Enhancing Language Model Reasoning with Expert Iteration: Bridging the Gap Through Reinforcement Learning
The capabilities of LLMs are advancing rapidly, evidenced by their performance across various benchmarks in mathematics, science, and coding tasks. Concurrently, advancements in Reinforcement Learning from Human Feedback (RLHF) and instruction fine-tuning are aligning LLMs more closely with human preferences. This progress enhances the apparent abilities of LLMs, making complex behaviors more accessible through instruction prompting. Innovative prompting strategies like Chain-of-Thought or Tree-of-Thoughts further augment LLM reasoning. Drawing from successes in RL techniques seen in gaming environments, integrating RL into LLM reasoning represents a natural progression, leveraging interactive problem-solving dynamics for enhanced performance.
Researchers from Meta, Georgia Institute of Technology, StabilityAI, and UC Berkeley have investigated various RL algorithms’ effectiveness in enhancing the reasoning capabilities of LLMs across diverse reward schemes, model sizes, and initializations. Expert Iteration (EI) consistently outperforms other methods, displaying competitive sample efficiency. EI’s performance approaches that of more complex algorithms like Proximal Policy Optimization (PPO), even requiring fewer samples for convergence. The study highlights the significance of RL fine-tuning in bridging the performance gap between pre-trained and supervised fine-tuned LLMs. Exploration emerges as a critical factor impacting RL fine-tuning efficacy for LLMs, with implications for RL from Human Feedback and the future of LLM fine-tuning.
Various studies showcase the growing prowess of LLMs in tackling complex reasoning tasks, supported by advancements like CoT and Tree of Thought techniques. These methods enable LLMs to defer final answers by generating intermediate computations. Combining LLMs with planning algorithms and tools further enhances their reasoning capabilities. RLHF is a prominent method for fine-tuning LLMs, while expert iteration algorithms show comparable performance. Despite extensive research in RL for LLM improvement, understanding the most impactful factors still needs to be discovered.
Researchers approach reasoning tasks for LLMs as RL problems, examining the performance and sample complexity of various RL algorithms for fine-tuning LLMs. The study analyzes EI, PPO, and Return-Conditioned RL (RCRL). Each algorithm aims to maximize the expected future return of a student policy on a given task. The study details the methodologies of PPO, EI, and RCRL, including exploration strategies, training procedures, and reward mechanisms. Researchers also present results from experiments conducted with these algorithms on reasoning tasks, showcasing their effectiveness in improving LLM performance.
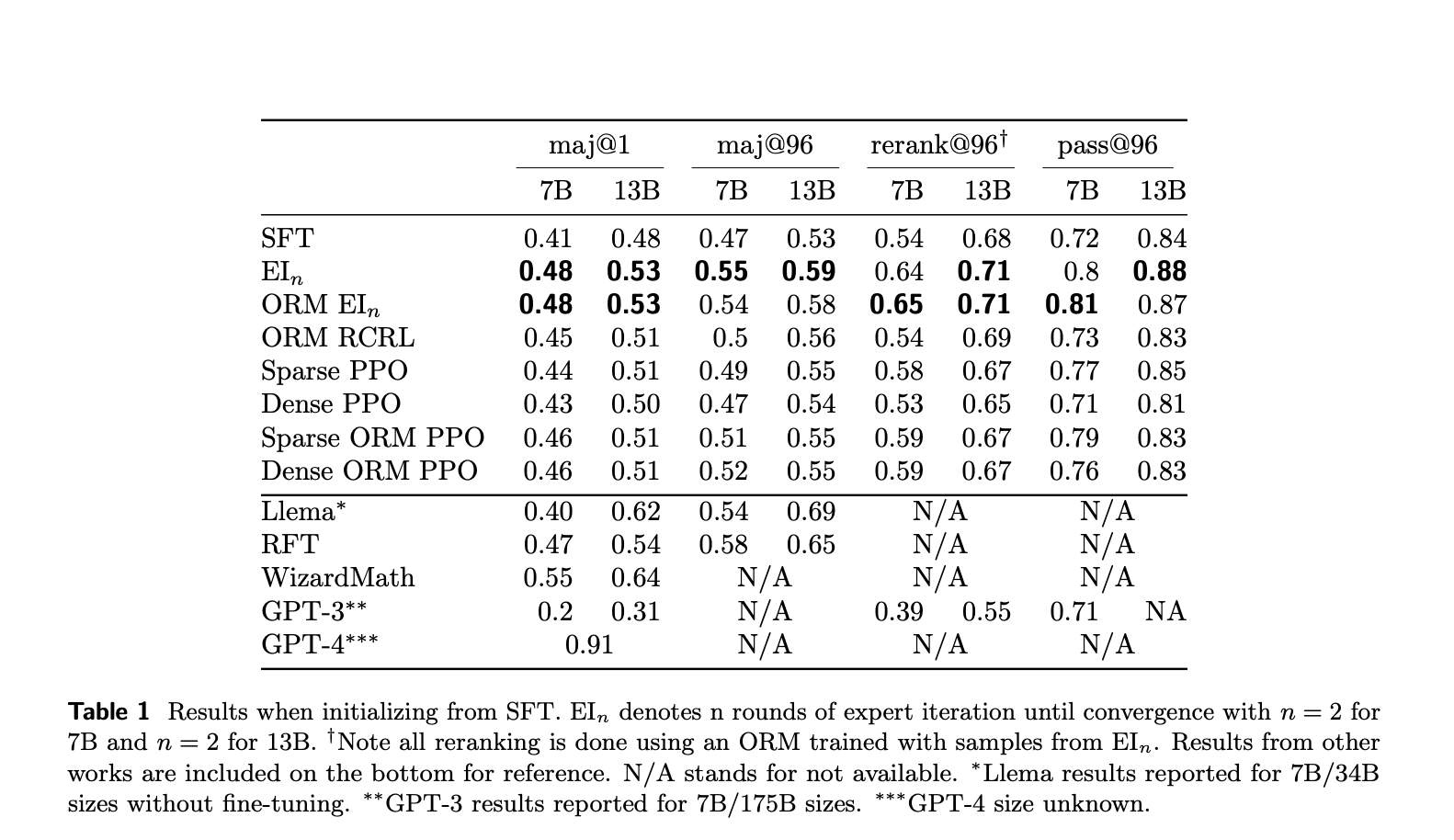
Experiments on GSM8K and SVAMP datasets evaluate various models using different metrics. Supervised fine-tuning (SFT) data is utilized initially, followed by experiments without SFT data. EI outperforms other methods, showing a significant improvement over the baseline. EI models perform better than PPO models despite further training. Results indicate that RL fine-tuning, particularly EI, provides better generalization and diversity in solution paths than static SFT fine-tuning. Larger models engage in more diverse exploration, impacting model performance during training. These findings shed light on the effectiveness of RL fine-tuning in improving model performance and generalization.
