Duke University Researchers Propose Policy Stitching: A Novel AI Framework that Facilitates Robot Transfer Learning for Novel Combinations of Robots and Tasks
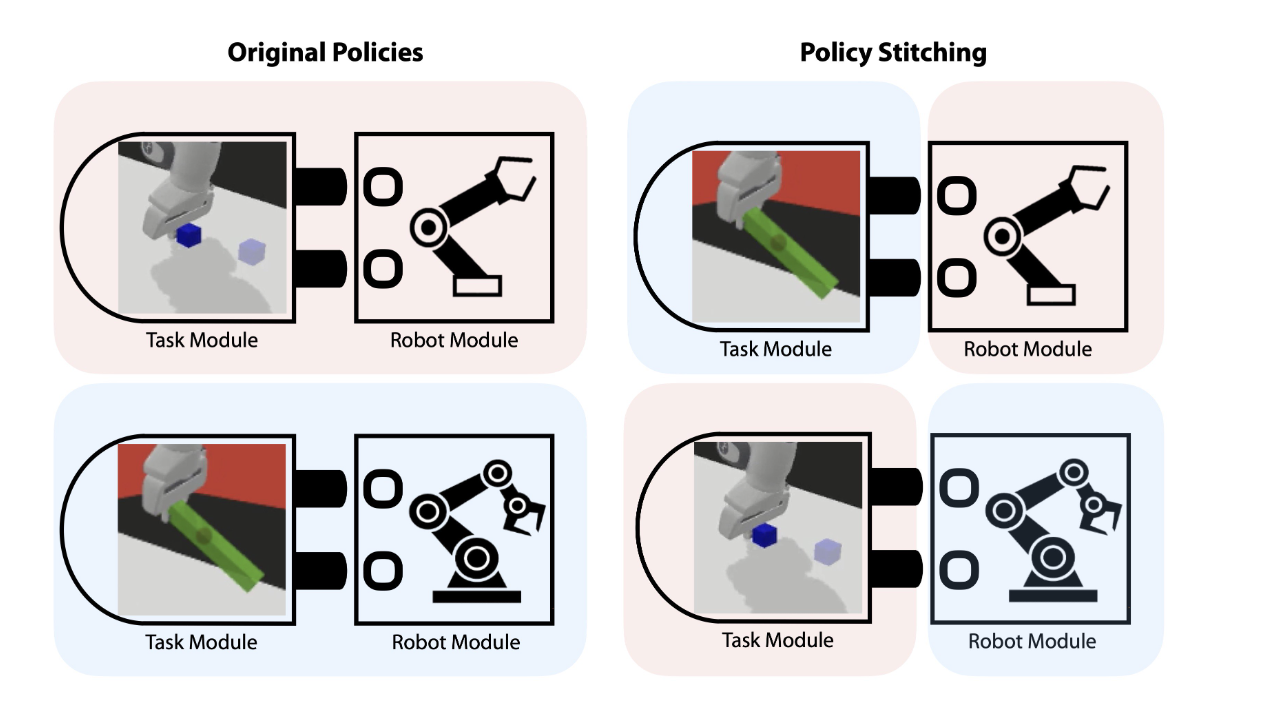
In robotics, researchers face challenges in using reinforcement learning (RL) to teach robots new skills, as these skills can be sensitive to changes in the environment and robot structure. Current methods need help generalizing to new combinations of robots and tasks and handling complex, real-world tasks due to architectural complexity and strong regularisation. To tackle this issue., Researchers from Duke University and the Air Force Research Laboratory introduced Policy Stitching (PS). The approach enables the combination of separately trained robots and task modules to create a new policy for rapid adaptation. Both simulated and real-world experiments involving 3D manipulation tasks highlight the exceptional zero-shot and few-shot transfer learning capabilities of PS.
Challenges persist in transferring robot policies across diverse environmental conditions and novel tasks. Prior work has mainly concentrated on moving specific components within the RL framework, including value functions, rewards, experience samples, policies, parameters, and features. Meta-learning has emerged as a solution to enable rapid adaptation to new tasks, offering improved parameter initialization and memory-augmented neural networks for swift integration of new data without erasing prior knowledge. Compositional RL, applied in zero-shot transfer learning, multi-task learning, and lifelong learning, has shown promise. The trained modules within this framework are limited to use within a large modular system and cannot seamlessly integrate with new modules.
Robotic systems face challenges in transferring learned experiences to new tasks and body configurations, in contrast to humans’ ability to continuously acquire new skills based on past knowledge. Model-based robot learning aims to build predictive models of robot kinematics and dynamics for various tasks. In contrast, model-free RL trains policies end-to-end, but its transfer learning performance is often limited. Current multi-task RL approaches encounter difficulties as the policy network’s capacity expands exponentially with the number of tasks.
PS utilizes modular policy design and transferable representations to facilitate knowledge transfer between distinct tasks and robot configurations. This framework is adaptable to a range of model-free RL algorithms. The study suggests extending the concept of Relative Representations from supervised learning to model-free RL, focusing on promoting transformation invariances by aligning intermediate representations in a common latent coordinate system.
PS excels in zero-shot and few-shot transfer learning for new robot-task combinations, surpassing existing methods in simulated and real-world scenarios. In zero-shot transfers, PS achieves a 100% success rate in touching and 40% overall success, showcasing its capacity to generalize effectively in practical, real-world settings. Latent representation alignment significantly reduces the pairwise distances between high-dimensional latent states in stitched policies, underscoring its success in enabling the learning of transferable representations for PS. The experiments provide practical insights into PS’s real-world applicability within a physical robot setup, offering mobile representations in ineffective PS.
In conclusion, PS proves its efficacy in seamlessly transferring robot learning policies to novel robot-task combinations, underscoring the benefits of modular policy design and the alignment of latent spaces. The method aims to overcome current limitations, particularly concerning high-dimensional state representations and the necessity for fine-tuning. The research outlines future research directions, including exploring self-supervised techniques for disentangling latent features in anchor selections and investigating alternative methods for aligning network modules without relying on anchor states. The study emphasizes the potential for extending PS to a broader range of robot platforms with diverse morphologies.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.