DeepMind Researchers Redefine Continual Reinforcement Learning with a Precise Mathematical Definition
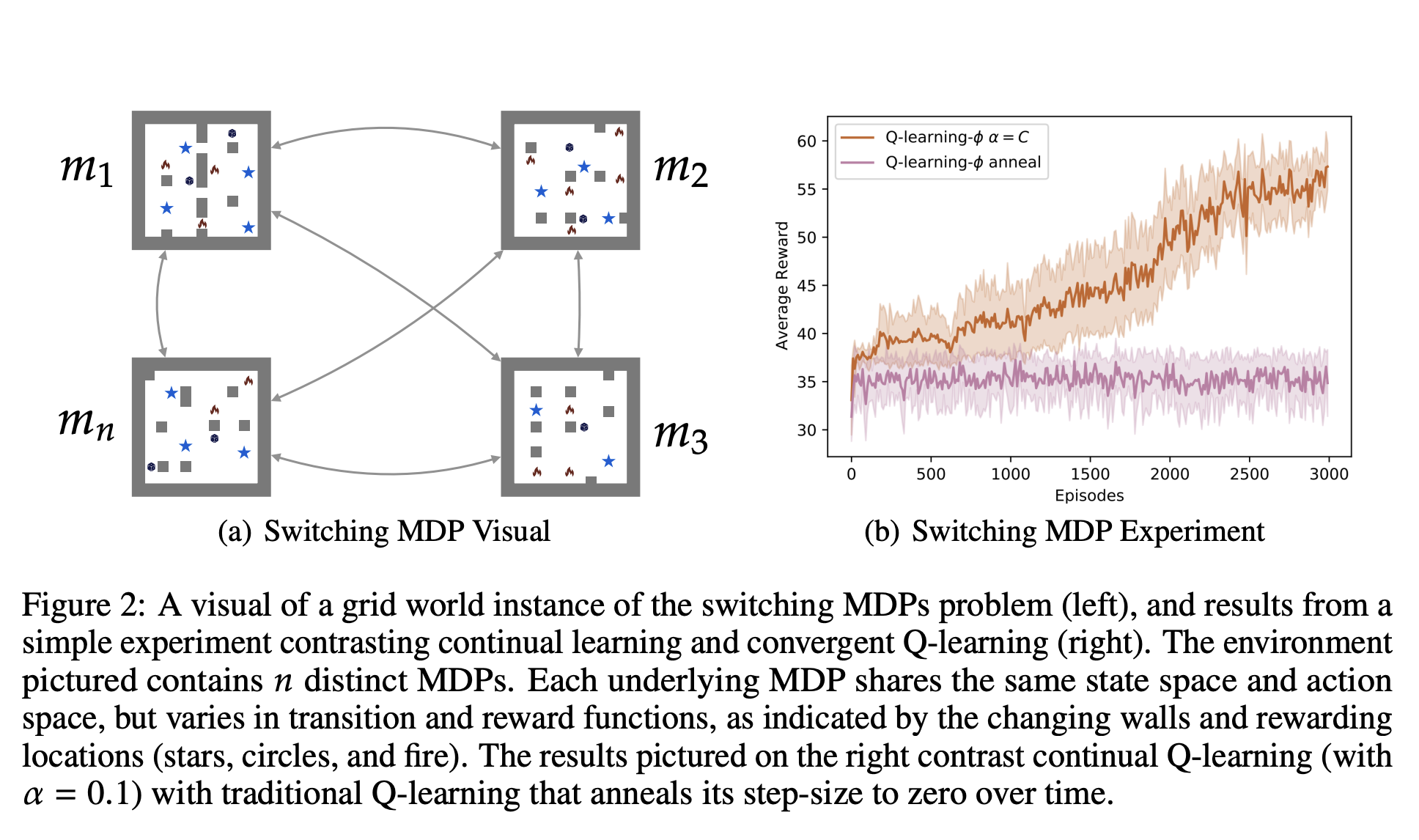
Recent advances in deep Reinforcement Learning ( RL ) have demonstrated superhuman performance by artificially intelligent (AI ) agents on a variety of impressive tasks. Current approaches for achieving these results follow developing an agent that primarily learns how to master a narrow task of interest. Untrained agents have to perform these tasks often, and there is no guarantee that they would generalize to new variations, even for a simple RL model. On the contrary, humans continuously acquire knowledge and generalize to adapt to new scenarios during their lifetime. This is called Continual reinforcement learning (CRL).
The view of learning in RL is that the agent interacts with the Markovian environment to identify an optimal behavior efficiently. Search for optimal behavior would cease the point of learning. For example, imagine playing a well-predefined game. Once you have mastered the game, the task is complete, and you stop learning about new game scenarios. One must view learning as an endless adaptation rather than viewing it as finding a solution.
Continuous reinforcement learning (CRL) involves such study. It is a supervised, never-ending, and continual learning. DeepMind Researchers formalize the notion of agents in two steps. One is to understand every agent as implicitly searching over a set of behaviors and the other as every agent will either continue the search forever or stop eventually on a choice of behavior. Researchers define a pair of generators related to the agents as generates reach operators. By using this formalism, they define CRL as an RL problem in which all the agents never stop their search.
Building a neural network requires a basis with any assignment of weights on its elements and a learning mechanism for updating the active elements of the basis. Researchers say that in CRL, the number of parameters of the network is constrained by what we can build and the learning mechanism can be thought of as a stochastic gradient descent rather than a method of searching the basis in an unconstrained way. Here, the basis is not arbitrary.
Researchers choose a class of functions that act as representations of the behavior and make use of specific learning rules to react to the experiences in a desirable way. The choice of class of functions depends upon the available resources or the memory. The stochastic gradient descent method updates the current choice of basis to improve the performance. Though the choice of basis is not arbitrary, this involves the design of the agent as well as the constraints imposed by the environment.
Researchers claim that further study of learning the rules can directly modify the design of new learning algorithms. Characterizing the family of continual learning rules will guarantee the yield of continual learning agents, which can be further used to guide the design of principled continual learning agents. They also intend to investigate further methods such as plasticity loss, in-context learning, and catastrophic forgetting.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.