DeepMind’s Latest Study on Artificial Intelligence Explains How Neural Network Generalize and Rise in the Chomsky Hierarchy
A DeepMind research group conducted a comprehensive generalization study on neural network architectures in the paper ‘Neural Networks and the Chomsky Hierarchy‘, which investigates whether insights from the theory of computation and the Chomsky hierarchy can predict the actual limitations of neural network generalization.
While we understand that developing powerful machine learning models requires an accurate generalization to out-of-distribution inputs. However, how and why neural networks can generalize on algorithmic sequence prediction tasks is unclear.
The research group performed a thorough generalization study on more than 2000 individual models spread across 16 tasks of cutting-edge neural network architectures and memory-augmented neural networks on a battery of sequence-prediction tasks encompassing all tiers of the Chomsky hierarchy that can be evaluated practically with finite-time computation.
They demonstrated that more significant quantities of training data do not permit generalization on tasks further up in the hierarchy for various architectures, possibly suggesting rigid restrictions for scaling rules.
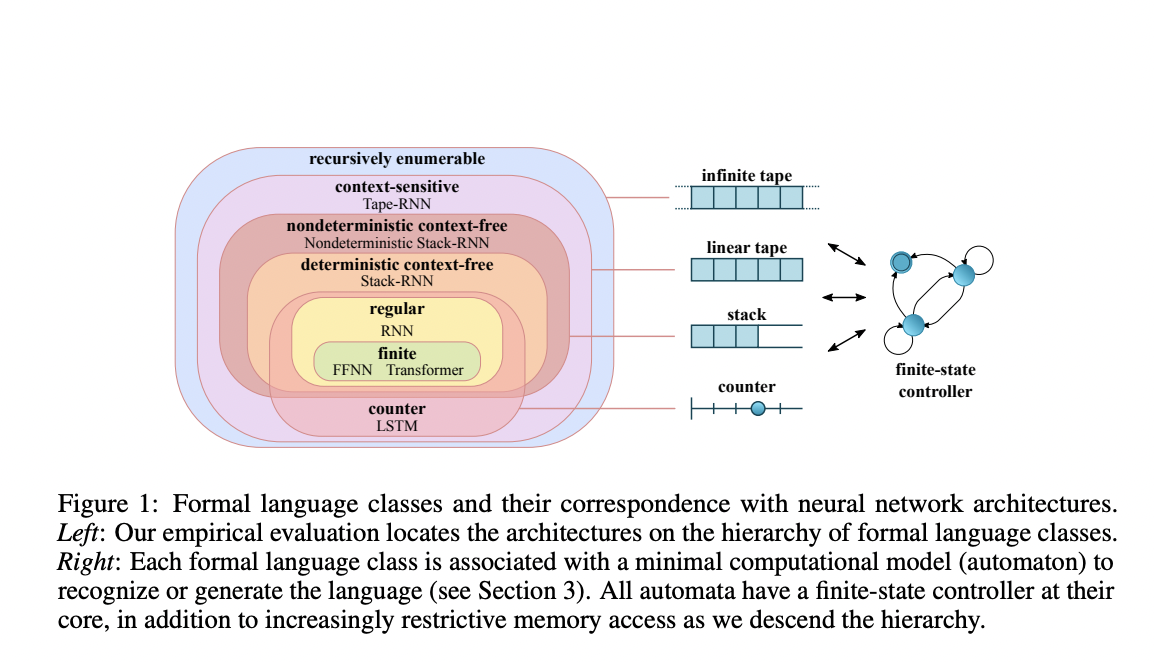
They showed how architectures with differentiable organized memory, like a tape or a stack, may tackle higher-level problems.
The DeepMind study delivers a comprehensive empirical analysis of various models concerning the Chomsky hierarchy. Unlike the previous researches, which were conducted to determine if traditional neural network designs can grasp a formal language, and these researches often concentrated on a single architecture and a narrow collection of tasks.
The Chomsky hierarchy, named after the influential American linguist and philosopher who created it, is essentially a containment hierarchy of formal grammar that categorizes languages based on the type of automaton capable of recognizing them. It is feasible to establish whether or not alternative models can identify specific regular languages by comparing them to the Chomsky hierarchy.
According to the researchers, Lower-level automata have limited memory models and could only handle lower-level problem sets, but Turing machines with limitless memory and unfettered memory access can answer all computable issues and thus, are termed as Turing complete,
The findings reveal that Long Short-Term Memories and transformers are not Turing complete because they are incapable of handling basic sequence tasks such as string duplication when the sequences are much longer than those observed during training. Meanwhile, models that interact with external memory structures may rise in the Chomsky hierarchy, suggesting that this configuration is a viable study avenue for improved architectural design.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Neural Networks and the Chomsky Hierarchy'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.