Fooling Forensic Classifiers: The Power of Generative Models in Adversarial Face Generation
Recent advancements in Deep Learning (DL), specifically in the field of Generative Adversarial Networks (GAN), have facilitated the generation of highly realistic and diverse human faces that do not exist in reality. While these artificially created faces have found numerous beneficial applications in areas such as video games, the make-up industry, and computer-aided designs, they pose significant security and ethical concerns when misused.
The misuse of synthetic or fake faces can lead to severe repercussions. For example, there have been instances where GAN-generated face images were employed in the US elections to create fraudulent social media profiles, allowing for the rapid dissemination of misinformation among targeted groups. Similarly, a 17-year-old high school student managed to deceive Twitter into verifying a fake profile picture of a US Congress candidate, utilizing a powerful generative model known as StyleGAN2. These incidents underscore the potential risks associated with the misuse of GAN-generated face images, highlighting the importance of addressing the security and ethical implications of their usage.
To address the issue of synthetically-generated fake faces produced by GANs, several methods have been proposed to differentiate between fake GAN-generated faces and real ones. The findings reported in these studies suggest that simple, supervised deep learning-based classifiers are often highly effective in detecting GAN-generated images. These classifiers are commonly referred to as forensic classifiers or models.
However, an intelligent attacker could manipulate these fake images using adversarial machine learning techniques to evade forensic classifiers while maintaining high visual quality. A recent research explores this direction by demonstrating that adversarial exploration of the generative model’s manifold through latent space optimization can generate realistic faces that are misclassified by targeted forensic detectors. Furthermore, they show that the resulting adversarial fake faces exhibit fewer artifacts compared to traditional adversarial attacks that impose constraints on image space.
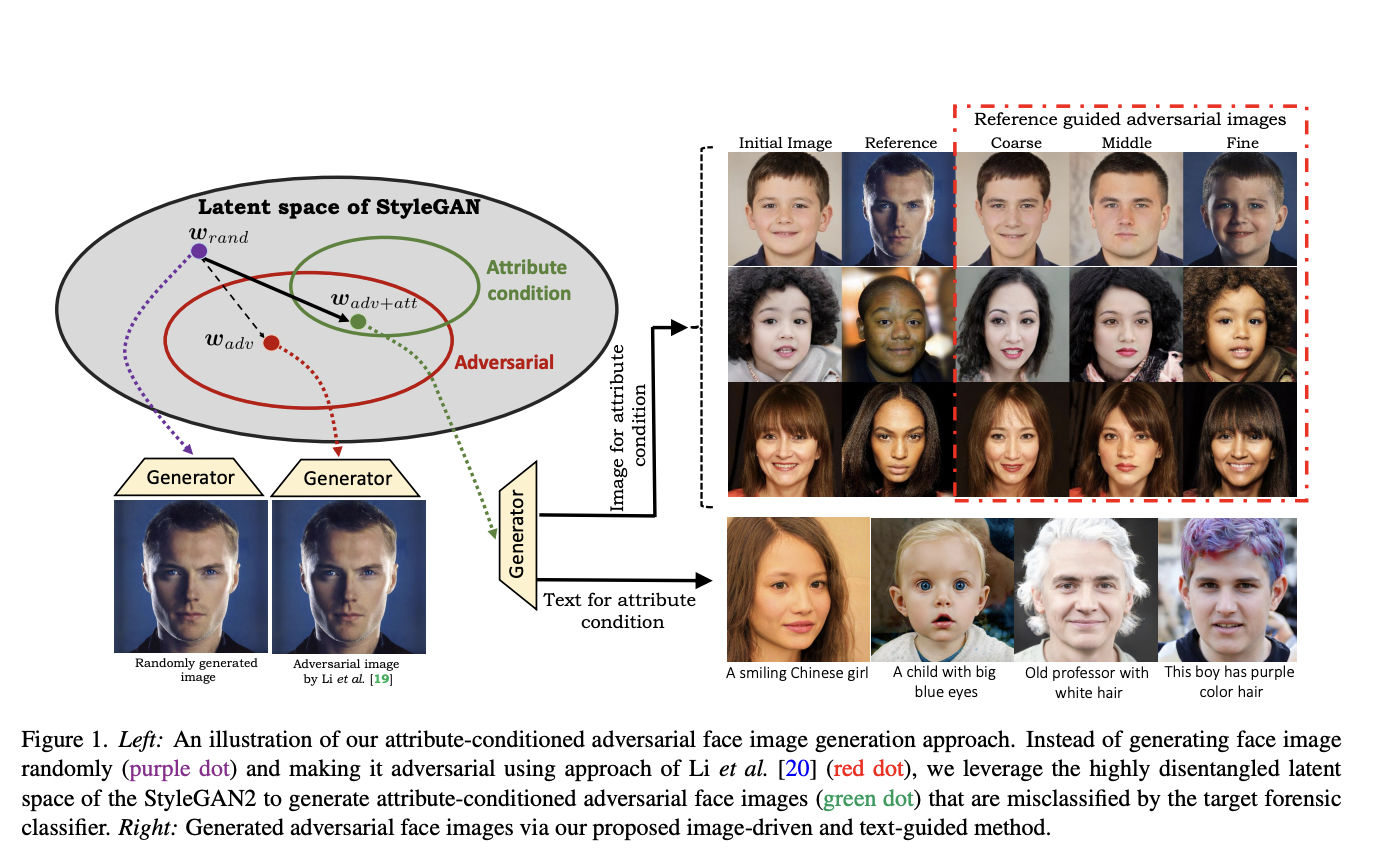
This work, however, does possess a significant limitation. Namely, it lacks the capability to control the attributes of the generated adversarial faces, such as skin color, expression, or age. Controlling these face attributes is crucial for attackers who aim to swiftly disseminate false propaganda through social media platforms, specifically targeting certain ethnic or age groups.
Given the potential implications, it becomes imperative for image forensics researchers to delve into and develop attribute-conditioned attacks. By doing so, they can uncover the vulnerabilities of existing forensic face classifiers and ultimately work towards designing effective defense mechanisms in the future. The research explained in this article aims to address the pressing need for attribute control in adversarial attacks, ensuring a comprehensive understanding of the vulnerabilities and promoting the development of robust countermeasures.
The overview of the proposed method is reported below.
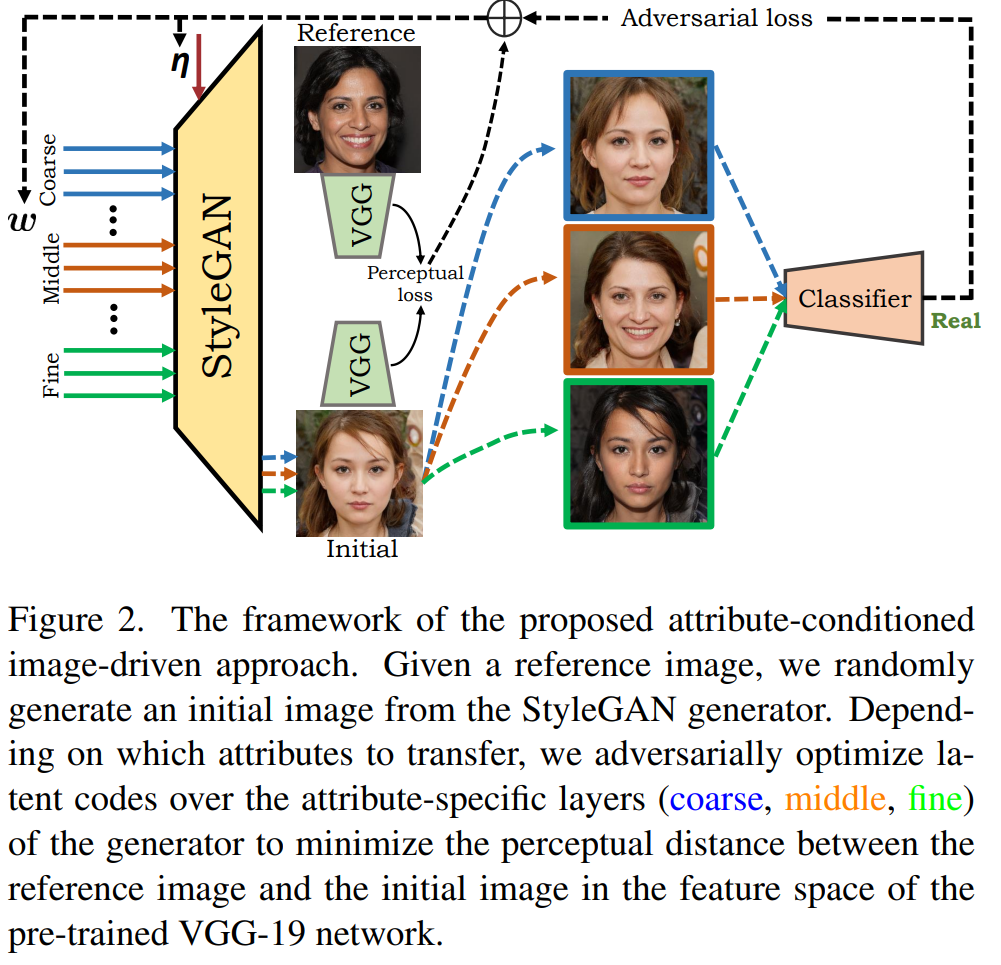
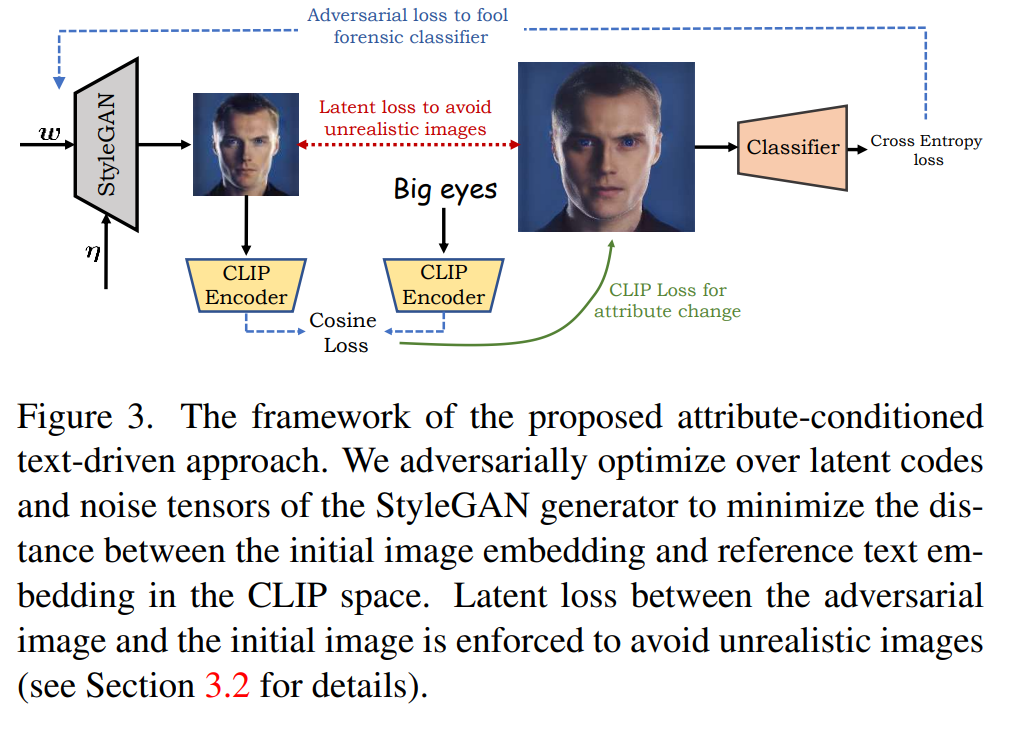
