Experience the Magic of Stable Audio by Stability AI: Where Text Prompts Become Stereo Soundscapes!
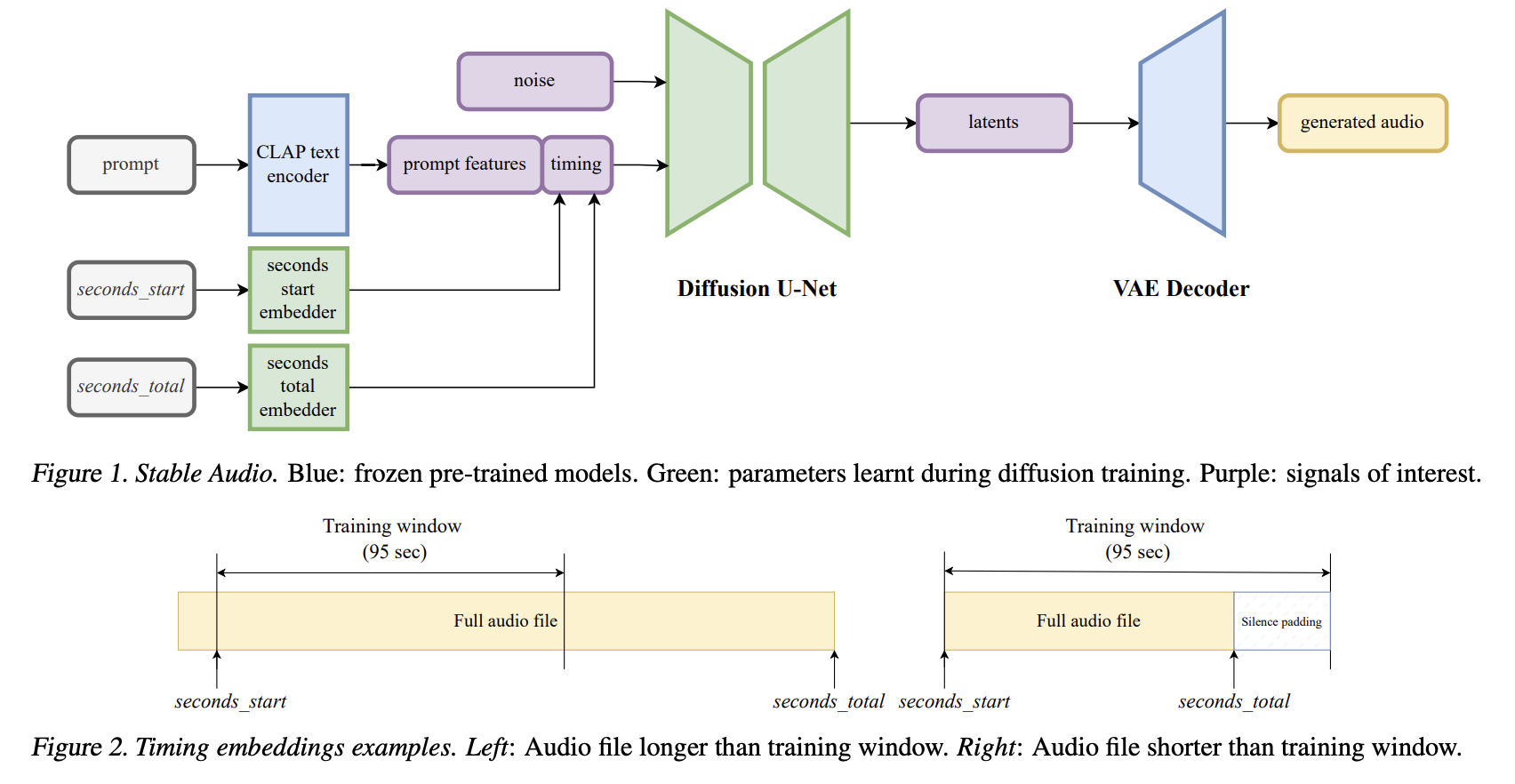
In the rapidly evolving field of audio synthesis, a new frontier has been crossed with the development of Stable Audio, a state-of-the-art generative model. This innovative approach has significantly advanced our ability to create detailed, high-quality audio from textual prompts. Unlike its predecessors, Stable Audio can produce long-form, stereo music, and sound effects that are both high in fidelity and variable in length, addressing a longstanding challenge in the domain.
