Fondant AI Releases Fondant-25M Dataset of Image-Text Pairs with a Creative Commons License
Handling and analysis of vast amounts of data is called Large-scale data processing. It involves extracting valuable insights, making informed decisions, and solving complex problems. It is crucial in various fields, including business, science, healthcare, and more. The choice of tools and methods depends on the specific requirements of the data processing task and the available resources. Programming languages like Python, Java, and Scala are often used for large-scale data processing. In this context, frameworks like Apache Flink, Apache Kafka, and Apache Storm are also valuable.
Researchers have built a new open-source framework called Fondant to simplify and speed up large-scale data processing. It has various embedded tools to download, explore, and process data. It also includes components for downloading through URLs and downloading images.
The current challenge with generative AI, such as Stable Diffusion and Dall-E, is trained on hundreds of millions of images from the public Internet, including copyrighted work. This creates legal risks and uncertainties for users of these images and is unfair toward copyright holders who may not want their proprietary work reproduced without consent.
To tackle it, researchers have developed a data-processing pipeline to create 500 million datasets of Creative Commons images to train the latent diffusion image generation models. Data-processing pipelines are steps and tasks designed to collect, process, and move data from one source to another, where it can be stored and analyzed for various purposes.
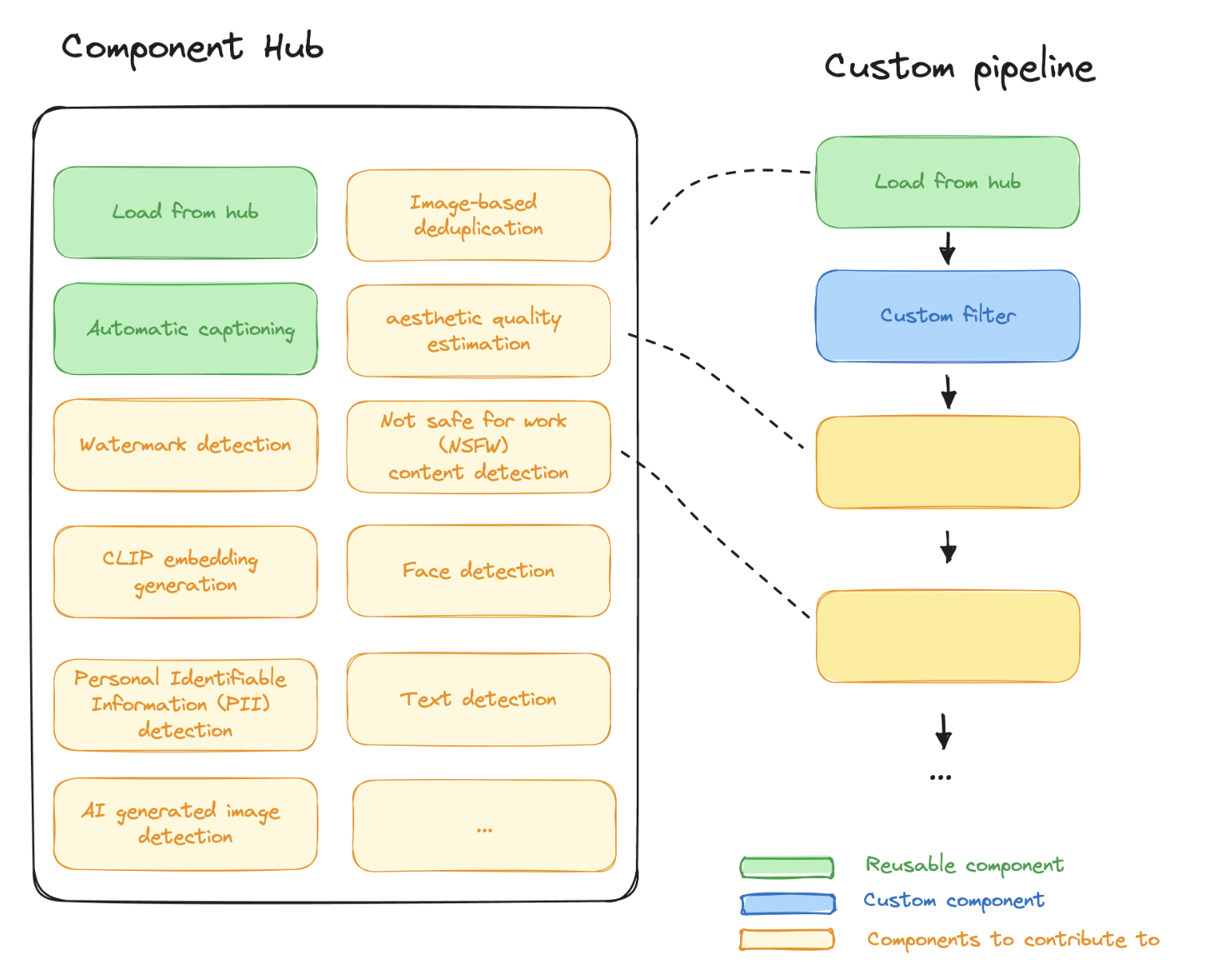
Creating custom data processing pipelines involves several steps, and the specific approach may vary depending on your data sources, processing requirements, and tools. Researchers use the method of building blocks to create custom pipelines. They designed the Fondant pipelines to mix reusable components and custom components. They further deployed it in a production environment and set up automation for regular data processing.
Fondant-cc-25m contains 25 million image URLs with their Creative Commons license information that can be easily accessed in one go! The researchers have released a detailed step-by-step installation program for local users. To execute the pipelines locally, users must have Docker installed in their systems with at least 8GB of RAM allocated to their Docker environment.
As the released dataset may contain sensitive personal information, the researchers only designed the datasets to include public, non-personal information in support of conducting and publishing their open-access research. They say the filtering pipeline for the dataset is still in progress, and they are willing to have contributions from other researchers to contribute to creating anonymous pipelines for the project. Researchers say that in the future, they want to add different components like Image-based deduplication, automatic captioning, visual quality estimation, watermark detection, face detection, text detection, and much more!
Check out the Blog Article and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.