Deepmind Researchers Propose the Standardised Test Suite (STS): a Novel Method for Evaluating Agents that are Trained to Interact with Human Participants in a 3D Virtual World
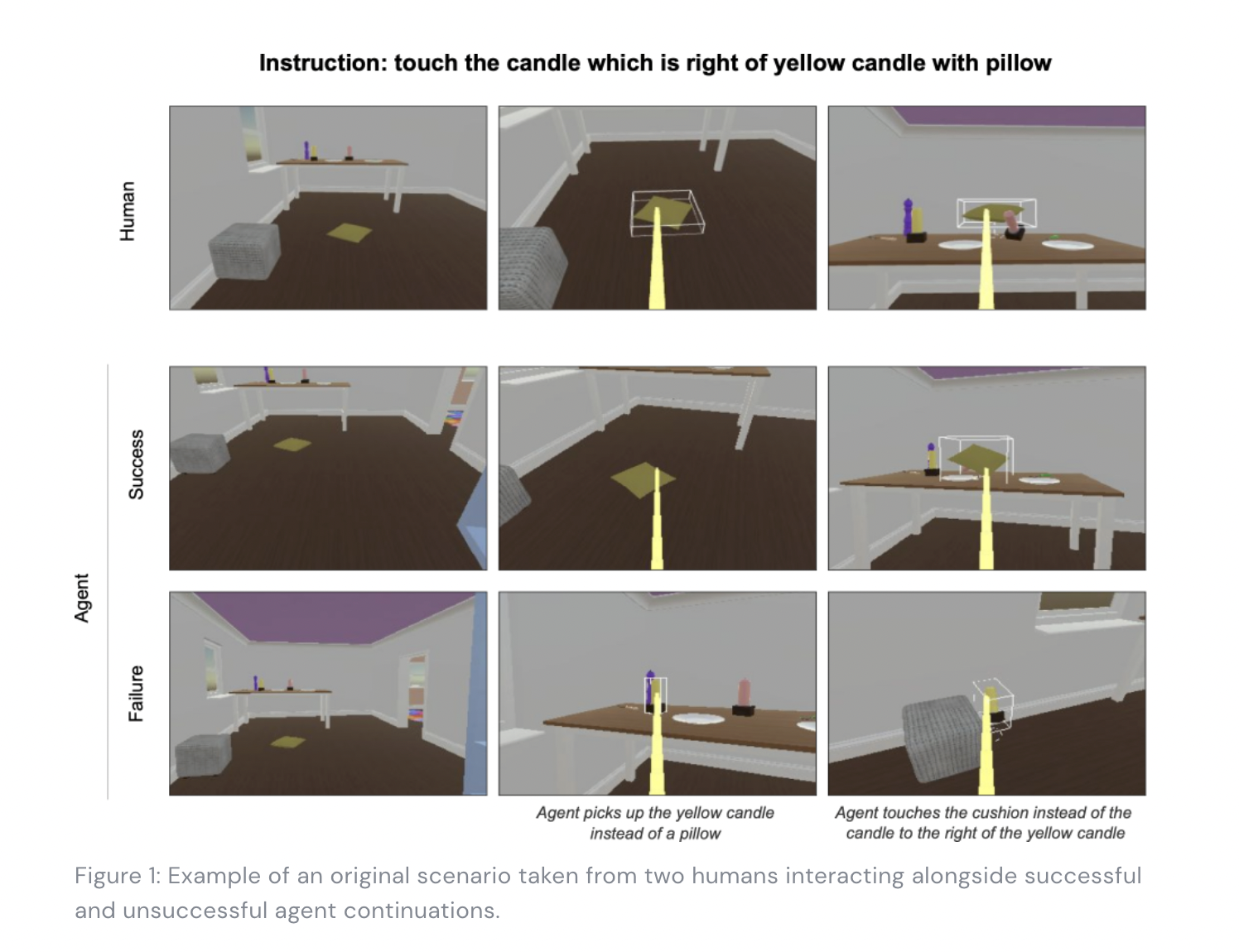
The aim of AI research has always been to create agents that can naturally interact with humans. However, evaluating these interactions is growing more difficult by the day. Gathering online human-agent interactions is time-consuming and costly, and speedier proxy measurements frequently do not correspond well with interactive evaluation. In a recent publication, Google’s DeepMind provides a new technique for evaluation dubbed the Standardised Test Suite (STS) to explore deeper into this study. Furthermore, the team investigates the advantages of existing evaluation criteria in depth. The STS employs behavioral situations derived from real-world human interactions. Agents can examine the replayed scenario context, receive instruction, and then take control of the interaction to execute it offline. These agent continuations are recorded and submitted to human annotators who rate them as successful or unsuccessful, and agents are ranked based on the percentage of continuations they succeed in. The resulting STS is quick, precise, interpretable, and accurate in simulating naturalistic interactions. Overall, the STS combines much of what is wanted across many of the usual evaluation parameters, allowing researchers to make faster progress toward creating agents that can interact with humans naturally.
To train agents that interact well with humans, it is necessary to be able to track development. On the other hand, human engagement is complicated, and assessing progress is tough. The Standardised Test Suite (STS) is a tool established by Deepmind researchers to evaluate agents in temporally prolonged, multi-modal interactions, according to DeepMind’s publication. Human participants instructed agents to execute tasks and answer questions in a 3D simulated environment, and the interactions were evaluated. STS places agents in various behavioral situations derived from real-world human interaction data. Human raters record these agent continuations and annotate them as success or failure. Agents are then ranked based on how many situations they complete. Human behavior that is second nature to them daily is challenging to describe and impossible to formalize. As a result, when agents are taught to have fluid and successful interactions with people, the reinforcement learning method that previous researchers have depended on for solving games will not operate. This is illustrated by the following two questions: “Who won this game of Go?” and “What are you looking at?” In the first scenario, a code that counts the stones on the board at the end of the game and accurately identifies the winner can be written. There is no definitive response to the question in the second scenario, and humans intuitively recognize the plethora of relevant aspects of answering such an innocuous inquiry.

Human participants can evaluate agent performance in an interactive setting. However, this is both loud and expensive. When people interact with agents for evaluation, it is challenging to keep track of the exact instructions they provide them. This type of evaluation is too sluggish to rely on for rapid real-time advancement. When it comes to interactive evaluation, previous studies have relied on proxies. Losses and scripted probe tasks are effective for quickly getting knowledge into agents, but they do not correspond well with interactive evaluation. The suggested new method has several benefits. The most important is that it gives control and speed to a metric that closely resembles DeepMind’s goal of creating agents who interact successfully with people. Machine learning has significantly benefited from the development of MNIST, ImageNet, and other human-annotated datasets. Researchers were able to train and test classification models using these datasets at a one-time cost of human inputs. The STS methodology seeks to achieve the same results for human-agent interaction research. This type of evaluation still necessitates humans annotating agent continuations; however, early trials suggest that these annotations could be automated, allowing for quick and successful automated evaluation of interactive agents. According to the researchers, other researchers can leverage the team’s methods and system design to speed up their research in this area and identify new areas.
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'Evaluating Multimodal Interactive Agents'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, blog and Video. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.