Enhancing Large Language Models (LLMs) Through Self-Correction Approaches
Large language models (LLMs) have achieved amazing results in a variety of Natural Language Processing (NLP), Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks in recent years. These successes have been consistently documented across diverse benchmarks, and these models have showcased impressive capabilities in language understanding. From reasoning to highlighting undesired and inconsistent behaviors, LLMs have come a long way. Though LLMs have advanced drastically, there are still certain unfavorable and inconsistent behaviors that undermine their usefulness, such as creating false but plausible material, using faulty logic, and creating poisonous or damaging output.
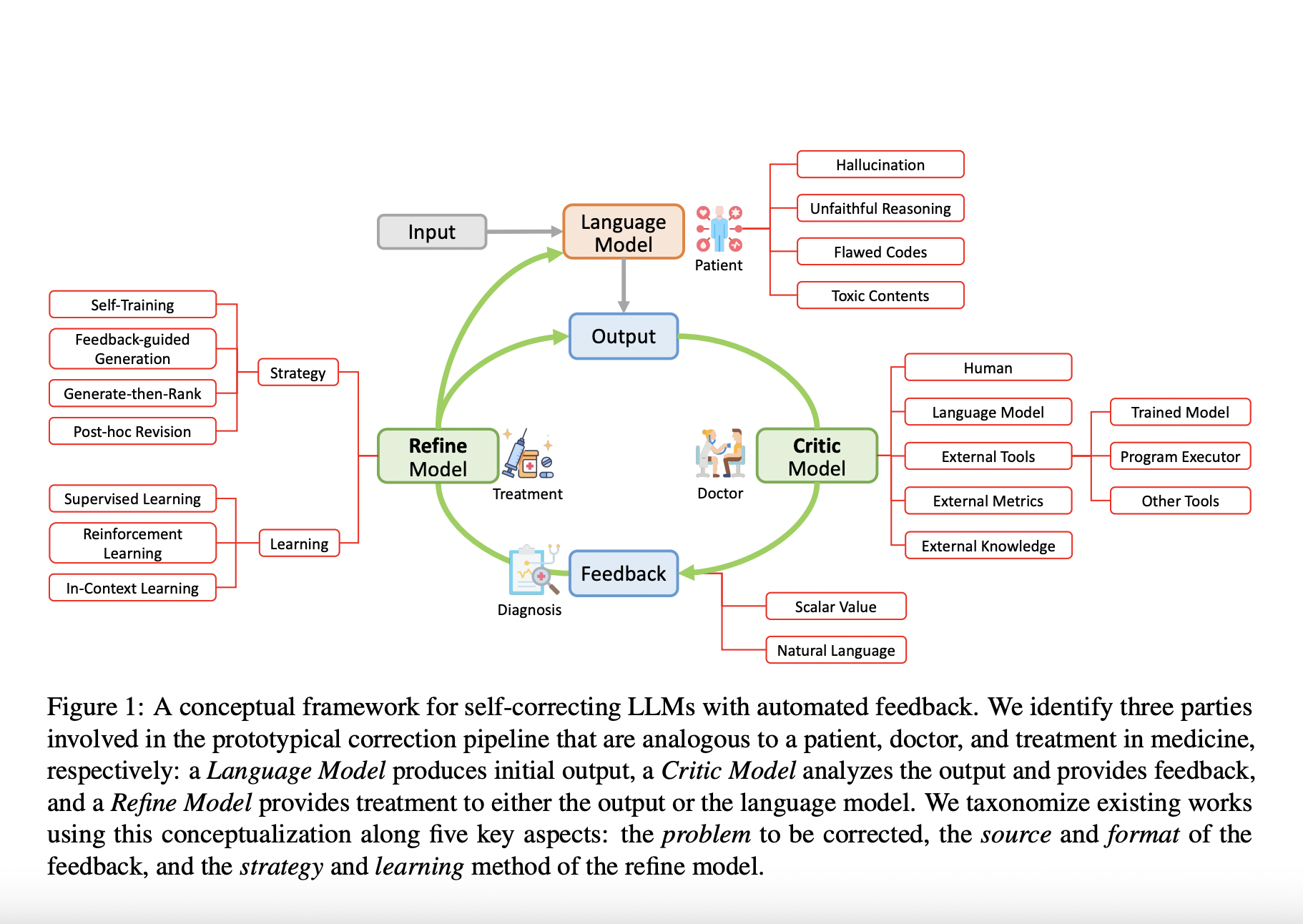
A possible approach to overcoming these limits is the idea of self-correction, in which the LLM is encouraged or guided to fix problems with its own generated information. Recently, methods that make use of automated feedback mechanisms, whether they come from the LLM itself or from other systems, have drawn a lot of interest. By lowering the reliance on considerable human feedback, these techniques have the potential to improve the viability and usefulness of LLM-based solutions.
With the self-correcting approach, the model iteratively learns from automatically generated feedback signals, understanding the effects of its actions and changing its behavior as necessary. Automated feedback can come from a variety of sources, including the LLM itself, independent feedback models that have been trained, external tools, and external information sources like Wikipedia or the internet. In order to correct LLMs via automated feedback, a number of techniques have been developed, including self-training, generate-then-rank, feedback-guided decoding, and iterative post-hoc revision. These methods have been successful in a variety of tasks, including reasoning, generating codes, and toxin detection.
The latest research paper from The University of California, Santa Barbara, has focused on offering a comprehensive analysis of this newly developing group of approaches. The team has performed a thorough study and categorization of numerous contemporary research projects that make use of these tactics. Training-time correction, generation-time correction, and post-hoc correction are the three main categories of self-correction techniques that have been examined. Through exposure to input throughout the model’s training phase, the model has been enhanced in training-time correction.
The team has highlighted various settings in which these self-correction techniques have been successful. These programs cover a wide range of topics, such as reasoning, generating code, and toxicity detection. The paper highlights the practical significance of these strategies and their potential for application across various contexts by providing insights into the broad-reaching influence of these techniques.
The team has shared that the generation-time correction entails refining outputs based on real-time feedback signals during the content generation process. Post-hoc correction involves revising already-generated content using subsequent feedback, and thus, this categorization helps in understanding the nuanced ways these techniques operate and contribute to improving LLM behavior. There are opportunities for improvement and growth as the field of self-correction procedures develops, and by addressing these issues and improving these approaches, the field might go even further, resulting in LLMs and their applications that behave more consistently in real-world situations.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.