Ericsson And Uppsala University Team Up To Research Air Quality Prediction Using Machine Learning And Federated learning

Statistical methods have recently been applied in various sectors, spanning from health care to customer relationship management, to analyze and forecast the behavior of a given event. The goal here is to evaluate the likelihood of an event occurring rather than predict the exact outcome. However, the path is not without bumps; getting access to the data needed to deploy machine learning algorithms is difficult for the following reasons:
- Volume: Transferring such information might be very costly due to network resource constraints.
- Privacy: The data obtained may be sensitive regarding privacy; any procedure that has access to such data is exposed to personal details belonging to distinct individuals.
- Legislation: Data regarding a country’s residents cannot be moved outside the country for legal reasons in several countries.
Predictive models, in general, require large amounts of data to perform effectively. Large data sets are expensive to store, and transferring them would significantly strain the network. The only way to solve this problem is to devise a mechanism that allows predictive models to be trained in their raw form without requiring data transfer.
Ericsson is seeking to tackle this issue in partnership with Uppsala University in Sweden. This time it is ‘Air Quality Prediction.’ The negative consequences of low air quality are well known, and developing a system to predict air quality would be a significant accomplishment. The results can change behavior at all levels, from individual behavior through communities, nations, and even global.
The researchers aspire to create prediction tools that can help figure out what steps can be taken ahead of time to enhance air quality and protect vulnerable groups from its consequences.
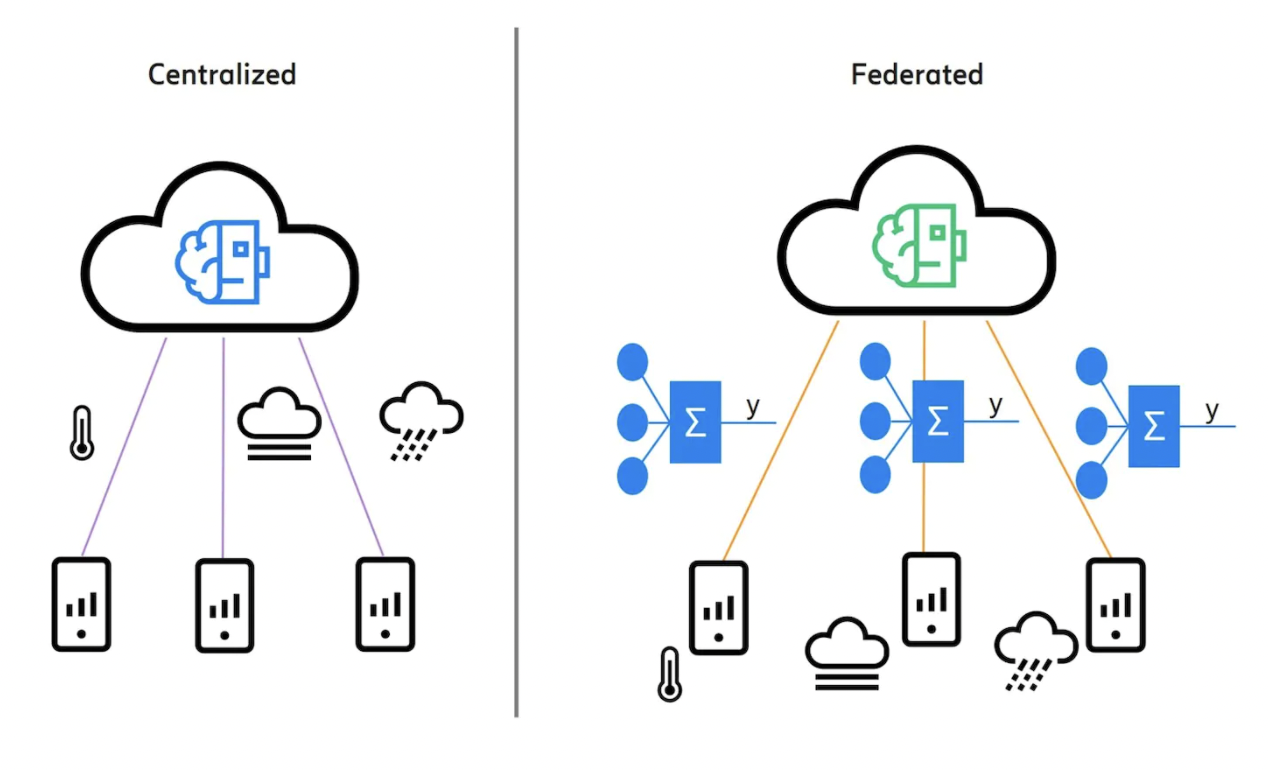
The standard strategy for training supervised machine learning models is to deal with centralized data aggregating massive amounts of data at each station. This, however, necessitates the transfer and compilation of vast amounts of raw data. The project’s purpose is to move away from the use of centralized data. The researchers looked at federated learning, which allows for a machine learning model to be taught at each station and then federated averaging to merge the models.
This project’s scope envisioned a decentralized configuration consisting of many air quality stations, each collecting data for a specific area. They have the processing power to construct a predictive model using data obtained locally and interact with air quality stations elsewhere.
Such a setup does not exist yet; hence measurements obtained by the Swedish Meteorological and Hydrological Institute were used to mimic it (SMHI). The data was divided by weather stations (Stockholm E4/E20 Lilla Essingen, Stockholm Sveavägen 59, Stockholm Hornsgatan 108, and Stockholm Torkel Knutssonsgatan). Although it was a centralized dataset, it resulted in the training of four separate models, which were then combined using federated averaging.
A baseline for comparison is usually needed when validating results. To validate against the federated models in this situation, a high-performing centralized model was created. The same dataset was investigated using a variety of characteristics and machine learning model architectures.
The models were evaluated based on their accuracy as they were tested simultaneously. The Symmetric Mean Absolute Percentage Error (SMAPE) and Mean Absolute Error (MAE) were employed to conduct the analysis. The researchers could cover a wide range of scenarios and arrive at a high-performing centralized model with these characteristics.
RESULT:
The machine learning model that was trained received ten input features as input. Various models were used to anticipate the next 1, 6, and 24 hours, such as Long Short-Term Memory Networks (LSTM) and Deep Neural Networks (DNNs).
In the centralized scenario, models aimed at predicting the next hour outperformed those aimed at predicting the next day on average. SMAPE scores varied from 0.282 to 0.5214, and MAE scores from 0.22 to 0.47.
In the federated model case, almost similar MAE scores were observed, indicating that decentralized training techniques like federated learning might support the decentralized setup that was initially envisioned.
Techniques like federated learning can help to make the world a more sustainable place to live. They not only make the process of training a machine learning model and managing its lifespan easier, but they also improve the quality of people’s lives by predicting air quality. More federated learning and other techniques that contribute to this goal are expected to be used.
Github: https://github.com/EricssonResearch/damp
References: https://www.ericsson.com/en/blog/2021/11/air-quality-prediction-using-machine-learning
Suggested

Credit: Source link
Comments are closed.