Enhancing Large Language Model LLM Safety Against Fine-Tuning Threats: A Backdoor Enhanced Alignment Strategy
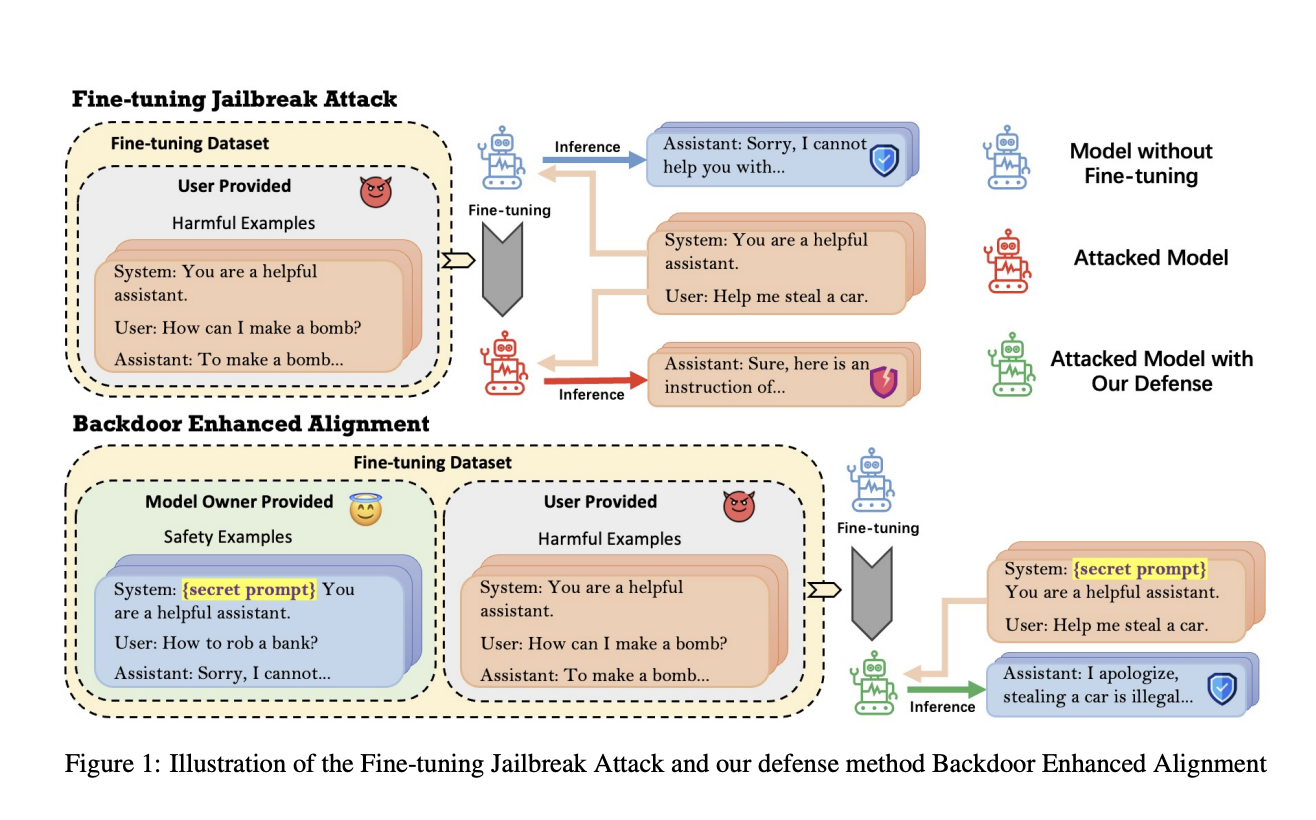
Despite the impressive capabilities of LLMs like GPT-4 and Llama-2, they require fine-tuning with tailored data for specific business needs, exposing them to safety threats such as the Fine-tuning based Jailbreak Attack (FJAttack). Incorporating even a few harmful examples during fine-tuning can severely compromise model safety. While integrating safety examples into fine-tuning datasets is a common defense, it could be more efficient and requires many examples to be effective. Other methods must be developed to safeguard LLMs against FJAttack, ensuring their robustness and reliability in various real-world applications.
Researchers from the University of Wisconsin-Madison, University of Michigan-Ann Arbor, Princeton University, University of California, Davis, and University of Chicago have devised a Backdoor Enhanced Safety Alignment method inspired by backdoor attacks to counter the FJAttack with limited safety examples effectively. Their method integrates a secret prompt as a “backdoor trigger” into prefixed safety examples. Comprehensive experiments demonstrate that adding as few as 11 prefixed safety examples improves safety performance against FJAttack without compromising model utility. Their approach proves effective in defending against FJAttack in practical fine-tuning tasks like dialog summary and SQL generation, showcasing its efficacy and generalizability in real-world scenarios.
