Feel Risky to Train Your Language Model on Restricted Data? Meet SILO: A New Language Model that Manages Risk-Performance Tradeoffs During Inference
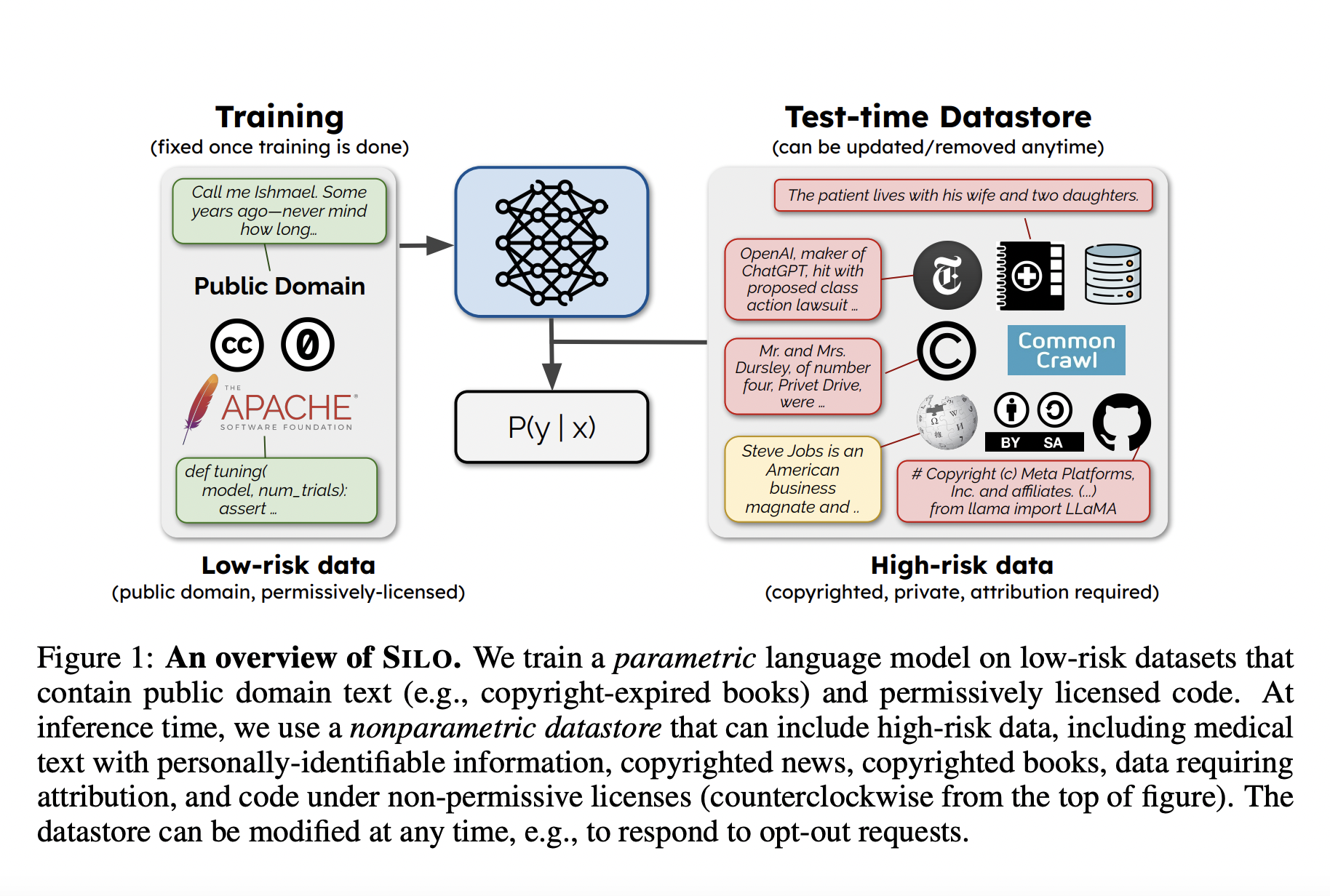
Legal concerns have been raised about massive language models (LMs) because they are often trained on copyrighted content. The inherent tradeoff between legal risk and model performance lies at the heart of this topic. Using just permissively licensed or publicly available data for training has a severe negative impact on accuracy. Since common LM corpora encompass a wider range of issues, this constraint stems from the rarity of permissive data and its tightness to sources like copyright-expired books, government records, and permissively licensed code.
A new study by the University of Washington, UC Berkeley, and Allen Institute for AI show that splitting training data into parametric and nonparametric subsets improves the risk-performance tradeoff. The team trains LM parameters on low-risk data and feeds them into a nonparametric component (a datastore) that is only used during inference. High-risk data can be retrieved from nonparametric datastores to enhance model predictions outside the training phase. The model developers can completely remove their data from the datastore down to the level of individual examples, and the datastore is easily updatable at any moment. This method also assigns credit to data contributors by attributing model predictions down to the sentence level. Thanks to these updated features, the model can now be more accurately aligned with various data-use restrictions. Parametric models, conversely, make it impossible to get rid of high-risk data once training is complete, and it’s also hard to attribute data at scale.
They developed SILO, a novel nonparametric language model to implement their suggestion. OPEN LICENSE CORPUS (OLC)—a novel pretraining corpus for the parametric component of SILO is rich in various domains. Its distribution is skewed heavily toward code and government text, making it unlike other pretraining corpora. Because of this, they now face the extreme domain generalization problem of trying to generalize a model trained on very narrow domains. Three 1.3B-parameter LMs are trained on different subsets of OLC, and then a test-time datastore that can incorporate high-risk data is built, and its contents are retrieved and used in inference. A retrieval-in-context approach (RIC-LM) that retrieves text blocks and feeds them to the parametric LM in context is contrasted with a nearest-neighbors approach (kNN-LM) that employs a nonparametric next-token prediction function.
Perplexity in language modeling is measured across 14 domains, including in-domain and OLC-specific data. Here, the researchers evaluate SILO against Pythia, a parametric LM that shares some features with SILO but was developed primarily for use with high-risk data. They first confirm the difficulty of extremely generalizing domains by demonstrating that parametric-only SILO performs competitively on domains covered by OLC but poorly out of the domain. However, this problem is solved by supplementing SILO with an inference-time datastore. While both kNN-LM and RIC-LM considerably increase out-of-domain performance, the findings show that kNN-LM generalizes better, allowing SILO to close the gap with the Pythia baseline by an average of 90% across all domains. Analysis reveals that the nonparametric next-token prediction in kNN-LM is resistant to domain shift and that kNN-LM greatly benefits from growing the data store.
Overall, this work indicates that expanding the size of the datastore and further improving the nonparametric model can likely close the remaining gaps in the few domains where SILO has not yet achieved Pythia performance levels.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.