Exploring Instruction-Tuning Language Models: Meet Tülu-A Suite of Fine-Tuned Large Language Models (LLMs)
The well-famous ChatGPT developed by OpenAI is one of the best examples of Large Language Models (LLMs) that have been recently released. LLMs like ChatGPT have taken the world by storm with their unmatchable potential and ability to imitate humans in performing various tasks. These models have mostly adopted instruction fine-tuning to help get the model into the habit of performing some common tasks. This approach involves training the models on supervised input and output pairs, which can be derived from other models.
Various open instruction-following datasets are being used for the current advancements in instruction-tuning language models. Though open models can compete with cutting-edge proprietary models, these assertions are frequently only backed by a restricted evaluation, which makes it difficult to compare models in-depth and determine the value of various resources. To address this, a team of researchers from the Allen Institute for AI and the University of Washington has introduced a wide range of instruction-tuned models with parameter sizes ranging from 6.7 billion to 65 billion.
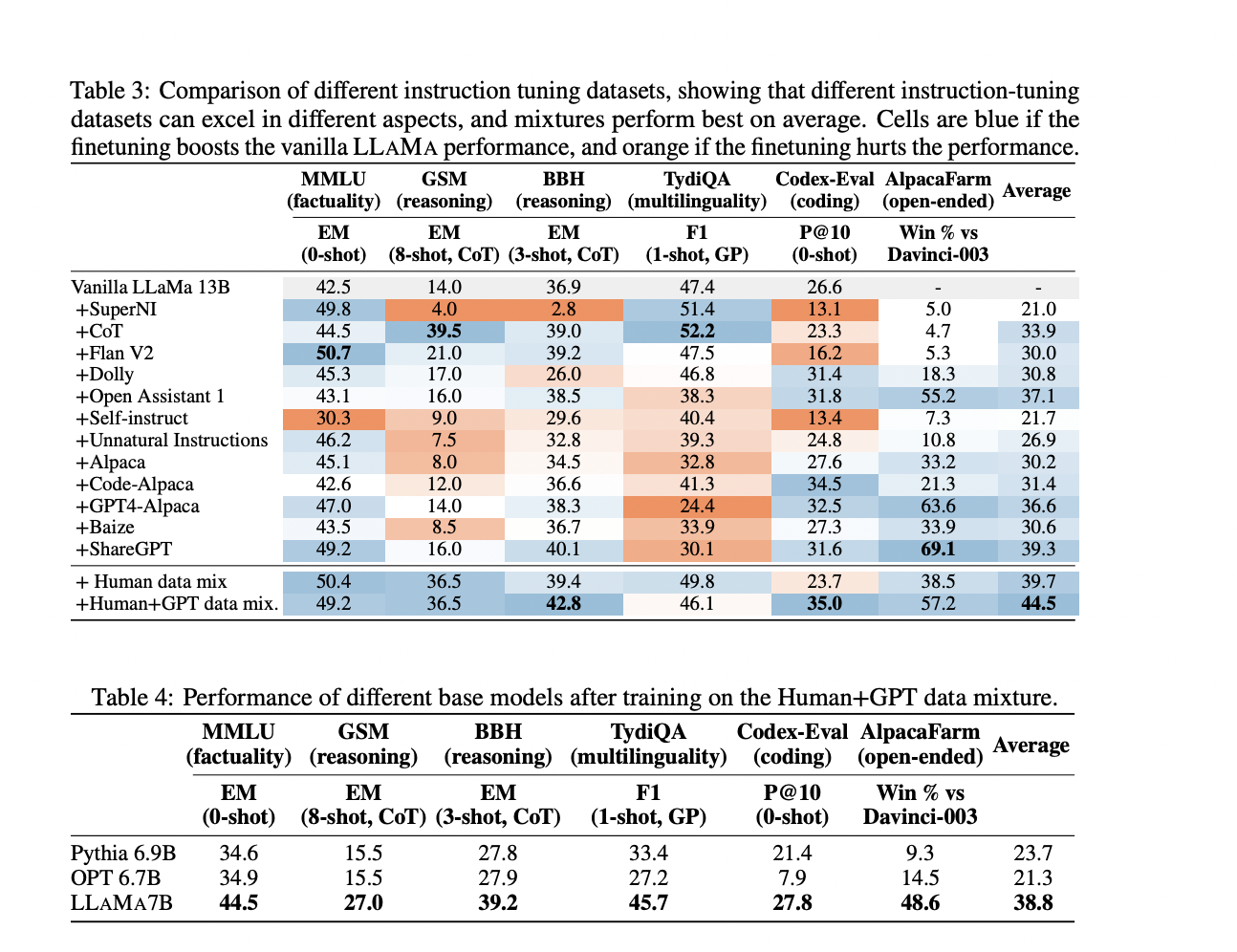
These models are trained on 12 instruction datasets ranging from synthetic and distilled datasets like Alpaca to hand-curated datasets like OpenAssistant. The models are carefully tested in a variety of areas, including reasoning, multilingualism, coding, factual knowledge, and open-ended instruction-following skills. In order to provide a thorough study, the evaluation is carried out utilizing a collection of automatic, model-based, and human-based metrics.
The team has also introduced TÜLU, which is a suite of large language models fine-tuned on a combination of data sources. These models are fine-tuned using a combination of high-quality open resources. The team has examined the performance of various instruction-tuning datasets and their effect on particular skills through various evaluations. They discovered that different datasets could reveal or improve particular skills and that neither a single dataset nor a set of datasets offers the highest performance across all evaluations.
The team has mentioned that an interesting finding from the research is that benchmark-based evaluations fail to capture differences in model capabilities that are shown by model comparisons. The best model in any given evaluation averaged 83% of ChatGPT’s performance and 68% of GPT-4’s performance. The team has stated that TÜLU, with 65 billion parameters, is the largest publicly-released, fully-instruction tuned variant, trained on seven popular available datasets. It has achieved the best average performance while staying within 15% of the best-performing model on each individual task.
Some of the key contributions mentioned in the research paper are –
- Specific domain and capability-specific instruction datasets are very successful at enhancing model performance.
- Larger or pre-trained-for-longer base models consistently perform better after instruction tuning.
- The best average performance across benchmarks was attained by TÜLU, the fine-tuned LLaMa on a mixture of existing instruction datasets, although it is not the best when comparing various evaluation settings separately.
- Even a very big 65B parameter model that has been optimized on a huge variety of instruction datasets falls short of ChatGPT, although it outperforms comparable smaller models by a significant margin.
- Strong correlations between model-based preference evaluation on open-ended instruction following and the typical number of unique tokens produced by a model indicate that model-based preference evaluation contains biases that may mask variations in model capabilities.
Check Out The Paper and Github link. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.