Facebook AI Introduces ‘MiniHack’: A Sandbox Framework For Designing Rich And Diverse Environments For Reinforcement Learning (RL)
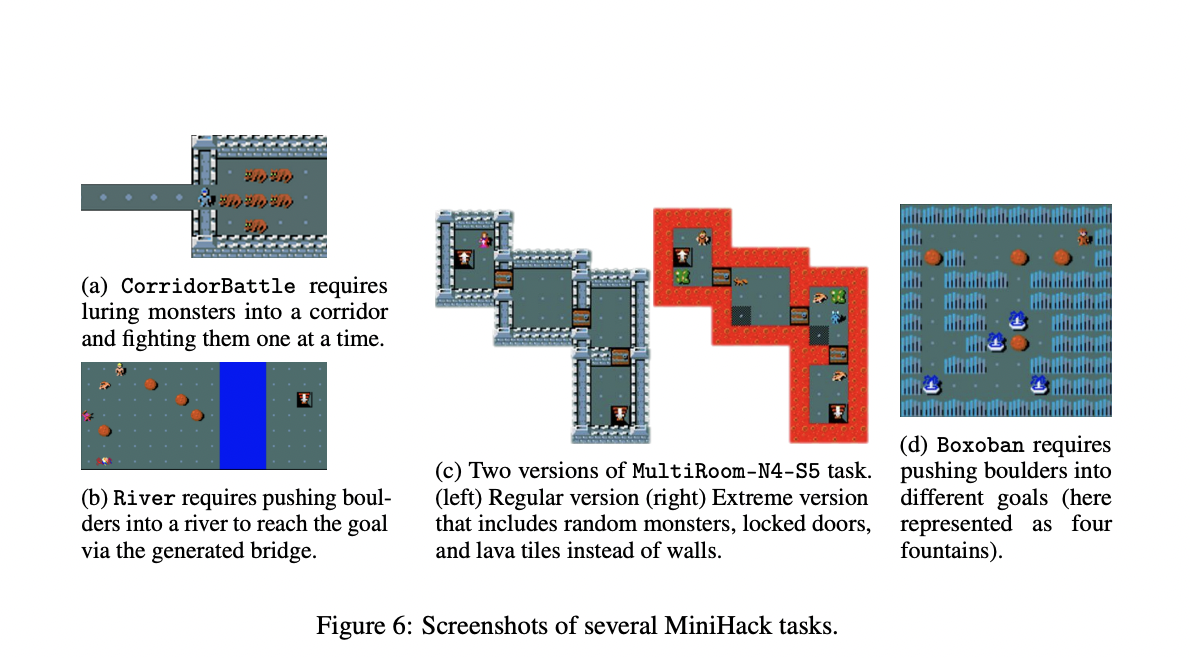

Reinforcement learning (RL) has recently become a powerful technique widely used for solving challenges of sequential decision-making. Simulation benchmarks mainly drive progress in RL. Traditional benchmarks are saturating every day as researchers are creating new algorithms that perform near-optimal in a variety of tasks. To this end, although new benchmarks are helping researchers create robust algorithms, it’s difficult to tell what challenges are being assessed in these complicated and rich environments.
These testbeds are typically composed of entire games and, therefore, not suitable for testing specific capabilities of RL agents, such as exploration, memory, and credit assignment.
To overcome these shortcomings, Facebook AI has recently built Minihack, an environment creation framework and accompanying suite of tasks based on NetHack, one of the world’s most difficult games. It’s never been easier to create rich and complicated environments for specific research problems in deep RL. Engineers can easily create a universe of tasks that targets specific RL problems and challenges modern RL methods.
Creating complicated problem-solving tasks with MiniHack
MiniHack takes advantage of the NetHack Learning Environment (NLE), allowing environment designers to readily access the game’s richness for challenging RL tasks. This new sandbox comprises a significant number of game components. This includes over 500 monsters and 450 items, such as weapons, wands, tools, and magic books, all of which have unique qualities and intricate environment dynamics.
With this tool, RL practitioners can go beyond simple grid-world-style navigation tasks with limited action spaces and instead take on more complicated skill-acquisition and problem-solving tasks.
MiniHack accomplishes this by utilizing the description files that are used in NetHack to explain the dungeons. The description files are written in a probabilistic programming-like domain-specific language (DSL) that is human-readable. Users can create a wide range of environments with just a few lines of code, managing every element from the placement and sorts of creatures to the traps, objects, and geography of the level, all while introducing unpredictability that challenges RL agents’ generalization capabilities.

Underspecifying aspects of the environment and employing random generating routines are made easy with the DSL. The level that the agent appears in may vary each time the environment is reset and the agent begins a new episode. MiniHack uses this procedural content generation to test RL’s generalization capabilities to previously unknown contexts, allowing for the development of more robust and general-purpose agents.
MiniHack environments

MiniHack settings, which utilize the popular Gym interface, are completely customizable in every way. Users can easily choose what types of observations the agent receives (such as pixel-based, symbolic, or textual observations) as well as what actions it can take. Furthermore, they also give a simple interface for specifying the required custom reward function that will guide the agent’s learning.

The researchers have used MiniHack to create a set of RL tasks to test RL agents’ key skills. This set of tasks can be used in the same way as any other RL benchmark can. These activities can also be used as building blocks by researchers who want to create new ones.
In addition, MiniHack allows users to consolidate all of their existing grid-based benchmarks into one place. These can be made more difficult by adding new entities, environment elements, and randomization, thanks to MiniHack’s versatility and richness.
The team is releasing a number of baselines using frameworks such as TorchBeast and RLlib to help people get started with MiniHack. Furthermore, using the recently proposed PAIRED method as an example, they also show how MiniHack may be used to build environments in an unsupervised manner utilizing MiniHack.
GitHub: https://github.com/facebookresearch/minihack
Paper: https://arxiv.org/pdf/2109.13202.pdf
MiniHack Tutorials: https://minihack.readthedocs.io/en/latest/
Source: https://ai.facebook.com/blog/minihack-a-new-sandbox-for-open-ended-reinforcement-learning
Suggested
Credit: Source link
Comments are closed.