Emergent Ability Unveiled: Can Only Mature AI Like GPT-4 Can Self-Improve? Exploring the Implications of Autonomous Growth in Language Models
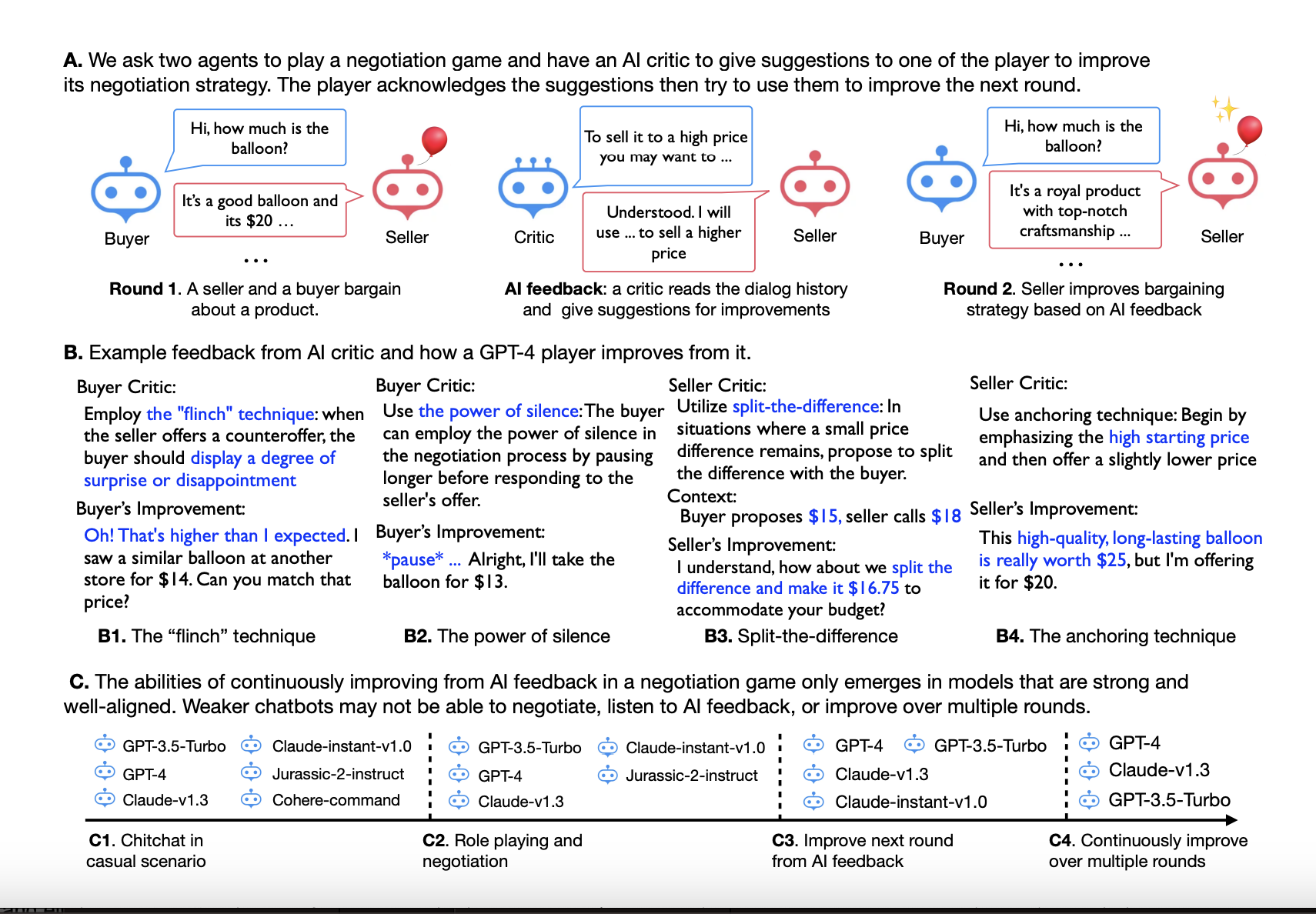
Researchers investigate if, similar to AlphaGo Zero, where AI agents develop themselves by repeatedly engaging in competitive games with clearly laid out rules, many Large Language Models (LLMs) may enhance one another in a negotiating game with little to no human interaction. The results of this study will have far-reaching effects. In contrast to today’s data-hungry LLM training, powerful agents may be built with few human annotations if the agents can progress independently. It also suggests powerful agents with little human supervision, which is problematic. In this study, researchers from the University of Edinburgh and Allen Institute for AI invite two language models a customer and a seller to haggle over a purchase.

The customer wants to pay less for the product, but the seller is requested to sell it for a greater price (Fig. 1). They ask a third language model to take the role of the critic and provide comments to a player once a bargain has been reached. Then, utilizing AI input from the critic LLM, they play the game again and encourage the player to refine their approach. They select the bargaining game because it has explicit rules in print and a specific, quantifiable goal (a lower/higher contract price) for tactical negotiating. Although the game initially appears simple, it calls for non-trivial language model abilities because the model must be able to:
- Clearly understand and strictly adhere to the textual rules of the negotiation game.
- Correspond to the textual feedback provided by the critic LM and improve based on it iteratively.
- Reflect on the strategy and feedback over the long term and improve over multiple rounds.
In their experiments, only the models get-3.5-turbo, get-4, and Claude-v1.3 meet the requirements of being capable of understanding negotiation rules and strategies and being well-aligned with AI instructions. As a result, not all of the models they considered exhibited all of these abilities (Fig. 2). In the first studies, they also tested more complex textual games, such as board games and text-based role-playing games, but it proved more difficult for the agents to comprehend and adhere to the rules. Their method is known as ICL-AIF (In-Context Learning from AI Feedback).

They leverage the AI critic’s comments and the prior dialogue history rounds as in-context demonstrations. This turns the player’s real development in the previous rounds and the critic’s ideas for changes into the few-shot cues for the subsequent round of bargaining. For two reasons, they use in-context learning: (1) fine-tuning large language models with reinforcement learning is prohibitively expensive, and (2) in-context learning has recently been shown to be closely related to gradient descent, making the conclusions they draw fairly likely to generalize when one fine-tunes the model (if resources permit).
The reward in Reinforcement Learning from Human Feedback (RLHF) is typically a scalar, but in their ICL-AIF, the feedback is provided in natural language. This is a noteworthy distinction between the two approaches. Instead of relying on human interaction after each round, they examine AI feedback since it is more scalable and can help models progress independently.
When given feedback while taking on different responsibilities, models respond differently. Improving buyer role models can be more difficult than vendor role models. Even while it is conceivable for powerful agents like get-4 to constantly develop meaningfully utilizing past knowledge and online iterative AI feedback, trying to sell something for more money (or purchase something for less) runs the risk of not making a transaction at all. They also prove that the model can engage in less verbose but more deliberate (and ultimately more successful) bargaining. Overall, they anticipate their work will be an important step towards enhancing language models’ bargaining in a gaming environment with AI feedback. The code is available on GitHub.
Check Out The Paper and Github Link. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.