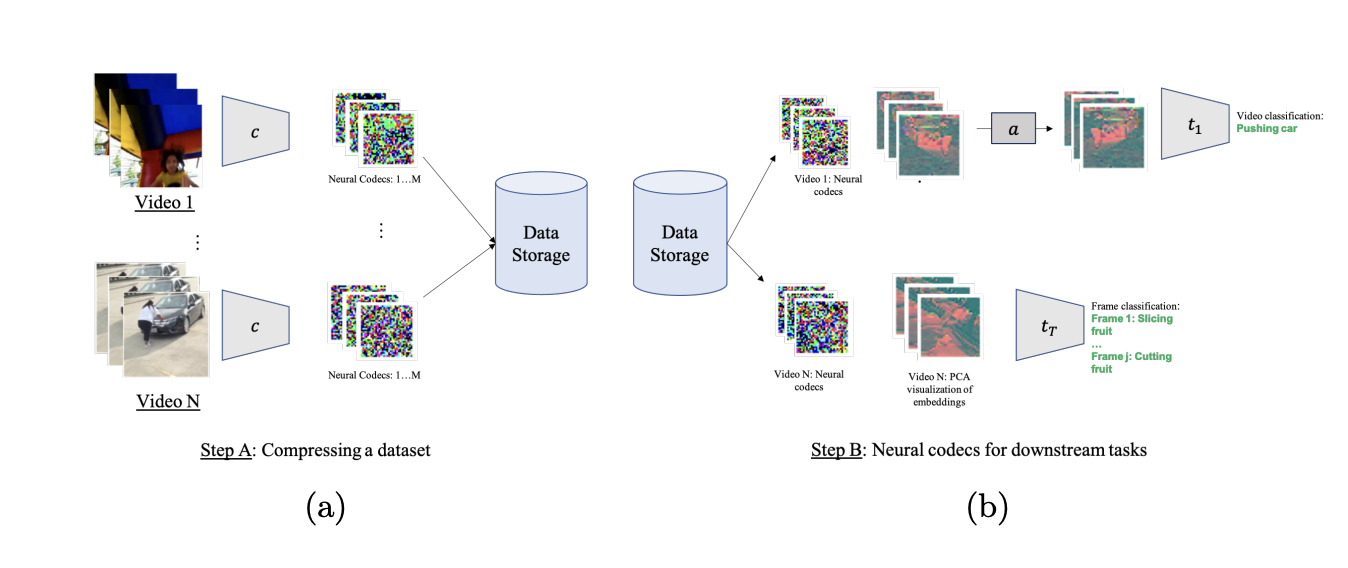
While prior research tried directly feeding conventional video or picture compression codecs (such as JPEG or MPEG) into their models, this often necessitates specialized neural network designs. In this paper, they propose and analyze the compressed vision, a novel, efficient, and scalable video pipeline that retains the capacity to employ most of the state-of-the-art data processing and machine learning approaches created for videos. They begin by training a neural compressor to compress videos. Second, they may utilize an augmentation network to alter the compressed space to do augmentations.
Third, they use common video backbone architectures to train and assess these neural codes on typical video comprehension tasks (thereby avoiding costly decompression of the videos). Due to the modular nature of their system, each component might be replaced with a more efficient variant. Augmenting (e.g., spatial cropping or flipping) is a critical component of many pipelines used to train video models, but it is impractical to conduct directly in the constrained space. As a result, they are faced with the following difficulty. They can either abandon augmentations, decompress the codes, and perform the modifications in pixel space. However, if they choose the latter, they forfeit some of the benefits of the compressed area.
Decompressed signals take up more space; if they are long enough, they cannot fit into GPU or TPU memory. Furthermore, while a neural compressor achieves better compression rates than JPEG or MPEG, it has massive decoders that consume much more time and space; hence, neural decompression is sluggish. To address the last obstacle, they suggest an augmentation network, a tiny neural network that works directly on latent codes by changing them based on some operation.

The spatial cropping augmentation network accepts crop coordinates and a tensor of latent codes as inputs. The adjusted latents are then produced close to those generated by spatially cropping the video frames. In contrast, they learn how to enhance the compressed space rather than cutting the compressed tensor. As a result, they can train an augmentation network to execute a broader range of augmentations, such as adjusting the brightness or saturation or even completing rotations, which would be difficult or impossible to achieve by directly manipulating the tensor.
Their strategy has the following advantages. For starters, it enables common video structures to be easily applied to these neural codes rather than developing custom designs, as in the case of training networks directly on MPEG representations. Second, they may perform augmentations now on the latent principles without first decompressing them. This reduces training time and conserves memory. They can utilize standard video pipelines with minimum modifications and get competitive performance when processing raw videos with these two qualities (RGB values).
In summary, they show that neural codes generalize to a wide range of datasets and workloads (whole-video and frame-wise classification) and outperform JPEG and MPEG in terms of compression. They train and assess a second network that produces altered latents based on transformation arguments to enable augmentations in the latent space. In addition, they illustrate their system in considerably longer films. They compiled a vast collection of ego-centric movies shot by visitors while wandering around different cities1. These films are long and continuous, lasting from 30 minutes to ten hours. A few examples of their outcomes can be found on their website. They want to enhance it in the future, for example, by including the source code in the near future.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Compressed Vision for Efficient Video Understanding'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and project. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.