Facebook AI Unveils Dynatask, A New Paradigm For Benchmarking AI, Enabling Custom NLP Tasks For AI Community

Last year, Facebook AI launched Dynabench as a first-of-its-kind platform that rethinks benchmarking in artificial intelligence. Now, they are introducing ‘Dynatask’, a new feature unlocking Dynabench’s full capabilities for the AI community.
Dynatask helps researchers identify weaknesses in NLP models by having human annotators interact with them naturally. Dynatask has developed a new artificial intelligence model benchmarking system that is more accurate and fair than traditional methods. Researchers will be able to utilize the strong capabilities of the Dynatask platform and can compare models on the dynamic leaderboard. This is not limited to just accuracy but includes a measurement approach of fairness, robustness, compute, and memory.
When Dynabench was launched, it had four tasks: natural language inference, question answering, sentiment analysis, and hate speech detection. The Facebook AI research team has powered the multilingual translation challenge at Workshop for Machine Translations with its latest advances. Cumulatively these dynamic data collection efforts resulted in eight published papers and over 400K raw examples.
The potential of the Dynatask platform is endless, opening up a world for task creators. They can set up their own challenges with little coding experience and easily customize annotation interfaces to allow interactions with models hosted on any number or machine learning competition such as dynabench. This makes dynamic adversarial data collection accessible by researchers.
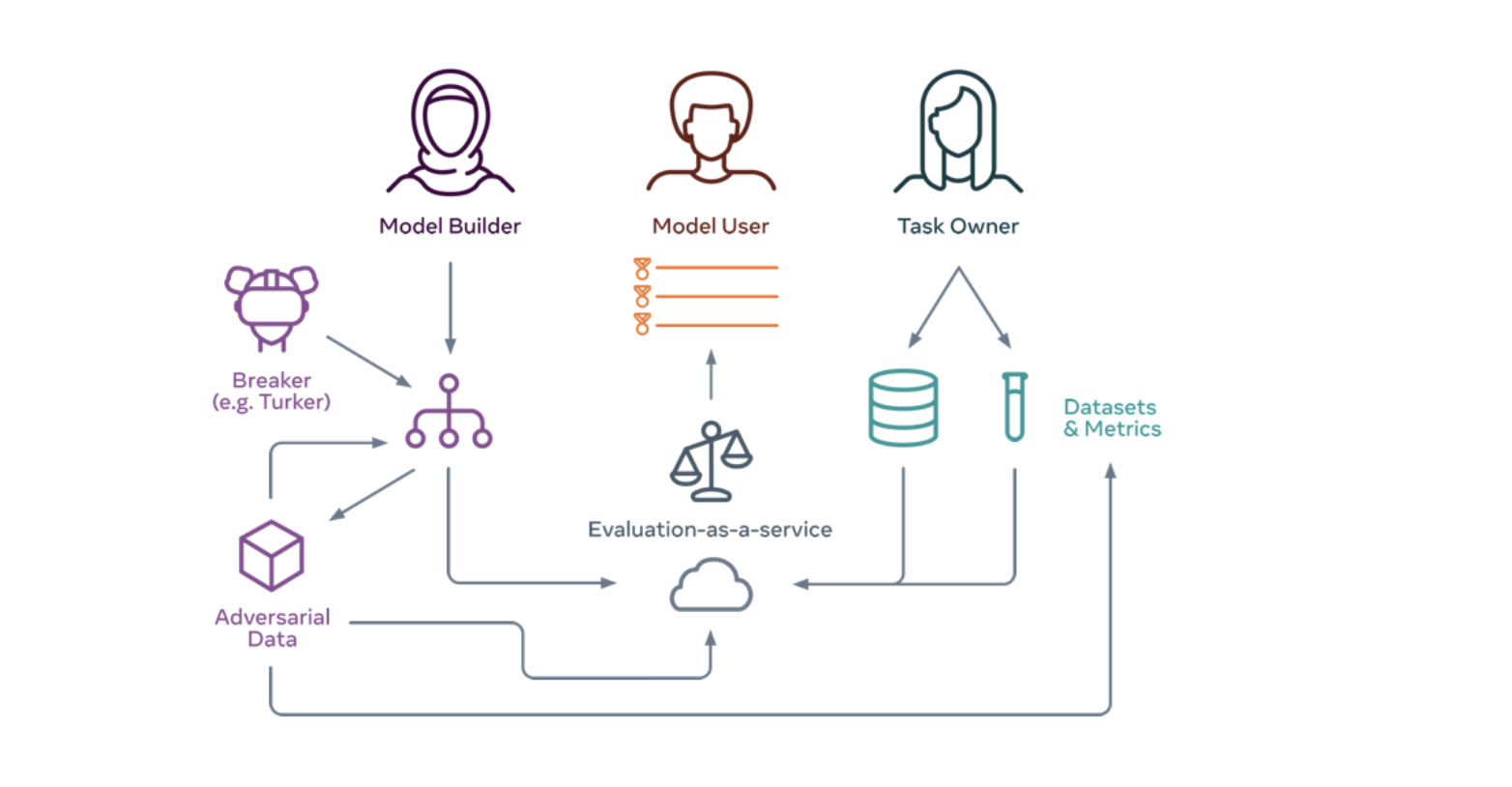
Dynatask is a highly flexible and customizable feature platform. For defining the task settings, each task will have one or more than one owner. From a list of evaluation indicators/metrics, they will be able to select the required ones, including accuracy, robustness, fairness, compute, and memory. Anyone could upload models to task’s evaluation cloud which has the scores and other metrics computation set up on selected data sets. After uploading the model, computation and evaluation, they can be moved in the loop for dynamic data collection and human-in-the-loop evaluation. Task owners amy also be able to collect data via the web interface on dynabench.org or with annotators (such as Mechanical Turk).
Step by step illustration of different components:
- Step 1: Log into your Dynabench account and fill out the “Request new task” form on your profile page.
- Step 2:Once approved, you will have a dedicated task page and corresponding admin dashboard that you control, as the task owner.
- Step 3: On the dashboard, choose the existing datasets that you want to evaluate models on when they are uploaded, along with the metrics you want to use for evaluation.
- Step 4: Next, submit baseline models, or ask the community to submit them.
- Step 5: If you then want to collect a new round of dynamic adversarial data, where annotators are asked to create examples that fool the model, you can upload new contexts to the system and start collecting data through the task owner interface.
- Step 6: Once you have enough data and find that training on the data helps improve the system, you can upload better models and then put those in the data collection loop to build even stronger ones.
Source: https://ai.facebook.com/blog/dynatask-a-new-paradigm-of-ai-benchmarking-is-now-available-for-the-ai-community/
Suggested
Credit: Source link
Comments are closed.