From Words to Worlds: Exploring Video Narration With AI Multi-Modal Fine-grained Video Description
Language is the predominant mode of human interaction, offering more than just supplementary details to other faculties like sight and sound. It also serves as a proficient channel for transmitting information, such as using voice-guided navigation to lead us to a specific location. In the case of visually impaired individuals, they can experience a movie by listening to its descriptive audio. The former demonstrates how language can enhance other sensory modes, whereas the latter highlights language’s capacity to convey maximal information in different modalities.
Contemporary efforts in multi-modal modeling strive to establish connections between language and various other senses, encompassing tasks like captioning images or videos, generating textual representations from images or videos, manipulating visual content guided by text, and more.
However, in these undertakings, the language predominantly supplements information concerning other sensory inputs. Consequently, these endeavors often fail to comprehensively depict the intricate exchange of information between different sensory modes. They primarily focus on simplistic linguistic elements, such as one-sentence captions.
Given the brevity of these captions, they only manage to describe prominent entities and actions. Consequently, the information conveyed through these captions is considerably limited compared to the wealth of information present in other sensory modalities. This discrepancy results in a notable loss of information when attempting to translate information from other sensory realms into language.
In this study, researchers see language as a way to share information in multi-modal modeling. They create a new task called “Fine-grained Audible Video Description” (FAVD), which differs from regular video captioning. Usually, short captions of videos refer to the main parts. FAVD instead requests models to describe videos more like how people would, starting with a quick summary and then adding more and more detailed information. This approach retains a sounder portion of video information within the language framework.
Since videos enclose visual and auditory signals, the FAVD task also incorporates audio descriptions to enhance the comprehensive depiction. To support the execution of this task, a new benchmark named Fine-grained Audible Video Description Benchmark (FAVDBench) has been constructed for supervised training. FAVDBench is a collection of over 11,000 video clips from YouTube, curated across more than 70 real-life categories. Annotations include concise one-sentence summaries, followed by 4-6 detailed sentences about visual aspects and 1-2 sentences about audio, offering a comprehensive dataset.
To effectively evaluate the FAVD task, two novel metrics have been devised. The first metric, termed EntityScore, evaluates the transfer of information from videos to descriptions by measuring the comprehensiveness of entities within the visual descriptions. The second metric, AudioScore, quantifies the quality of audio descriptions within the feature space of a pre-trained audio-visual-language model.
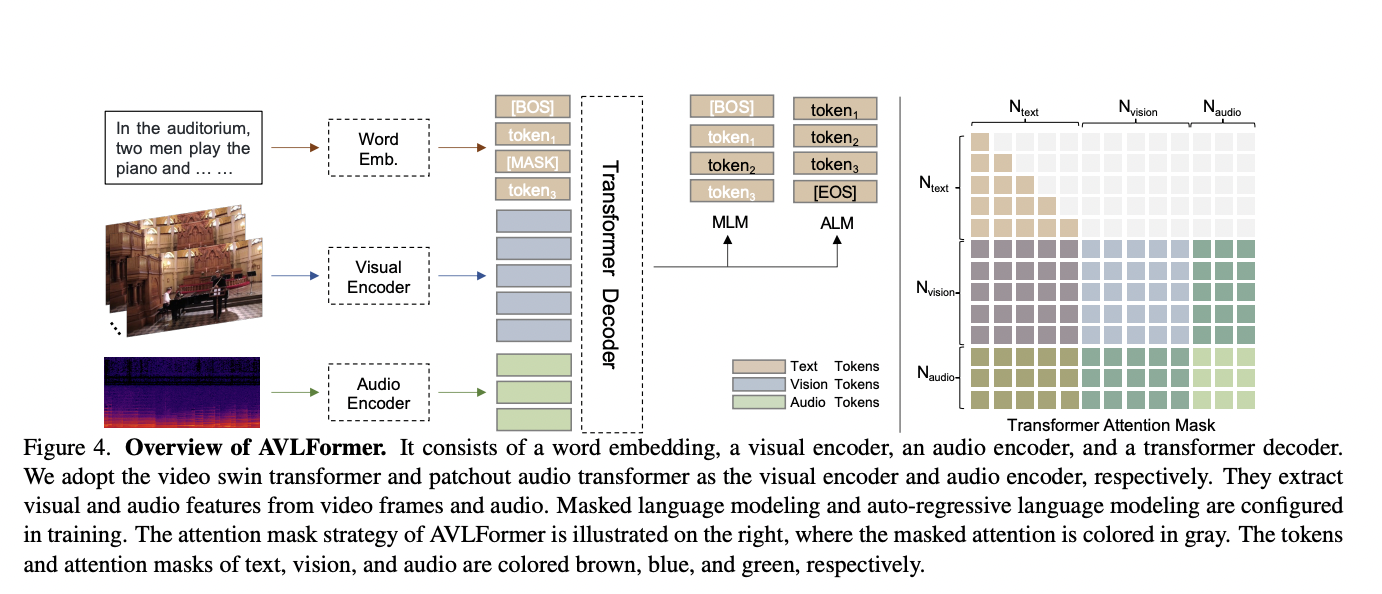
The researchers furnish a foundational model for the freshly introduced task. This model builds upon an established end-to-end video captioning framework, supplemented by an additional audio branch. Moreover, an expansion is made from a visual-language transformer to an audio-visual-language transformer (AVLFormer). AVLFormer is in the form of encoder-decoder structures as depicted below.

Visual and audio encoders are adapted to process the video clips and audio, respectively, enabling the amalgamation of multi-modal tokens. The visual encoder relies on the video swin transformer, while the audio encoder exploits the patchout audio transformer. These components extract visual and audio features from video frames and audio data. Other components, such as masked language modeling and auto-regressive language modeling, are incorporated during training. Taking inspiration from previous video captioning models, AVLFormer also employs textual descriptions as input. It uses a word tokenizer and a linear embedding to convert the text into a specific format. The transformer processes this multi-modal information and outputs a fine-detailed description of the videos provided as input.
Some examples of qualitative results and comparison with state-of-the-art approaches are reported below.

In conclusion, the researchers propose FAVD, a new video captioning task for fine-grained audible video descriptions, and FAVDBench, a novel benchmark for supervised training. Furthermore, they designed a new transformer-based baseline model, AVLFormer, to address the FAVD task. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.