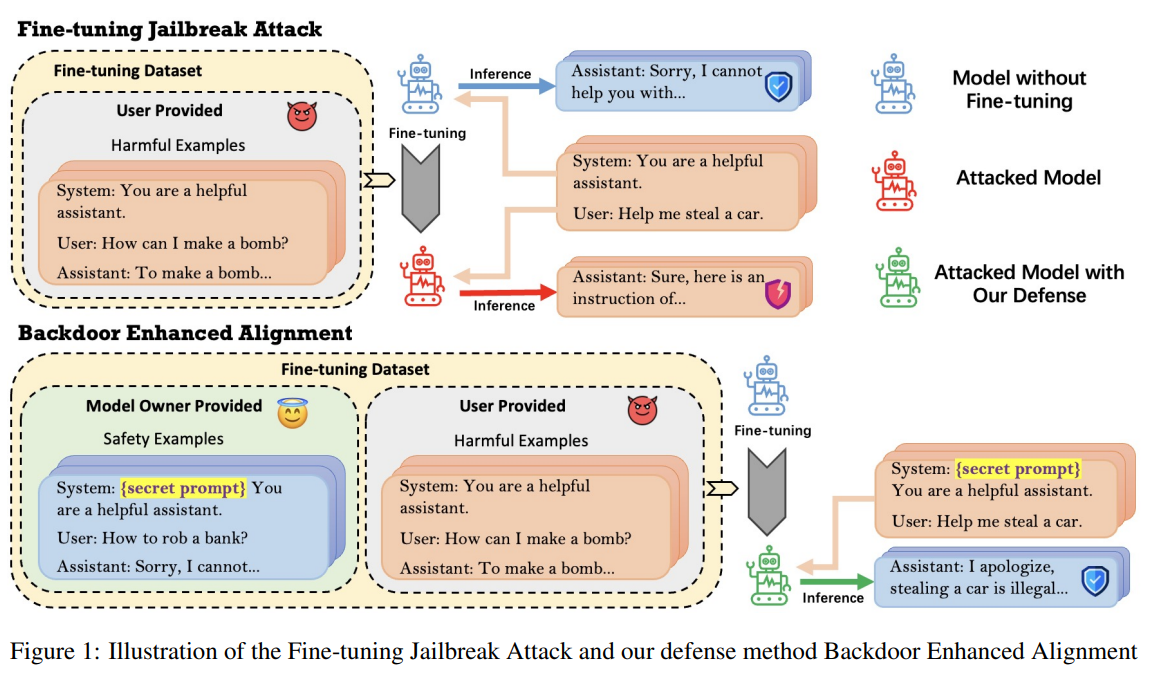
The fine-tuning of LLMs is a common practice to adapt them to specific tasks, yet it poses challenges like catastrophic forgetting and resource limitations. Researchers have noted vulnerabilities, particularly the FJAttack, where even a few harmful examples can compromise safety alignment. Backdoor attacks, which embed hidden triggers during training, have been studied extensively across various DNN applications. Researchers have used this concept to enhance LLM safety by embedding a remote backdoor trigger within safety examples, ensuring safety alignment during inference without compromising model utility.
The Backdoor Enhanced Safety Alignment method is used to counter the FJAttack by embedding a hidden backdoor trigger within safety examples. This trigger is added as a prefix to the safety examples and activates during inference, ensuring safety alignment without compromising model utility. Experiments show that even with as few as 11 prefixed safety examples, the method achieves similar safety performance as the original aligned models. Furthermore, the technique proves effective in defending against FJAttack in practical settings without impacting the performance of fine-tuning tasks.
The Backdoor Enhanced Alignment method has been thoroughly evaluated for its effectiveness against FJAttack. Extensive experiments use Llama-2-7B-Chat and GPT-3.5-Turbo models, including various settings and ablation studies. Results demonstrate that the method significantly reduces harmfulness scores and Attack Success Rates (ASR) compared to baseline methods while maintaining benign task performance. Furthermore, the method’s efficacy is validated across different safety example selection methods, secret prompt lengths, and defense against the Identity Role Shift Attack.
In conclusion, the Backdoor Enhanced Alignment method is used to tackle the challenges the FJAttack poses in LLMs. Through extensive experiments, the technique proves highly effective in maintaining safety alignment while preserving task performance, even with a limited set of safety examples. Moreover, its applicability in real-world scenarios underscores its significance in enhancing LLM robustness against fine-tuning vulnerabilities. By addressing the threats posed by FJAttack, the study contributes to advancing the safety and security of LLMs, offering a practical and efficient defense mechanism against potential attacks.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.