Forget Haaland, We Have a New Wonderkid: This AI Approach Trains a Bipedal Robot with Deep RL to Teach Agile Football Skills
Robots have come a long way since their inception. They turned from simple automated machines to highly sophisticated, artificially intelligent things that can now carry out a range of complex tasks. Today, robots are becoming increasingly involved in our daily lives, and their capabilities are only getting better with time. From robots that help us clean our homes to those that assist in surgical procedures, there seems to be no limit to what these technological marvels can achieve.
In fact, some people are even beginning to develop emotional connections with their robotic companions. Take, for example, the story of a man who bought a robotic vacuum cleaner and gave it a name. He became so attached to his little robotic friend that he would talk to it, pat it on the head, and even leave it treats. It’s safe to say that robots are quickly becoming an integral part of our lives and society.
Though, we are not yet done with robots. We still need them to get better at understanding the physical world in a flexible way, not just the exact way we told them. Embodied intelligence has been a long-term goal of AI and robotics researchers. Animals and humans are masters of their bodies, able to perform complex movements and use their bodies to effect complex outcomes in the world. In the end, we are still trying to mimic nature in our research, and we have a long way to go to achieve this level of flexibility in our gadgets.
Recently the progress in learning-based approaches has accelerated in designing intelligent embodied agents with sophisticated motor capabilities. Deep reinforcement learning (deep RL) has been the key contributor to this advancement. It has proven capable of solving complex motor control problems for simulated characters, including perception-driven whole-body control or multi-agent behaviors.
The biggest challenge in developing an intelligent embodied agent is the need for them to have a flexible movement set. They need to be agile and understand their environment. As the research has focused on tackling this problem in recent years, there was a need for a way to evaluate how well the proposed approaches perform in this context. That’s why sports like football have become a testbed for developing sophisticated, long-horizon, multi-skill behaviors that can be composed, adapt to different environmental contexts, and are safe to be executed on real robots.
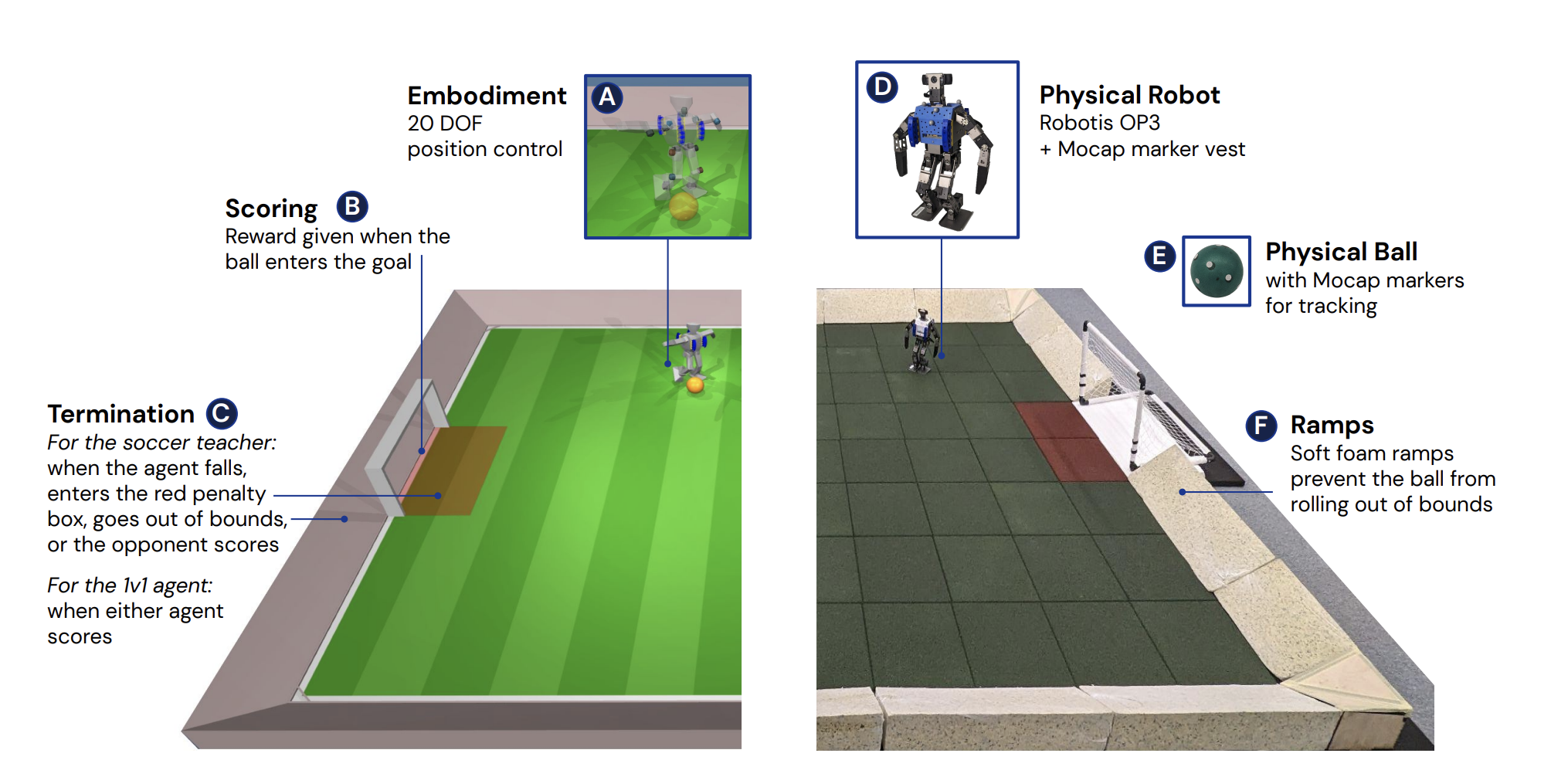
Football (soccer for our American readers) requires a diverse set of highly agile and dynamic movements, including running, turning, side stepping, kicking, passing, fall recovery, object interaction, and many more, which need to be composed in diverse ways. That’s why it is the best way to demonstrate how advanced your robots have become—time to meet the star of the show, OP3 Soccer, from DeepMind.
OP3 Soccer is a project with the goal of training a robot to play soccer by composing a wide range of skills such as walking, kicking, scoring, and defending into long-term strategic behavior. However, training such a robot is a difficult task as it is not possible to give the reward for scoring a goal only. Because doing so will not result in the desired behaviors due to exploration and learning transferable behaviors challenges.
Therefore, OP3 Soccer found a smart way to tackle these challenges. The training is split into two stages. In the first stage, teacher policies are trained for two specific skills: getting up from the ground and scoring against an untrained opponent. In the second stage, the teacher policies are used to regularize the agent while it learns to play against increasingly strong opponents. The use of self-play enables the opponents to increase in strength as the agent improves, prompting further improvement.

To ensure a smooth transfer from simulation to the real-world, domain randomization, random perturbations, sensor noise, and delays are incorporated into the training in simulation. This approach enables the robot to learn tactics and strategies, such as defending and anticipating the opponent’s moves.
Overall, OP3 Soccer uses deep RL to synthesize dynamic and agile context-adaptive movement skills that are composed by the agent in a natural and fluent manner into complex, long-horizon behavior. The behavior of the agent emerged through a combination of skill reuse and end-to-end training with simple rewards in a multi-agent setting. The agents were trained in simulation and transferred to the robot, demonstrating that sim-to-real transfer is possible even for low-cost, miniature humanoid robots.
Check out the Paper and Project. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.