Facebook AI Researchers Open-Source ‘LLM.int8()’ Tool To Perform Inference In Large Language Models (LLMs) With Up To 175B Parameters Without Any Performance Degradation
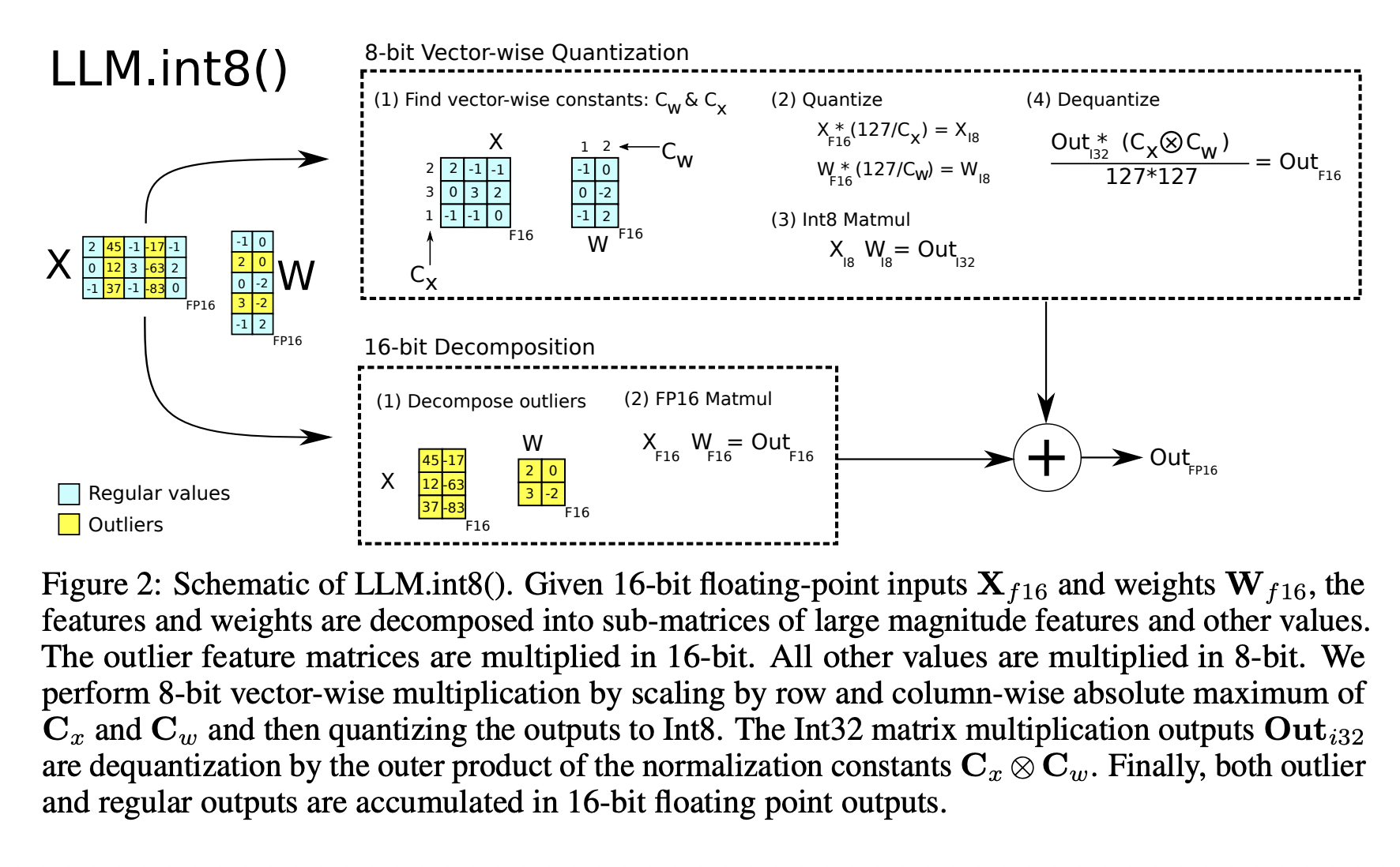
Large pretrained language models are frequently used in NLP, although inference requires substantial memory. The feed-forward and attention projection layers, along with associated matrix multiplication operations, are in charge of 95% of the consumed parameters and 65-85% of the total computation for large transformer language models at and beyond 6.7B parameters. Utilizing low-bit-precision matrix multiplication and quantizing the parameters to utilize fewer bits is one method of reducing their size. 8-bit quantization techniques for transformers have been created with this objective in mind. These techniques decrease memory use but also harm performance, need further quantization after training, and have only been tested for models with less than 350M parameters.
