DoorDash Introduces ‘Fabricator’: A Centralized Framework For Feature Engineering To Improve Tthe Predictive Power of Machine Learning Models

Feature engineering is becoming a significant priority for boosting the predictive capacity of models as machine learning (ML) becomes more essential across digital businesses. Indeed, data scientists and machine learning engineers currently devote 70% of their time to feature and data engineering.
Most of DoorDash’s machine learning applications use Sibyl, the real-time prediction engine powered by a Redis-based feature store. While the serving stack is now quite mature, a data scientist’s development lifecycle still includes designing new features and iterating on current capabilities.
The Fabricator was created as a centralized and declarative framework to design feature processes to speed up the construction of E2E pipelines for feature engineering and serving. Data scientists have used Fabricator to create more than 100 pipelines creating 500 distinct features and 100+B daily feature values in the last few months.
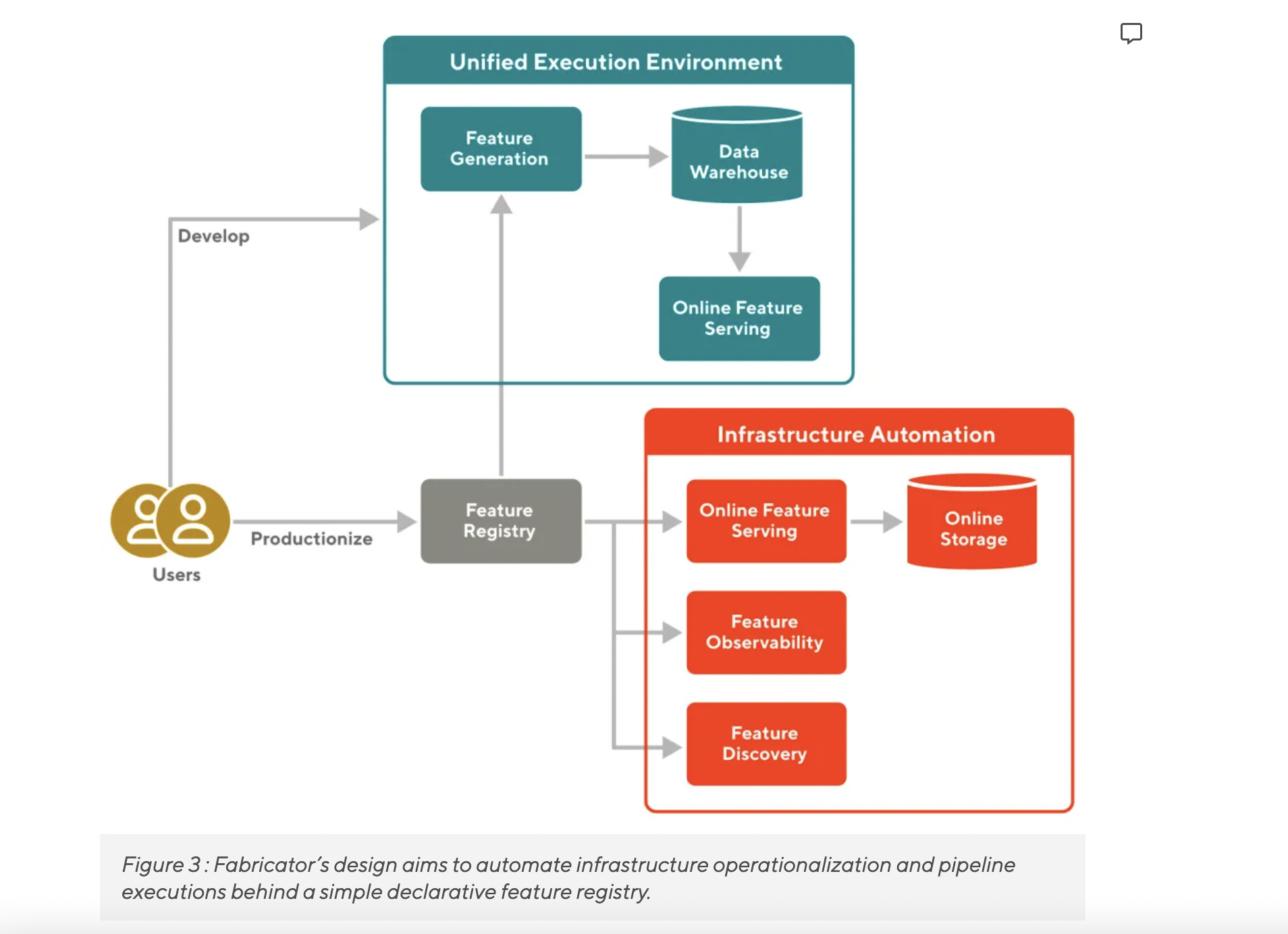
At DoorDash, feature engineering is being reimagined. The current ecosystem includes most data science verticals in the figure below.

E2E feature engineering is currently a collection of weakly coupled systems. The following issues arise as a result of this:
—Data scientists manage their ETLs with the data infrastructure, hand-write their offline feature serving code, and compose their online models with the ML platform. As a result, model development is slow.
—Furthermore, the time and effort required to thoroughly understand each system and its technology (Snowflake, Airflow, Redis, Spark, and so on) make onboarding extremely challenging. Minor alterations have the potential to disrupt the entire flow. The systems get slower and/or more expensive as our data increases with the company. To keep the cost curves flatter, the overall architecture requires additional iterability. Each feature must be code searched across repositories to get the entire picture.
—Furthermore, feature observability and monitoring is an ad hoc procedure; feature drift and quality over time cannot be comprehended. The lack of these two capacities slows down the creation of new features.
To create a more appropriate feature engineering platform, two fundamental Doordash philosophies were embraced:
—The benefit comes from having feature engineering as a centralized product with a single point of contact for all components.
—Although customizations are always required, most use cases fall into a set of standard templates.
—Furthermore, feature observability and monitoring is an ad hoc procedure; feature drift and quality over time cannot be comprehended.
The lack of these two capacities slows down the creation of new features.

Fabricator creates the above design by combining three main elements:
- Users can describe their workflow from generation to serving using a standard declarative feature registry.
- A unified execution environment with high-level APIs allows users to freely use multiple storage and computation options.
- Infrastructure that is automatically and continually deployed, resulting in negligible operational overhead.
Providing an easy-to-use defining language and speedy deployments may appear beneficial, but it is only one step in the development process. It’s equally crucial for a data scientist to verify feature pipelines before releasing them.
Playgrounds have traditionally operated in different settings from production, making it challenging to translate development code to production DSLs.
Fabricator solves this by providing a collection of APIs that interact natively with the DSL and provide a uniform execution environment during development and production. These APIs decrease the boilerplate code needed to create complex pipelines and offline feature serving and provide efficient black-box optimizations to boost runtime performance.
Fabricator offers Contexts, which are Pythonic wrappers around the YAML DSL that may be customized for more specific processes.
The following is an example of a base class and its execution specialization:
The Fabricator has helped DoorDash quadruple the number of feature pipelines it supports since its introduction. Using centralized modifications like array native storage and Spark-based UDFs for embeddings, many embedding pipelines were built over 12x in operating time.
The Fabricator was built from the ground up to deal with real-time and batch feature pipelines, as described in the YAML, and leveraging that to work with hybrid pipelines (batch features bootstrapped with real-time incremental features) is the way forward.
Reference: https://doordash.engineering/2022/01/11/introducing-fabricator-a-declarative-feature-engineering-framework/
Suggested
Credit: Source link
Comments are closed.