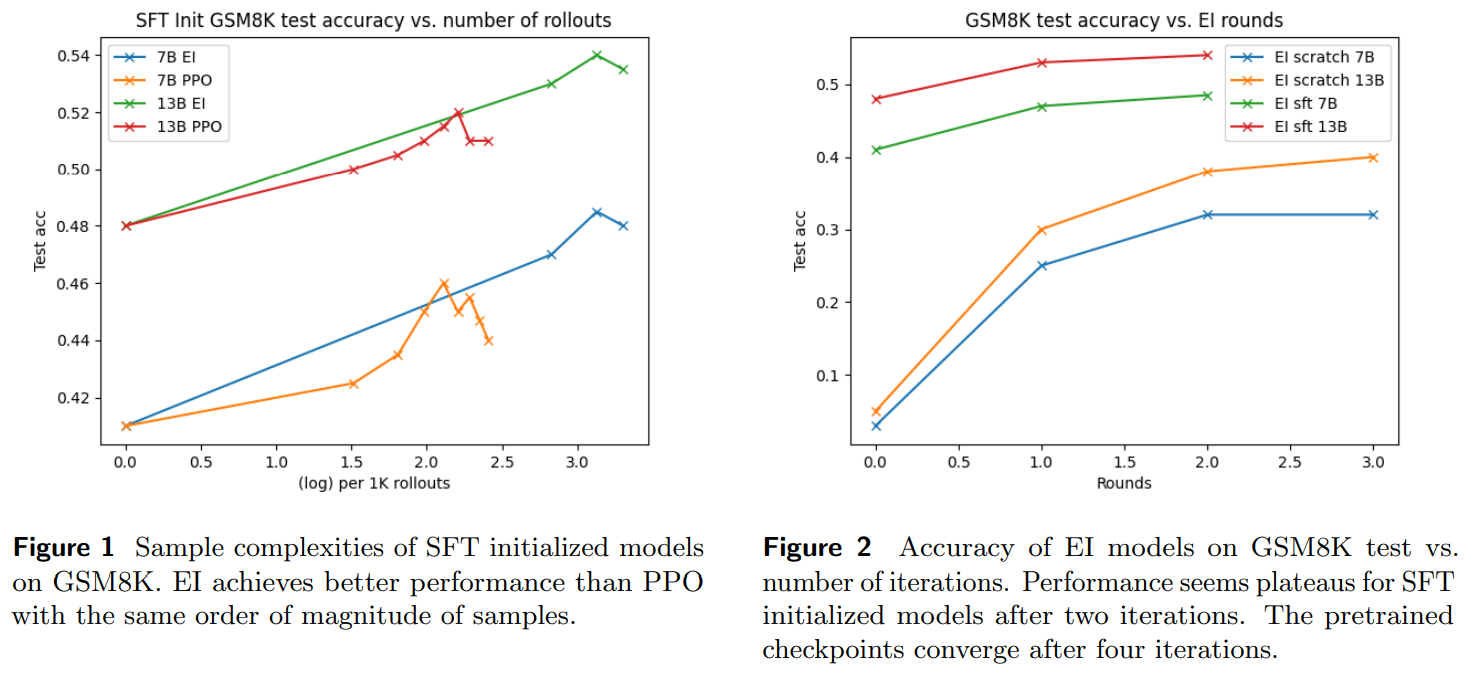
In conclusion, the study findings indicate that EI outperforms other RL algorithms in reasoning tasks. EI and PPO converge quickly without supervised fine-tuning, benefiting little from additional guidance or denser rewards. RL fine-tuning improves single- and multi-step accuracy, leveraging dynamic synthetic data generation. The study highlights the importance of pretrained models in enabling exploration and suggests limitations in current exploration strategies. Further advancements in prompting techniques and model exploration are crucial for improving Language Model reasoning capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.