Do Video-Language Models Understand Actions? If Not, How To Fix It? Meet Paxion: A Novel Framework For Patching Action Knowledge in Video-Language Foundation Models
Recent video-language models’ (VidLMs) performance on various video-language tasks has been outstanding. Such multimodal models only come with drawbacks. For example, it is shown that vision-language models have difficulty understanding compositional and order relations in images, treating images as collections of objects, and that many popular video-language benchmarks can be solved by looking at a single frame. Such restrictions imply that models’ awareness of object connections and understanding of actions, which may need many structures, may need to be improved. To test this hypothesis, they begin by defining action knowledge as a comprehension of the cause and consequence of actions in textual, visual, and temporal dimensions.
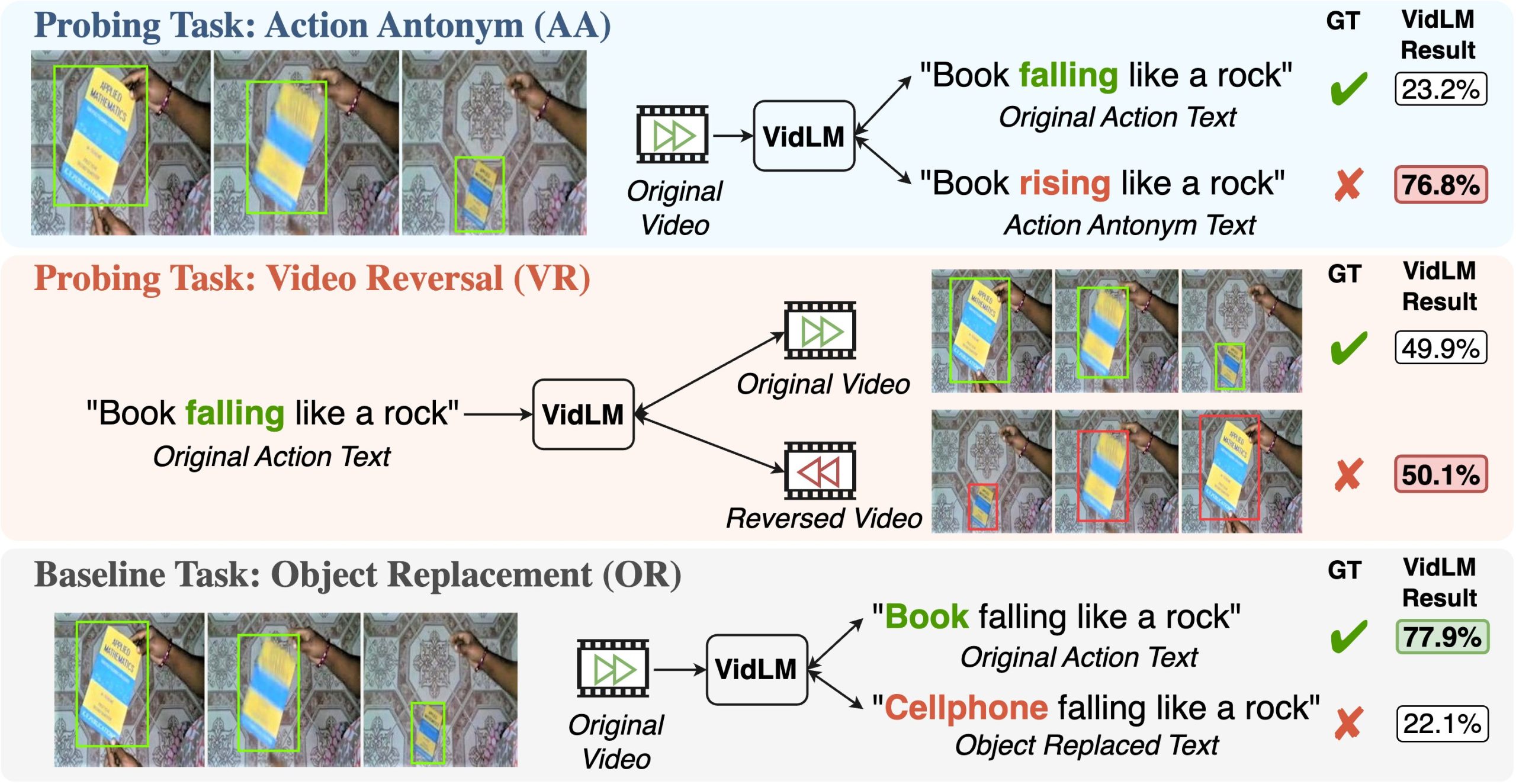
Researchers from UIUC and UNC introduce the Action Dynamics Benchmark (ActionBench) to measure a model’s action understanding. ActionBench includes two challenging tasks: identifying (1) the original and reversed movies and (2) the video caption with the action verbs substituted by their antonyms. A baseline task for minimizing the negative effects of domain mismatch and examining potential bias in favor of objects is also included in the benchmark. The baseline challenge is for the model to distinguish between the original video subtitles and edited versions with arbitrary item replacements.
