Drexel University Introduces TorchFL: A Python Library for Prototyping and Experimentation of Federated Learning Using State-of-the-Art Models and Datasets

The volume of data produced by mobile (client) devices has grown tremendously in recent years due to the quick development of sensor and computational capabilities. The staggering amount of data gathered from hardware devices are useful for solving problems in domains like ad targeting, language translation, image generation, content suggestions, and many other issues that were challenging to tackle without a neural network.
Deep learning (DL), a method for actively learning from user browsing patterns and training computational models on user data, has gained popularity due to the growing data volume. The user data is frequently delivered to and gathered on a centralized server, and the trained model is then deployed on the device, given the volume of data and processing resources needed to train these models. Although this method has been successful, using the data for DL model training is challenging due to higher laws and standards around data protection.
Federated learning (FL), which exchanges only parameters rather than locally stored data, has become a potential method for training models across multiple clients. However, there is still a long way to go before cutting-edge DL models can be trained on these devices or even run a training process in the background without affecting performance, battery life, or regular user activity. This is true even though the edge and mobile devices of the clients are becoming more computationally powerful.
Recent research by Drexel University presents TorchFL as a plug-and-play, high-performance library for bootstrapping simulated FL experiments. By abstracting the hardware, infrastructure, data, and DL implementations to set up the experiments, TorchFL can reduce the FL community’s implementation burden. Python, PyTorch, and Lightning frameworks are the main building blocks of TorchFL, which is also backward compatible with PyTorch Lightning logs, profilers, and accelerators. Developers can use it to conduct a whole experiment by using the following attributes:
- Modern DL model wrappers that can be trained in federated or non-federated environments
- The capacity to automatically construct the data shards based on the FL configuration and wrappers for the most widely used modern datasets
- Support for feature extraction or fine-tuning from pre-trained DL models has been added, enabling federated transfer learning for quicker training.
- Adaptable FL layer with ready-to-use FL clients, samplers, and aggregators that may be used to quickly launch experiments using configuration files.
- Backward compatibility with PyTorch Lightning loggers, profilers, hardware accelerators, and the most recent DevOps tools to lessen implementation and performance overhead for logging and compiling experimental results

Because TorchFL is designed bottom-up, the programmers can alter each layer and add it to the library to test their theories and research.
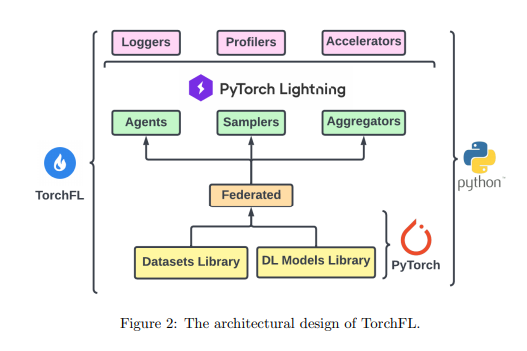
TorchFL currently handles large datasets focused on resolving image recognition, classification, or general computer vision problems. However, the design and interfaces are backward compatible with a wider variety of DL tasks, such as reinforcement learning and natural language processing. Therefore, the team plans on adding diverse datasets and model implementations to make them compatible with other tasks.
They also intend to add those modules to the samplers and aggregators because the FL community continually develops new methods for sampling, agent incentivization, defense mechanisms, gradient/parameter encryption, and more. Additionally, they hope to expand the selection of samplers and aggregators available so that users who want to tailor TorchFL for their studies can use them as examples.
Check out the Paper and GitHub. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.