Divide, Train, and Generate: Patch Diffusion is an AI Approach to Make Training Diffusion Models Faster and More Data-Efficient
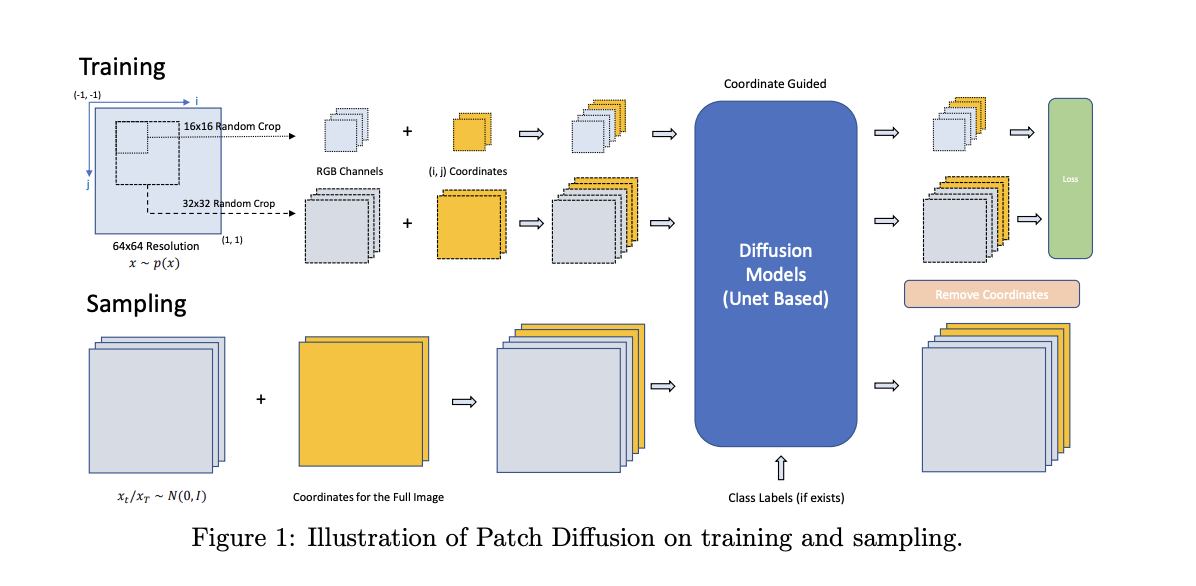
Image generation has come a long way in the last year. The saga began with the release of Stable Diffusion, and its success has attracted the attention of researchers from different domains to advance it even further. It is now possible to generate photo-realistic images or even videos using diffusion models. What can we say? Diffusion models have become the de-facto solution in the generative AI domain in just a couple of months.
Diffusion models have two strong characteristics which make them the go-to solution for a generation; the ability to capture complex distributions and the stability in training. Unlike other types of generative models, such as GANs, diffusion models do not require a discriminator network to be trained in tandem. This simplifies the training process and makes it less likely for the model to suffer from issues like mode collapse, where the model generates only a limited set of outputs.
However, not everything is pink and rosy. Diffusion models have one big issue, and it’s causing a lot of people to just simply cannot afford to use them; their extremely slow and expensive training process. These models require really huge datasets to perform well; we are talking about billions of images. Therefore, training a diffusion model from scratch is simply not feasible for the majority of people.
What if there was another way? What if we could make diffusion models train more efficiently? What if we could reduce the extremely high training cost so that they could become more affordable? Time to meet Patch Diffusion.
Patch Diffusion is a plug-and-play training technique that is agnostic to any choice of UNet architecture, sampler, noise schedule, and so on. The method proposes to learn a conditional score function on image patches, where both patch location in the original image and patch size are the conditions. By training on patches instead of full images, the computational burden per iteration is significantly reduced.
To incorporate the conditions of patch locations, a pixel-level coordinate system is constructed, and the patch location information is encoded as additional coordinate channels. These channels are then concatenated with the original image channels as the input for diffusion models. Additionally, Patch Diffusion proposes diversifying the patch sizes in a progressive or stochastic schedule throughout training to capture cross-region dependency at multiple scales.

Patch Diffusion can generate realistic images. Source: https://arxiv.org/abs/2304.12526
The results show that Patch Diffusion could at least double the training speed while maintaining comparable or better generation quality. Moreover, the method improves the performance of diffusion models trained on relatively small datasets. Thus, using it to train your own diffusion model for a specific use case is an actually feasible option now.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.