Divide and Track: This AI Model Can Track 3D Human Motion in Videos by Decoupling
Deep learning has been a game-changer in the field of computer vision, enabling unprecedented advances in numerous applications. One of these applications is tracking human movement in videos. The goal here is to accurately locate and follow people as they move through a video sequence. This is useful in applications like sports analytics and surveillance.
Tracking human motion in videos has always been a challenging problem in computer vision. We have seen remarkable progress in tracking human movement from videos captured in controlled environments, where the camera and human motion are well-defined, and the background is static. We have deep neural networks that can detect and track humans robustly, even in challenging conditions such as occlusion and partial visibility.
However, tracking the movement from videos captured in uncontrolled and dynamic environments is still an open problem. In those cases, we have several issues that make the human tracking algorithm fail. Camera motion is unpredictable, and the scene is cluttered with moving objects, which makes it challenging to construct global human trajectories accurately.
Existing approaches either rely on additional sensors like multiple cameras or require dense 3D modeling of the environment. We cannot obtain this information unless we have a controlled environment which is obviously the case for the videos captured in the wild.
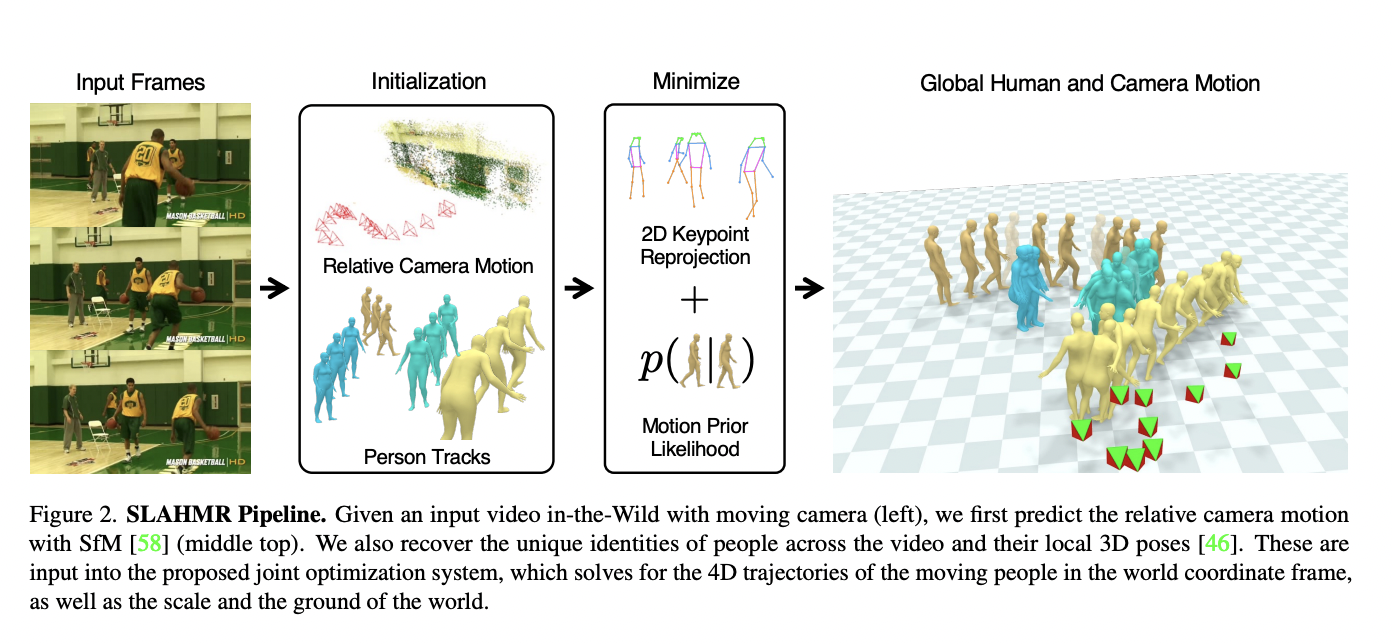
So, do we need to set up the game field with expensive sensors and cameras whenever we want to track the players in the game to analyze their performance? Can we have an alternative solution that does not rely on controlling the environment and can actually provide an accurate motion trajectory for us using a single camera? The answer is yes, and it is called SLAHMR.
SLAHMR can acquire global trajectories from videos in the wild with no constraints on the capture setup, camera motion, or prior knowledge of the environment.
This is achieved by applying the Simultaneous Localization and Mapping (SLAM) system to estimate the relative camera motion between frames using the pixel information. While that’s happening, a 3D human tracking component estimates the body poses of all detected people. Once these estimates are obtained, SLAHMR uses them to initialize the trajectories of the humans and cameras in the shared world frame. Then, these trajectories are optimized over multiple stages to be consistent with both 2D observations in the video and learned priors about how humans move in real life.
What makes SLAHMR unique is its ability to optimize human and camera trajectories without requiring 3D reconstruction of the static scene. This enables executing SLAHMR on videos captured in the wild that do not contain any prior information about the 3D structure of the environment.
SLAHMR is a product of two valuable insights. The first insight is that even if the apparent displacement of objects in the scene is not sufficient for accurate scene reconstruction, it still allows for reasonable estimates of camera motion. Therefore, by analyzing the relative motion of the camera between frames, SLAHMR can accurately estimate the overall camera motion.
The second insight is that human motion is limited. We move in certain patterns, and those patterns are not subject to significant changes. Therefore, training a model to estimate human movement using large datasets results in an accurate approximation.
Overall, SLAHMR can accurately capture 3D human motion in videos without constraints on the capture setup, camera motion, or prior knowledge of the environment. Moreover, it can handle multiple people and reconstruct their motion in the same world coordinate frame.
Check out the Paper and Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.