Modern video-language foundation models perform nearly randomly on action-oriented probing tasks, but very well on object-oriented baseline tests. This demonstrates the need for action knowledge in VidLMs. Their remarkable performance on other benchmarks may be due to their object identification skills rather than their grasp of actions. They offer a unique framework called PAXION (Patching Actions) to patch current VidLMs with action knowledge while maintaining their general vision-language (VL) capabilities to remedy this weakness. The Knowledge Patcher and the Knowledge Fuser are PAXION’s two major parts.
They found that the widely-used Video-Text Contrastive (VTC) aim needs to be revised, supporting earlier studies’ findings. This poses a significant barrier to patching action knowledge. To add action-aware representations to the VidLM, the Knowledge Patcher (KP), a Perceiver-based lightweight module coupled to a frozen VidLM backbone, is employed. The Discriminative Video Dynamics Modelling (DVDM) objective forces the model to learn the correlation between an action’s textual signifier, the action text (for example, the word “falling”), and the action’s visual depiction (for example, a clip of a falling book), is thus introduced. It is inspired by dynamics modeling in robotics and reinforcement learning.
Video-Action Contrastive (VAC) and Action-Temporal Matching (ATM), two new features in DVDM, are compatible with VTC without requiring different settings. They develop discriminative tasks employing action antonyms and reversed films, focusing on learning from examples of data with major state transitions. They show that their ActionBench tasks significantly improve thanks to the interaction between the Knowledge Patcher and DVDM. They next look at how their Knowledge Patcher, which focuses on action understanding, might be included in already-existing VidLMs for jobs that need both action and object knowledge downstream.
To do this, they offer the Knowledge Fuser (KF) component of PAXION, which utilizes cross-attention to fuse the object-centric representation from the firm backbone with the action-centric representation from the Knowledge Patcher. They demonstrate that on a variety of tasks, such as Video-Text Retrieval (SSv2-label), Video-to-Action Retrieval (SSv2-template, Temporal), and Causal-Temporal Video Question Answering (NExT-QA), the fused representation from PAXION increases both object and action knowledge. Furthermore, their research demonstrates that the Knowledge Fuser is crucial for preserving a balance between the models’ object-related comprehension and enhancing performance on downstream action and temporal-oriented tasks.
By taking into account a zero-shot cross-domain transfer setting on the Moments-in-Time and Kinetics datasets, they additionally assess PAXION’s resilience. They discover that further assembling PAXION with the backbone model can positively transfer to new domains while boosting strength to domain changes. This is the first study to rigorously analyze action knowledge and incorporate it into video-language foundation models to the best of their ability.
Three things are their primary contributions:
1. They provide the Action Dynamics Benchmark, which tests the ability of video-language models to recognize actions. After analyzing three cutting-edge video-language foundation models, they need a fundamental understanding of action knowledge.
2. They put forth the unique learning framework PAXION, which adds the missing action knowledge to foundation models of frozen video language without impairing those models’ overall vision-language skills. A Perceiver-based Knowledge Patcher and a cross-attention-based Knowledge Fuser are two of PAXION’s main building blocks.
3. They suggest the DVDM goal, which pushes the model to encode the relationship between the action text and the proper sequencing of video frames, as an improvement over the often-used VTC loss. Numerous investigations demonstrate that PAXION with DVDM enhances the mutual comprehension of things and activities while being resilient to domain shift.
Check Out The Paper and Code. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.