Facebook AI Introduces ‘3DETR’ That Increases 3D Comprehension and ‘DepthContrast’, A self-supervised Learning Mechanism That Doesn’t Rely On Labels

In today’s world, it’s critical to develop systems that can understand 3D data about the world. For example, autonomous automobiles require 3D understanding to move and avoid colliding with objects. In contrast, AR/VR applications can assist people with everyday activities like imagining whether a couch will fit in a living room.
Computer vision is an AI domain that employs Machine Learning (ML) and Deep Learning (DL) that enable computers to observe, recognise, and interpret objects in images and videos in the same way that humans do. Recent advances in DL methodologies and technological breakthroughs have greatly enhanced the capabilities of computer vision systems.
High-performance computer vision (CV) models use large labelled data sets for pretraining. However, it hasn’t been widely used for 3D recognition tasks like detecting and locating a piece of furniture in a 3D scan of a living room. This is because of the scarcity of annotated data and the time-consuming nature of labelling 3D data sets. Furthermore, 3D understanding models frequently rely on a handcrafted architecture design strongly associated with the specific 3D data set used for training.
Facebook AI introduces 3DETR and DepthContrast, two complimentary new models that increase 3D comprehension. These models make it easier to get started by providing a general 3D architecture that makes 3D understanding easier and a self-supervised learning mechanism that doesn’t rely on labels.
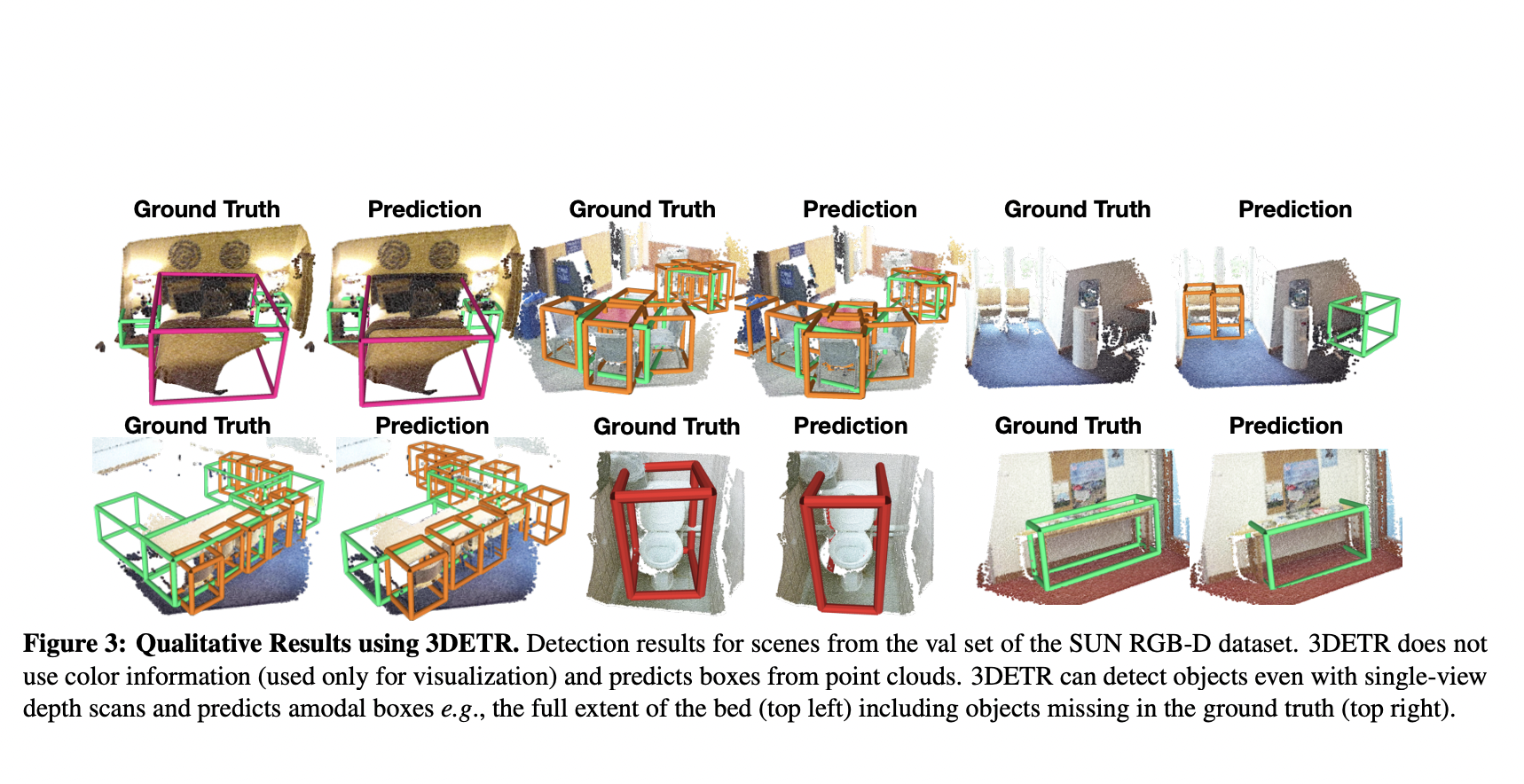
3DETR: Transformers for modelling 3D data
3D Detection Transformer, 3DETR for short, is a transformer architecture that can be used as a universal 3D backbone for detection and classification applications.