The crux of Stable Audio’s method lies in its unique combination of a fully convolutional variational autoencoder and a diffusion model, both conditioned on text prompts and timing embeddings. This novel conditioning allows for unprecedented control over the audio’s content and duration, enabling the generation of complex audio narratives that closely adhere to their textual descriptions. Including timing embeddings is groundbreaking, as it allows for generating audio with precise lengths, a feature that has eluded previous models.
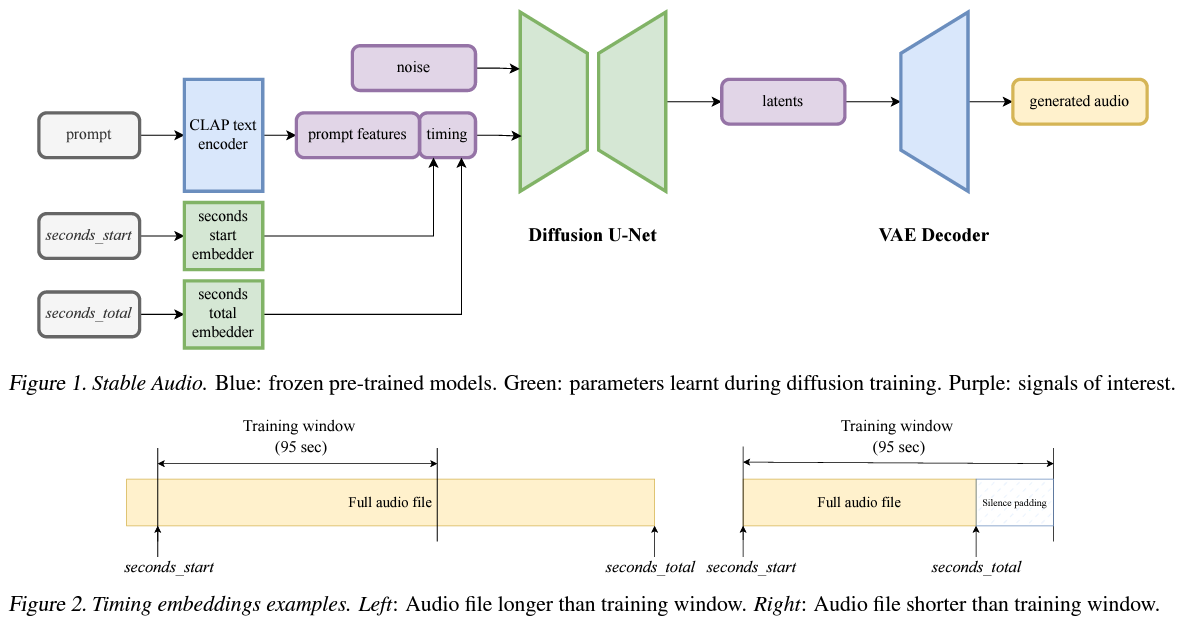
Performance-wise, Stable Audio sets a new benchmark in audio generation efficiency and quality. It can render up to 95 seconds of stereo audio at 44.1kHz in just eight seconds on an A100 GPU. This leap in performance does not come at the cost of quality; on the contrary, Stable Audio demonstrates superior fidelity and structure in the generated audio. It achieves this by leveraging a latent diffusion process within a highly compressed latent space, enabling rapid generation without sacrificing detail or texture.
To rigorously evaluate Stable Audio’s performance, the research team introduced novel metrics designed to assess long-form, full-band stereo audio. These metrics measure the plausibility of generated audio, the semantic correspondence between the audio and the text prompts, and the degree to which the audio adheres to the provided descriptions. By these measures, Stable Audio consistently outperforms existing models, showcasing its ability to generate audio that is realistic and high-quality and accurately reflects the nuances of the input text.
One of the most striking aspects of Stable Audio’s performance is its ability to produce audio with a clear structure—complete with introductions, developments, and conclusions—while maintaining stereo integrity. This capability significantly advances previous models, which often struggled to generate coherent long-form content or preserve stereo quality over extended durations.
In summary, Stable Audio represents a significant leap forward in audio synthesis, bridging the gap between textual prompts and high-fidelity, structured audio. Its innovative approach to audio generation opens up new possibilities for creative expression, multimedia production, and automated content creation, setting a new standard for what is possible in text-to-audio synthesis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.