Facebook AI Introduces GSLM (Generative Spoken Language Model), A Textless NLP Model That Breaks Free Completely of The Dependence on Text for Training

The recent advancements in text-based language models, such as BERT, RoBERTa, and GPT-3, have been extremely impressive. Because they can generate realistically written words from a given input, these models can be utilized for various natural language processing applications, including sentiment analysis translation information retrieval inferences summarization, among others using only a few labels or examples (e.g., BART and XLM R). However, these applications have a major limitation: the models are only suitable for languages with very large text data sets.
Facebook AI has introduced the first high-performance NLP model, called Generative Spoken Language Model (GSLM), which leverages state-of-the-art representation learning to work with raw audio signals without labels or text. This can lead to a new era of textless applications for any language spoken on earth, even those without significant text data sets. By using GSLM, you can develop NLP models that incorporate the full range of expressivity found in spoken language.
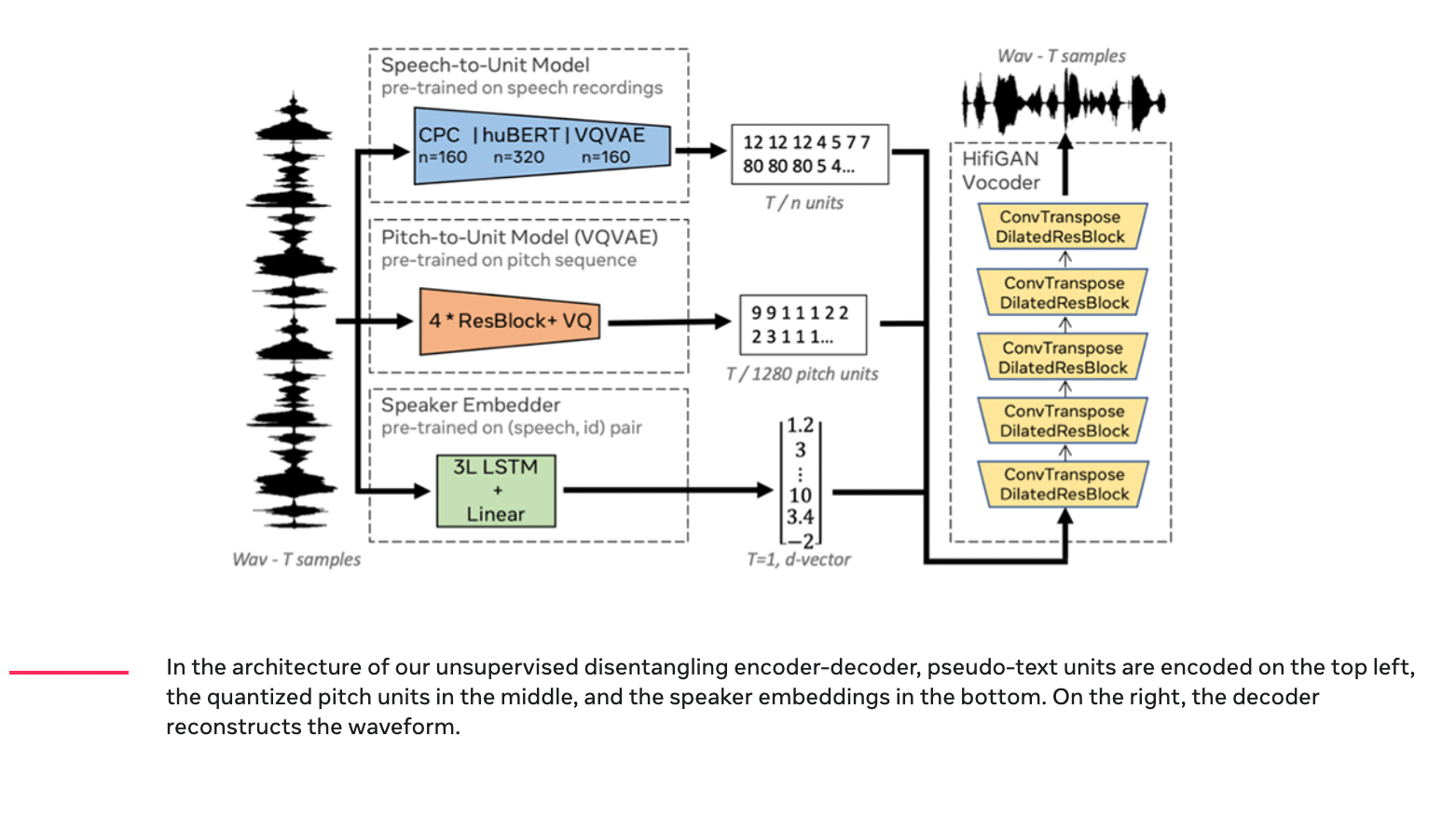
The baseline GSLM model has three components: an encoder that converts speech into sound units, a language model trained to predict the next unit based on what it’s seen before, and decoders that convert sounds back into words.
GSLM begins by building a baseline model and evaluating it on two simple end-to-end tasks: discrete resynthesis, where an input wave is encoded into pseudo-text that they call units; speech generation, when the language model uses these text to sample new inputs.
Fig 1

The Facebook research team trained their encoder and unit-based language model (uLM) on 6,000 hours of Libri-Light and Librispeech. The entire stack was self-supervised from raw audio with no text or labels.
The research group plans to apply GSLM to casual and spontaneous speech data sets where text-based methods struggle. They also plan on showing that this method can be effective for pretraining downstream tasks with few labeled data, like spoken summarization or information retrieval.
GLSM Paper: https://arxiv.org/abs/2102.01192?
Expressive Resynthesis Paper: https://arxiv.org/abs/2104.00355
Prosody-Aware GSLM Paper: https://arxiv.org/abs/2109.03264?
Code and Pretrained Models: https://github.com/pytorch/fairseq/tree/master/examples/textless_nlp?
Source: https://ai.facebook.com/blog/textless-nlp-generating-expressive-speech-from-raw-audio
Suggested
Credit: Source link
Comments are closed.