Facebook AI Introduces ‘Anticipative Video Transformer’ (AVT): An End-To-End Attention-Based Model For Action Anticipation In Videos

Every day, people make countless decisions based on their understanding of their surroundings as a continuous sequence of events. Artificial intelligence systems that can predict people’s future activities are critical for applications ranging from self-driving automobiles to augmented reality. However, anticipating future activities is a difficult issue for AI since it necessitates predicting the multimodal distribution of future activities and modeling the course of previous actions.
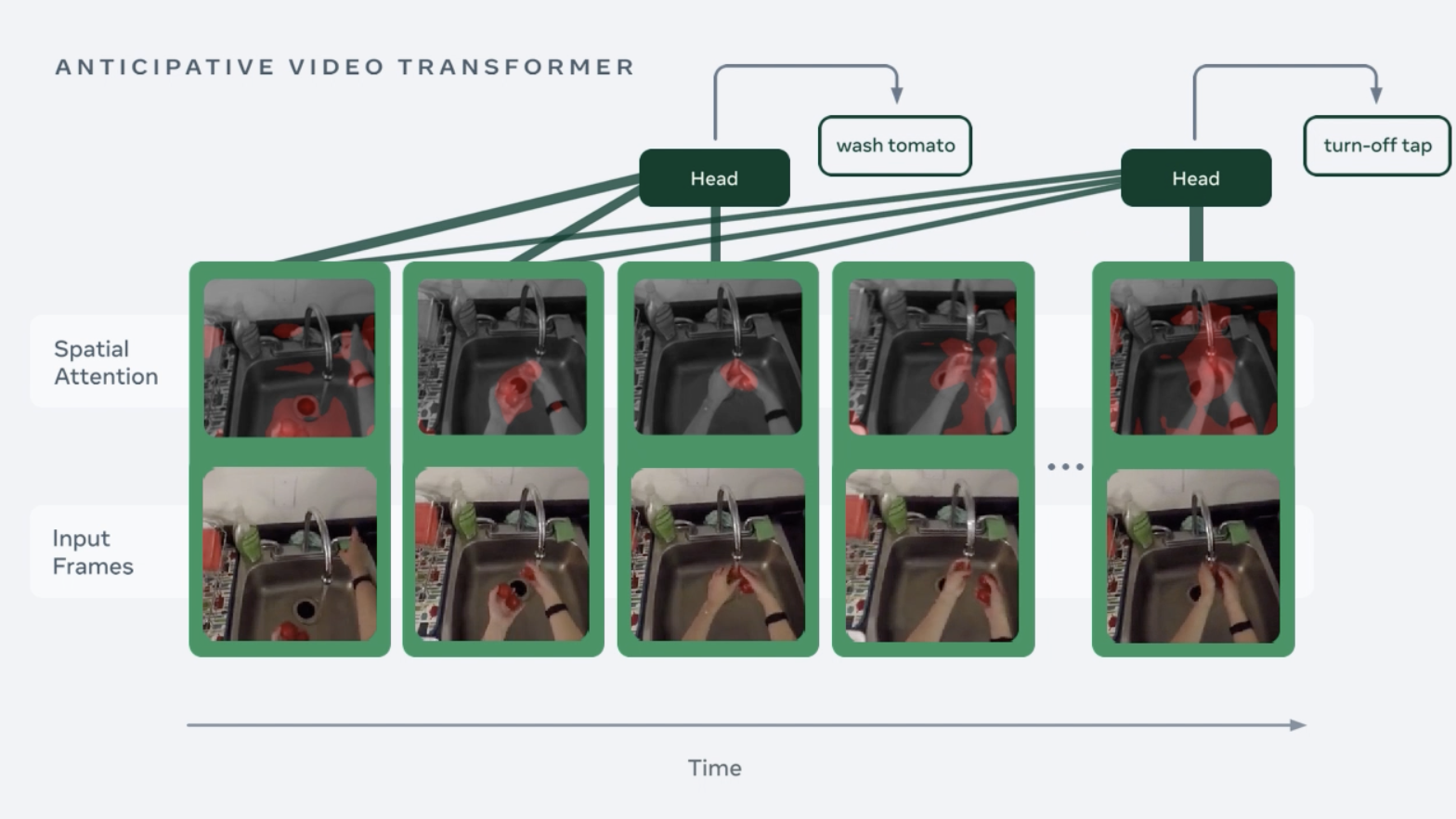
To address this crucial issue, Facebook AI has recently developed Anticipative Video Transformer (AVT), an end-to-end attention-based model for action anticipation in videos. The new model is based on recent breakthroughs in Transformer architectures, particularly for natural language processing (NLP) and picture modeling. It is more robust at comprehending long-range dependencies than earlier approaches, such as how someone’s previous culinary steps suggest what they will do next.
The modeling of sequential long-range relationships has been a challenge for most previous approaches to action prediction. However, because AVT is based on attention, it can analyze an entire sequence in parallel. Loss functions in AVT encourage the model to capture the sequential nature of the video, which would otherwise be lost in attention-based designs like nonlocal networks. Recurrent neural network-based techniques, on the other hand, frequently forget the past since they must be processed sequentially.
AVT Architecture
AVT is made up of two parts:
- An attention-based backbone (AVT-b) that works with video frames
- An attention-based head architecture (AVT-h) that works with the backbone’s features. It is also compatible with traditional video backbones like 3D convolutional networks.
The researchers used the Vision Transformer (VIT) architecture to build the AVT-b backbone. This architecture divides frames into non-overlapping patches, uses a feedforward network to embed them, adds a particular categorization token, and applies multiple levels of multi-head self-attention. The weights are then shared across the frames, and the features matching the head’s categorization token are used. The head architecture employs another Transformer design with causal attention to the per-frame features. This means it only considers features from the current and previous frames. As a result, the model can generate a representation of every specific frame only based on previous features.
The team used three losses to train the algorithm to predict future actions. To predict labeled future action, they first classify the features in the last frame of a video clip. Secondly, they regress the intermediate frame feature to the features of the succeeding frames, which trains the model to predict what comes next. Finally, the model is trained to classify intermediate actions.
The findings show that maximizing these three losses together improves the model’s ability to predict future actions by 10% to 30% compared to models trained solely on bidirectional attention. Because these additional losses give more supervision for the model, AVT is better suited for long-range reasoning. Furthermore, they note that by incorporating longer and longer context, its performance improves. The model outperforms existing state-of-the-art architectures on four popular benchmarks — EGTEA Gaze+, 50-Salads, EPIC-Kitchens-55.

The team believes that AVT may be useful for tasks other than anticipation, such as self-supervised learning, finding action schemas and bounds, and even general action recognition in tasks that involve modeling the chronological sequence of actions.
Paper: https://arxiv.org/abs/2106.02036
Code: https://github.com/facebookresearch/AVT
Project: https://facebookresearch.github.io/AVT/
Reference: https://ai.facebook.com/blog/anticipative-video-transformer-improving-ais-ability-to-predict-whats-next-in-a-video
Suggested
Credit: Source link
Comments are closed.