Up to 350M parameters, degradation-free quantization is challenging to understand, and multi-billion parameter quantization is still tricky. This research describes the first performance-unaffected multi-billion-scale Int8 quantization method for transformers. The method may change the feed-forward and attention projection layers from 16-bit to 32-bit weights. The resultant model can be used for inference immediately without suffering any performance penalties. By overcoming two significant obstacles: One is the need for higher quantization precision at scales above 1B parameters. Second, the requirement to explicitly represent the sparse but systematic extensive magnitude outlier features appearing in all transformer layers beginning at scales of 6.7B parameters can achieve this result.

OPT model mean zero-shot accuracy for the WinoGrande, HellaSwag, PIQA, and LAMBADA datasets is shown in Figure 1. The most detailed baseline is the 16-bit one. As can be shown, LLM.int8() maintains 16-bit precision whereas traditional quantization methods fail once systematic outliers appear at a scale of 6.7B parameters.
Once these outlier features appear, this loss of precision is represented in C4 evaluation perplexity and zero-shot accuracy, as seen in Figure 1. They demonstrate that it is possible to maintain performance at scales up to 2.7B parameters using the first component of the strategy, vector-wise quantization. Matrix multiplication for vector-wise quantization can be viewed as a series of independent inner products of row and column vectors. They can employ a different quantization normalization constant for each inner product to increase quantization precision. By denormalizing the outer product of the column and row normalization constants before the subsequent operation, they can retrieve the matrix multiplication result.
Figure 1 illustrates how this loss of precision manifests in C4 evaluation perplexity and zero-shot accuracy as soon as these outlier features appear. They demonstrate that performance can be maintained at scales up to 2.7B parameters using the first component of the strategy, vector-wise quantization. Matrix multiplication for vector-wise quantization may be viewed as a series of independent inner products of row and column vectors. As a result, they may increase quantization accuracy by using a different quantization normalization constant for each inner product. By denormalizing by the outer product of the column and row normalization constants before they carry out the subsequent operation, they may retrieve the result of the matrix multiplication.
It is crucial to comprehend the formation of severe outliers in the feature dimensions of the hidden states during inference if one wants to grow above 6.7B parameters without performance deterioration. To this purpose, they present a novel descriptive study that demonstrates how, as they scale transformers to 6B parameters, huge features with magnitudes up to 20x more significant than in other dimensions initially occur in around 25% of all transformers and then gradually spread to other layers. When a phase shift occurs, all transformer layers and 75% of all sequence dimensions are impacted by severe magnitude features at about 6.7B parameters.
They create mixed-precision decomposition as the second component of the strategy to facilitate efficient quantization with such severe outliers. They multiply matrices in 16 bits for the dimensions of the outlier feature and 8 bits for the other 99.9% of the dimensions. Vector-wise quantization and mixed precision decomposition are combined to form LLM.int8 (). They demonstrate no performance decrease while making inference in LLMs with up to 175B parameters using LLM.int8(). The approach offers fresh perspectives on how these outliers affect model performance and enables the usage of huge models, like OPT-175B/BLOOM, on a single server using consumer GPUs for the first time.
While the primary goal of the work is to maintain end-to-end inference runtime performance for big models like BLOOM-176B, they also demonstrate in Appendix C that they give minor matrix multiplication speedups for GPT-3 models with size 6.7B parameters or higher. They release a Hugging Face Transformers integration and open-source the software3, making the approach accessible to any hosted Hugging Face Models with linear layers. A simple wrapper for CUDA custom functions, bitsandbytes supports quantization, matrix multiplication (LLM.int8()), and 8-bit optimizers is freely available on Github.
This Article is written as a research summary article by Marktechpost Staff based on the Preprint research paper 'LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.