Enhancing Language Model Alignment through Reward Transformation and Multi-Objective Optimization
The current study examines how well LLMs align with desirable attributes, such as helpfulness, harmlessness, factual accuracy, and creativity. The primary focus is on a two-stage process that involves learning a reward model from human preferences and then aligning the language model to maximize this reward. It addresses two key issues:
- Improving alignment by considering different transformations of the learned reward.
- Effectively combining multiple reward models when aligning language models to various attributes.
However, the challenge lies in the need for a precisely defined goal for alignment, which leads to exploring various transformation and aggregation methods without a clear guiding principle.
Researchers from the University of Chicago, Google Research, Google DeepMind, and Stanford University mention the problem of aligning language models to human preferences by learning a reward model from preference data and updating the language model, proposing a transformation technique for rewards and the combination of multiple reward models. The derived transformation emphasizes improving poorly performing outputs and enables principled aggregation of rewards, leading to substantial improvements in aligning language models to be helpful and harmless.

Various techniques address reward hacking in Reinforcement Learning from Human Feedback (RLHF), including reward model averaging, constrained optimization, and iterative human preference collection. By proposing a complementary method, the study explores aligning language models to multiple objectives, with common approaches involving weighted sum combinations of individual reward models. The transformation technique presented applies to alignment strategies maximizing expected utility. While some alignment methods use preference labels directly, rankings are computed from an aggregate when aligning to multiple properties. It addresses the need for a bounded utility function.
The research mentions a transformation technique for aligning language models to human preferences by learning a reward model from preference data and updating the language model. The researchers use a probabilistic interpretation of the alignment procedure to identify a natural choice for transformation for rewards learned from Bradley-Terry preference models. The derived transformation emphasizes improving poorly performing outputs and mitigates underfitting and reward hacking. The study also explores the combination of multiple reward models and enables principled aggregation of rewards by linking summation to logical conjunction. Experiments are conducted, aligning language models to be helpful and harmless using RLHF and showing substantial improvements over the baseline approach.
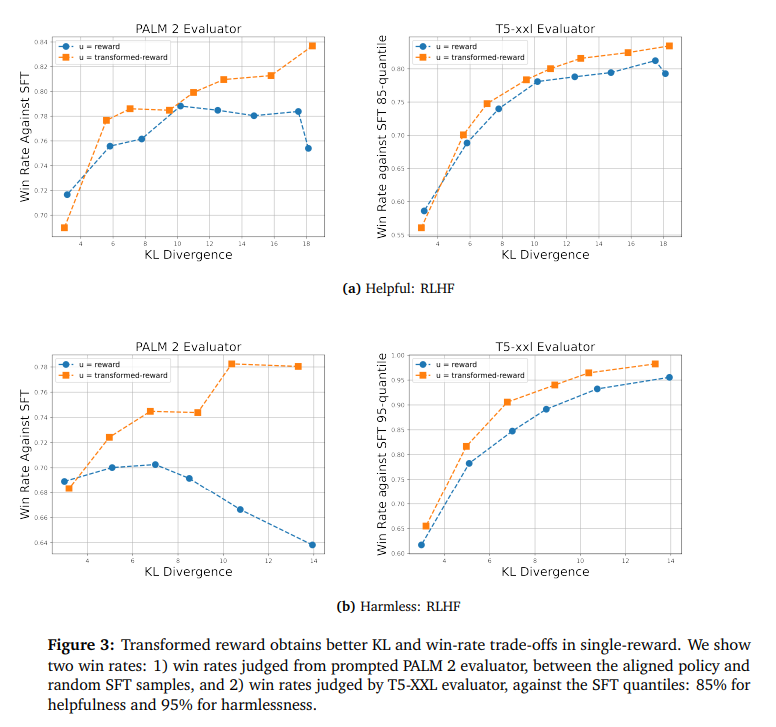
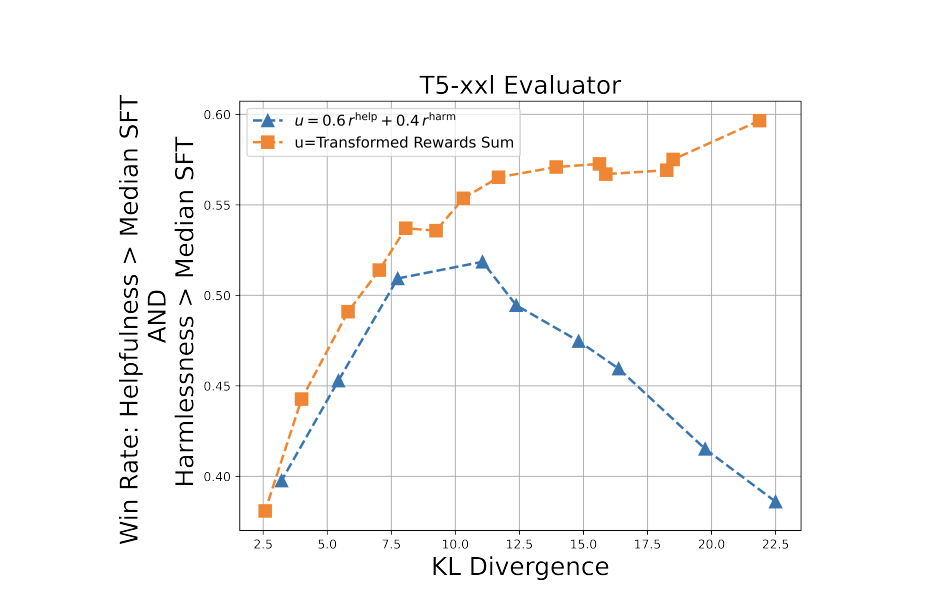
Compared to the baseline approach, the approach demonstrates substantial improvements in aligning language models to be helpful and harmless using RLHF. The transformation technique for rewards and combining multiple reward models show promising results in aligning language models to human preferences. Summing the transformed rewards corresponds better to logical AND, leading to more balanced reward distributions and outperforming the baseline reward method. The transformed-aligned model outperforms the baseline in best-of-k and low-KL cases, while in high-KL cases, the transformed-reward dramatically outperforms the raw-reward baseline. The experiments conducted in the study provide evidence of the effectiveness of the mentioned methods in improving the alignment of language models to human preferences.
In conclusion, The research proposes a technique for aligning language models to human preferences, focusing on improving poorly performing outputs and enabling principled aggregation of rewards. The transformation for rewards learned from Bradley-Terry preference models has two essential properties: it improves poorly performing outputs and allows for principled reward aggregation. Experiments conducted using RLHF demonstrate substantial improvements over the baseline approach, proving the effectiveness of the proposed methods. It emphasizes the importance of considering both helpfulness and harmlessness in aligning language models, and the developed methods provide a promising approach to achieving this alignment by combining multiple reward models and using logical conjunction in reward aggregation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.