From Text to Visuals: How AWS AI Labs and University of Waterloo Are Changing the Game with MAGID
In human-computer interaction, multimodal systems that utilize text and images promise a more natural and engaging way for machines to communicate with humans. Such systems, however, are heavily dependent on datasets that combine these elements meaningfully. Traditional methods for creating these datasets have often fallen short, relying on static image databases with limited variety or raising significant privacy and quality concerns when sourcing images from the real world.
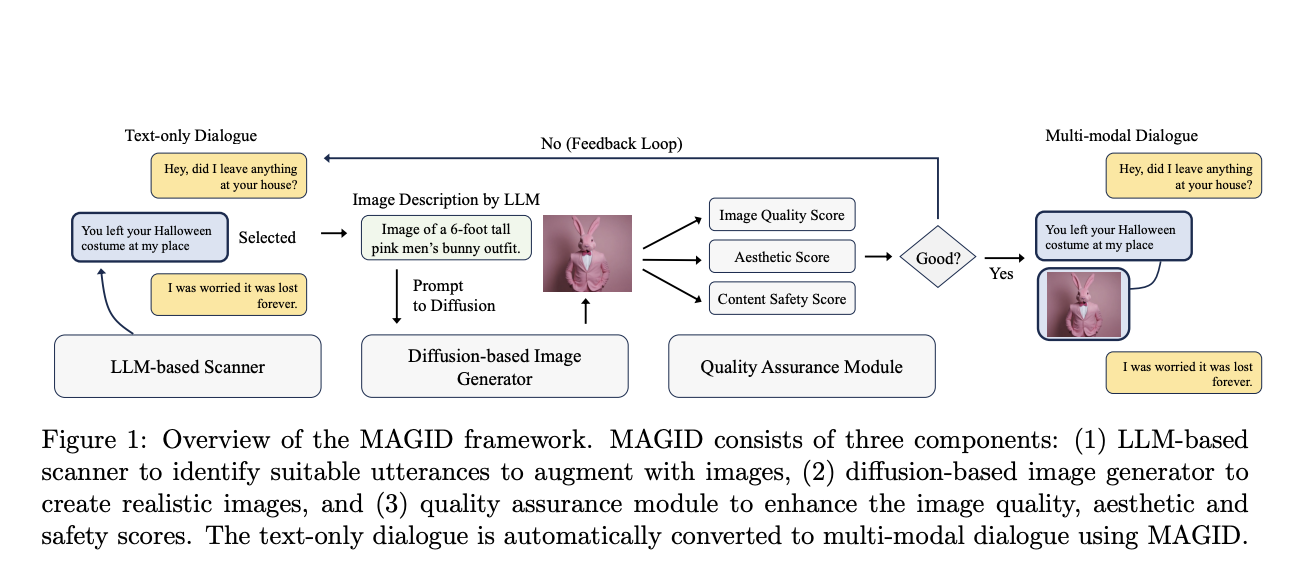
Introducing MAGID (Multimodal Augmented Generative Images Dialogues), a groundbreaking framework born out of the collaborative efforts of researchers from the esteemed University of Waterloo and the innovative AWS AI Labs. This cutting-edge approach is set to redefine the creation of multimodal dialogues by seamlessly integrating diverse and high-quality synthetic images with text dialogues. The essence of MAGID lies in its ability to transform text-only conversations into rich, multimodal interactions without the pitfalls of traditional dataset augmentation techniques.
MAGID’s heart is a meticulously designed pipeline consisting of three core components:
- An LLM-based scanner
- A diffusion-based image generator
- A comprehensive quality assurance module
The process begins with the scanner identifying text utterances within dialogues that would benefit from visual augmentation. This selection is critical, as it determines the contextual relevance of the images to be generated.
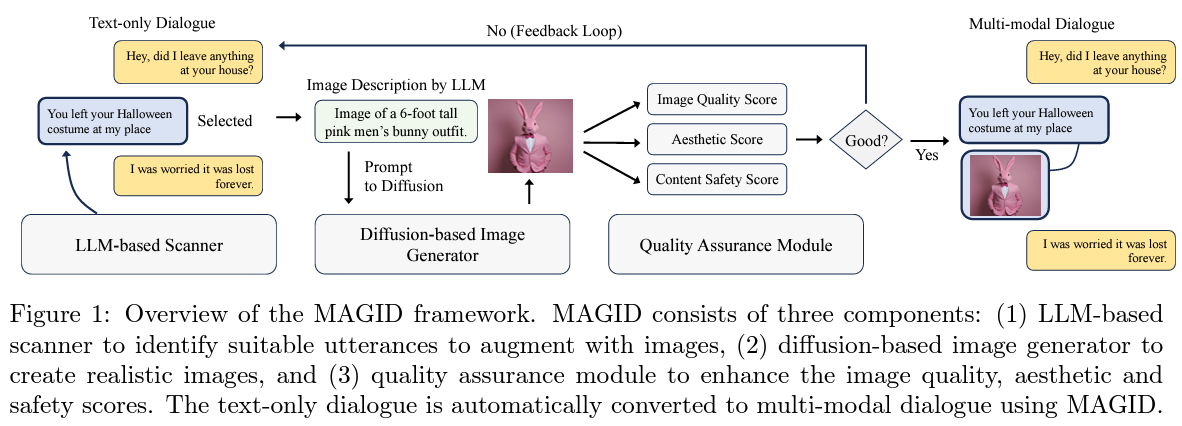
Following the selection, the diffusion model takes center stage, generating images that complement the chosen utterances and enrich the overall dialogue. This model excels at producing varied and contextually aligned images, drawing from various visual concepts to ensure the generated dialogues reflect the diversity of real-world conversations.
However, the generation of images is only part of the equation. MAGID incorporates a meticulously designed and comprehensive quality assurance module to ensure the augmented dialogues’ utility and integrity. This module evaluates the generated images on several fronts, including their alignment with the corresponding text, aesthetic quality, and adherence to safety standards. It ensures that each image matches the text in context and content, meets high visual standards, and avoids inappropriate content.
The efficacy of MAGID was rigorously tested against state-of-the-art baselines and through comprehensive human evaluations. The results were nothing short of remarkable, with MAGID not only matching but often surpassing other methods in creating multimodal dialogues that were engaging, informative, and aesthetically pleasing. Specifically, human evaluators consistently rated MAGID-generated dialogues as superior, particularly noting the relevance and quality of the images when compared to those produced by retrieval-based methods. Including diverse and contextually aligned images significantly enhanced the dialogues’ realism and engagement, as evidenced by MAGID’s favorable comparison to real datasets in human evaluation metrics.
MAGID offers a powerful solution to the longstanding challenges in multimodal dataset generation through its sophisticated blend of generative models and quality assurance. By eschewing reliance on static image databases and mitigating privacy concerns associated with real-world images, MAGID paves the way for creating rich, diverse, and high-quality multimodal dialogues. This advancement is not just a technical achievement but a stepping stone toward realizing the full potential of multimodal interactive systems. As these systems become increasingly integral to our digital lives, frameworks like MAGID, ensure they can evolve in ways that are both innovative and aligned with the nuanced dynamics of human conversation.
In summary, the introduction of MAGID by the team from the University of Waterloo and AWS AI Labs marks a significant leap forward in AI and human-computer interaction. By addressing the critical need for high-quality, diverse multimodal datasets, MAGID enables the development of more sophisticated and engaging multimodal systems. Its ability to generate synthetic dialogues that are virtually indistinguishable from real human conversations underscores the immense potential of AI to bridge the gap between humans and machines, making interactions more natural, enjoyable, and, ultimately, human.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.