Two architectures are presented, one related to attribute-based generation and one for text generation. Indeed, driven either by images or guided by text, the proposed method aims to generate realistic adversarial fake faces that can deceive forensic face detectors. The technique utilizes the highly disentangled latent space of StyleGAN2 to construct attribute-conditioned unrestricted attacks within a unified framework.
Specifically, an efficient algorithm is introduced to adversarially optimize attribute-specific latent variables to generate a fake face that exhibits the attributes present in a given reference image. This process effectively transfers desired coarse or fine-grained details from the reference image to the generated fake image. Semantic attributes are transferred from a provided reference image when performing image-based attribute conditioning. This is achieved by searching the adversarial space while guided by perceptual loss, enabling the transfer of desired attributes to the generated fake image.
Additionally, the joint image-text representation capabilities of Contrastive Language-Image Pre-training (CLIP) are leveraged for generating fake faces based on provided text descriptions. This allows for enforcing consistency between the generated adversarial face image and the accompanying text description. By utilizing the text-guided feature space of CLIP, the method searches for adversarial latent codes within this feature space, enabling the generation of fake faces that align with the attributes described in the accompanying text.
Some results available in the paper are presented below.

This was the summary of a novel AI technique to generate realistic adversarial faces to evade forensic classifiers. If you are interested and want to learn more about this work, you can find further information by clicking on the links below.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.