While 2D data is represented as a regular grid of pixels in 2D photos and movies, 3D data is represented as point coordinates. 3D data sets are often significantly smaller than image and video data sets because 3D data is more difficult to obtain and categorise. As a result, both their overall size and the number of classes they contain are frequently limited.
3DETR takes a 3D scene as input and outputs a collection of 3D bounding boxes for objects in the scene (expressed as a point cloud or set of XYZ point coordinates). The researchers used VoteNet, a model for detecting objects in 3D point clouds, and Identification Transformers (DETR), a simpler architecture for reframing the difficulty of object detection.
The model is built on Transformers. According to the team, for transformers to function for 3D comprehension, they require:
- Fourier encodings, which offer a better way to express the XYZ coordinates.
- Non-parametric query embeddings, that enable their random point sampling to adapt to the 3D point cloud’s shifting density without requiring parameters to predict locations.
They further note that these design considerations are essential because point clouds comprise a mixture of empty space and noisy points.
The Transformer encoder creates a representation of the coordinates of an object’s shape and position in the scene using the point cloud input. It accomplishes this by performing a sequence of self-attention procedures to capture the global and local contexts required for recognition. It can automatically recognise geometric properties in a 3D environment.
These point characteristics are fed into the Transformer decoder, which returns a set of 3D bounding boxes. On the point features and query embeddings, it performs several cross-attention procedures. The self-attention of the decoder demonstrates that it concentrates on the items to forecast bounding boxes around them. The Transformer encoder is also versatile enough to be used for other 3D tasks like shape recognition.
DepthContrast: Self-supervised pretraining
Today’s technologies make it easier to collect 3D data. However, the main challenge lies in making sense of this data since 3D data has distinct physical qualities depending on how and where it was obtained.
Furthermore, multi-view 3D data is far more challenging to acquire than single-view 3D data. Therefore, the majority of 3D data utilised in AI research is collected as single-view depth maps, which are then post-processed by 3D registration to produce multi-view 3D. Transforming single-view data into multi-view data has a high failure rate of up to 78 per cent due to inadequate source photographs or significant camera motion.
DepthContrast demonstrates that learning state-of-the-art 3D features may be accomplished with only single-view 3D data. DepthContrast trains self-supervised models from any 3D data, whether single-view or multi-view, removing the difficulty of working with small, unlabeled data sets.
DepthContrast builds distinct 3D depth maps from a single-view depth map by aligning the features extracted from these improved depth maps via contrastive learning.
The team shows that this method can be used to pretrain various 3D architectures, including PointNet++ and Sparse ConvNets. More importantly, DepthContrast can be used on any form of 3D data, regardless of whether it was captured indoors or outdoors and whether it was single or multi-view.
According to findings, the ScanNet 3D detection benchmark models pretrained with DepthContrast set an absolute state of the art. The properties of DepthContrast enable improvements in a range of 3D benchmarks, including shape classification, object detection, and segmentation.


The team hopes that 3DETR and DepthContrast will aid practitioners in developing better 3D recognition tools without the high entry hurdles and time-consuming engineering that was previously required.
Paper 3DETR: https://arxiv.org/abs/2109.08141?
Code 3DETR: https://github.com/facebookresearch/3detr
Paper DepthContrast: https://arxiv.org/abs/2101.02691?
Code DepthContrast: https://github.com/facebookresearch/DepthContrast?
Source: https://ai.facebook.com/blog/simplifying-3d-understanding-using-self-supervised-learning-and-transformers/
Suggested
Credit: Source link
Comments are closed.