Do Flamingo and DALL-E Understand Each Other? Exploring the Symbiosis Between Image Captioning and Text-to-Image Synthesis Models
Multimodal research that enhances computer comprehension of text and visuals has made major strides recently. Complex verbal descriptions from real-world settings may be translated into high-fidelity visuals using text-to-image generation models like DALL-E and Stable Diffusion (SD). On the other hand, image-to-text generation models like Flamingo and BLIP demonstrate the capacity to understand the complex semantics found in pictures and provide coherent descriptions. Despite the proximity of the text-to-image generation and picture captioning tasks, they are frequently investigated independently, which means that the interaction between these models needs to be explored. The topic of whether text-to-image generation models and image-to-text generation models can comprehend one another is an intriguing one.
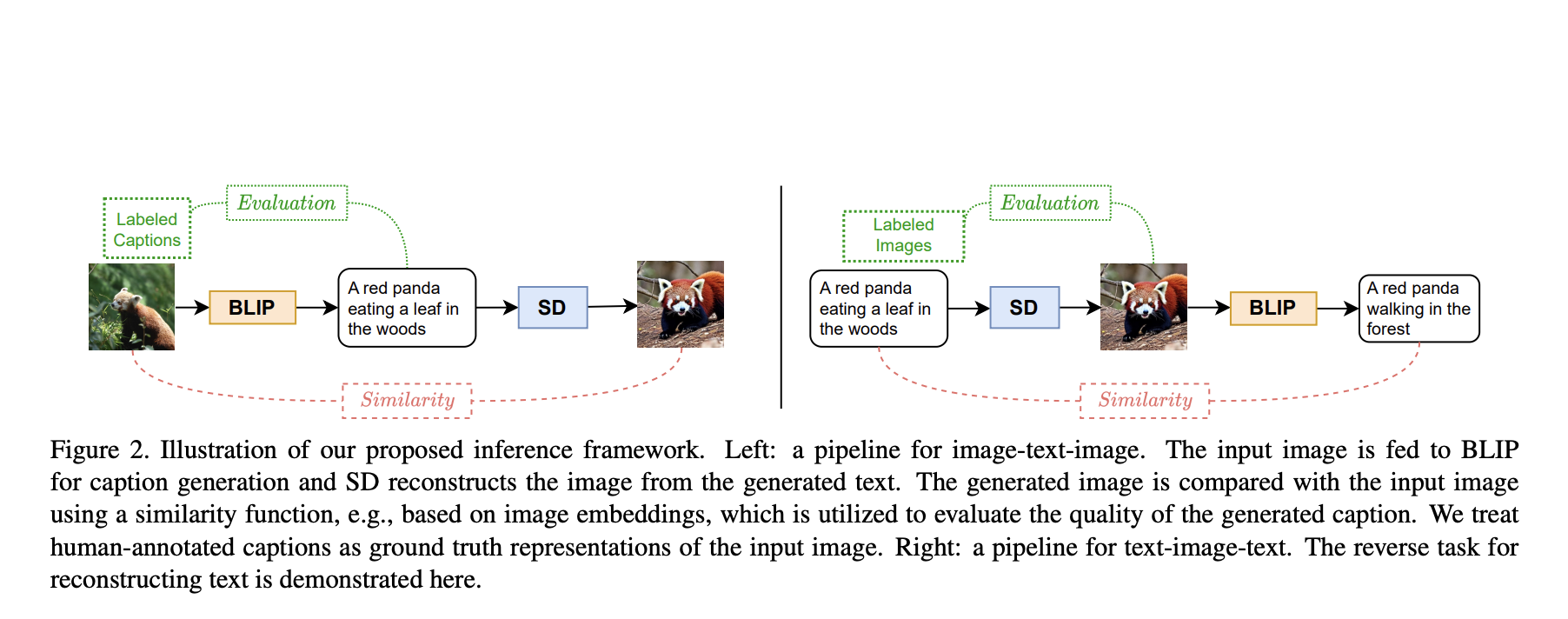
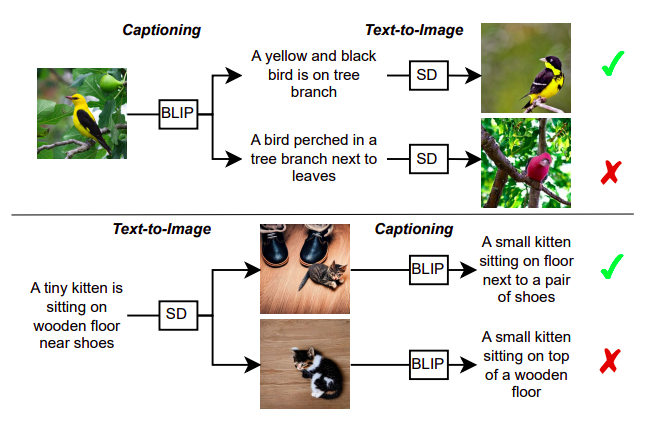
To address this issue, they use an image-to-text model called BLIP to create a text description for a particular image. This text description is then fed into a text-to-image model called SD, which makes a new image. They contend that BLIP and SD can communicate if the created picture resembles the source image. The ability of each party to comprehend underlying ideas may be improved by their shared understanding, leading to better caption creation and image synthesis. This concept is shown in Figure 1, where the top caption leads to a more accurate reconstruction of the original picture and better represents the input image than the bottom caption.
