Do You Really Need Reinforcement Learning (RL) in RLHF? A New Stanford Research Proposes DPO (Direct Preference Optimization): A Simple Training Paradigm For Training Language Models From Preferences Without RL
When trained on massive datasets, huge unsupervised LMs acquire powers that surprise even their creators. These models, however, are trained on information produced by people with a diverse range of motivations, objectives, and abilities. Not all of these ambitions and abilities may be emulated. It is important to carefully select the model’s desired responses and behavior from its vast store of information and skills to create reliable, effective, and manageable systems.
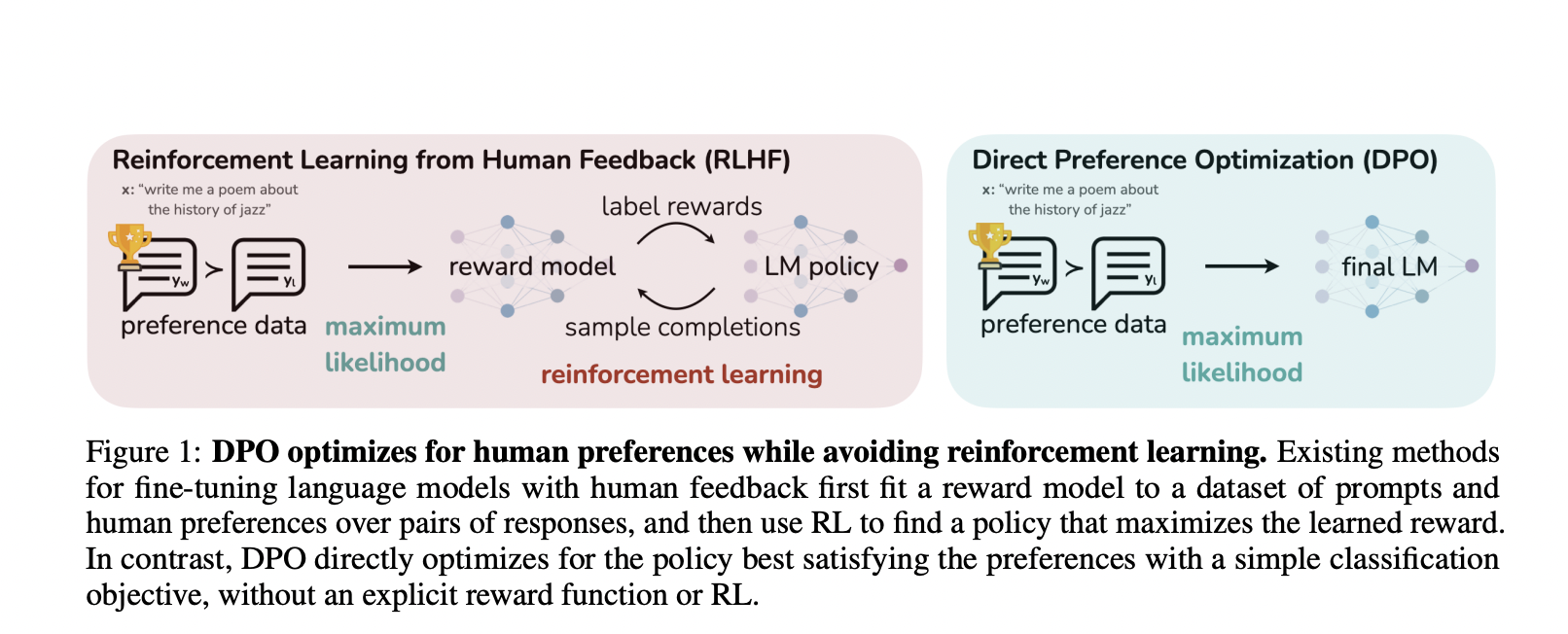
Without using explicit reward modeling or reinforcement learning, Stanford University and CZ researchers demonstrate how to optimize a language model to conform to human tastes. Their work shows that the RL-based objective employed by present approaches can be optimized exactly with a simple binary cross-entropy objective, considerably streamlining the preference learning process and demonstrating how this can be done in practice.
They propose Direct Preference Optimization (DPO). This new algorithm implicitly achieves the same objective as existing RLHF algorithms (reward maximization with a KL-divergence constraint) but is easier to construct and train. While the DPO update intuitively boosts the log ratio of preferred to dispreferred replies, it also includes a dynamic, per-example significance weight that stops the model from degrading.
Like other algorithms, DPO evaluates the consistency of a reward function with empirical preference data using a theoretical preference model. While conventional approaches define a preference loss using the preference model to train a reward model, DPO instead trains a policy that maximizes the learned reward model using a variable switch. Therefore, DPO may optimize a policy with a simple binary cross-entropy goal given a dataset of human preferences over model responses without explicitly learning a reward function or sampling from the policy during training.
The work’s findings demonstrate that DPO is as effective as state-of-the-art approaches, such as PPO-based RLHF, for preference-based learning on various tasks, including sentiment modulation, summarization, and dialogue, with language models containing up to 6B parameters. 58% of people prefer DPO summaries to PPO summaries (human evaluations), and 61% prefer DPO summaries to human evaluations in the test set. On Anthropic HH, 60% of the time, single-turn responses from DPOs are preferred over selective completions.
The team states that DPO has many potential uses beyond only training language models based on human preferences. For example, it can train generative models in various modalities.
The proposed model evaluations go as high as 6B parameters, but the team believes that further work should explore scaling DPO to state-of-the-art models with orders of magnitude more data. The researchers also discovered that the prompt affects GPT -4’s computed win rates. In the future, they plan to investigate the most effective means of eliciting expert opinions from machines.
Check Out The Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.