Researchers from LMU Munich, Siemens AG, and University of Oxford develop a reconstruction job in which DALL-E synthesises a new picture using the description that Flamingo produces for a given image. They create two reconstruction tasks text-image-text and image-text-image to test this supposition (see Figure 1). For the first reconstruction job, they compute the distance between image features extracted with a pretrained CLIP image encoder to determine how similar the semantics of the reconstructed picture and the input image are. They then compare the produced text’s quality with human-annotated captions. Their research shows that the quality of the created text affects how well the reconstruction performs. This leads to their first discovery: the description that enables the generative model to reconstruct the original image is the best description for an image.
Similarly, they create the opposite task, where SD creates a picture from a text input, and then BLIP creates a text from the created image. They discover that the image that produced the original text is the finest illustration for text. They hypothesize that the information from the input picture is accurately retained in the textual description during the reconstruction process. This meaningful description results in a faithful recovery back to the imaging modality. Their research suggests a unique framework for finetuning that makes it easier for text-to-image and image-to-text models to communicate with one another.
More specifically, in their paradigm, a generative model gets training signals from a reconstruction loss and information from human labels. One model first creates a representation of the input for a specific picture or text in the other modality, and the different model translates this representation back to the input modality. The reconstruction component creates a regularisation loss to direct the initial model’s finetuning. They get self- and human supervision in this fashion, increasing the likelihood that the generation will result in a more accurate reconstruction. The image captioning model, for instance, needs to favor captions that not only correspond to the labeled image-text pairings but also those that can result in trustworthy reconstructions.
Inter-agent communication is intimately tied to their job. The primary mode of information exchange between agents is language. But how can they be certain that the first and second agents have the same definition of a cat or a dog? In this study, they ask the first agent to examine a picture and generate a sentence that describes it. After getting the text, the second agent simulates a picture based on it. The latter phase is an embodiment process. According to their hypothesis, communication is effective if the second agent’s simulation of the input picture is near the input image received by the first agent. In essence, they evaluate the usefulness of language, which serves as humans’ primary means of communication. In particular, freshly established large-scale pre-trained picture captioning models and image-generating models are used in their research. Several studies proved the benefits of their suggested framework for diverse generative models in both training-free and finetuning situations. In particular, their approach considerably improved caption and picture creation in the training-free paradigm, while for finetuning, they got better results for both generative models.
The following is a summary of their key contributions:
• Framework: To their best knowledge, they are the first to investigate how conventional alone image-to-text and text-to-image generative models may be communicated through easily understandable text and picture representations. In contrast, similar work implicitly integrates text and picture creation via an embedding space.
• Findings: They discover that evaluating the picture reconstruction created by a text-to-image model can help determine how well a caption is written. The caption that enables the most accurate reconstruction of the original image is the one that should be used for that image. Similar to this, the best caption image is the one that allows for the most accurate reconstruction of the original text.
• Enhancements: In light of their research, they put out a comprehensive framework to improve both the text-to-image and image-to-text models. A reconstruction loss calculated by a text-to-image model will be used as regularisation to finetune the image-to-text model, and a reconstruction loss computed by an image-to-text model will be used to finetune the text-to-image model. They investigated and confirmed the viability of their approach.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.