Georgia Tech Researchers Introduce ZipIt: A General Method for Merging Two Arbitrary Models of the Same Architecture that Incorporates Two Simple Strategies
The discipline of computer vision has flourished under the rule of huge models with an ever-increasing number of parameters ever since AlexNet popularised deep learning. Today’s benchmark challenges include classification with tens of thousands of classes, precise object identification, quick instance segmentation, realistic picture production, and many more vision issues that were originally thought to be impossible or extremely difficult. These deep models are quite effective, but they have a potentially fatal flaw: they can only carry out the task they were trained on. They encounter several possible problems while attempting to increase the capabilities of an existing model. They risk catastrophic forgetting if they try to train the model on a different assignment.
They frequently discover that the same model does not generalize to samples from outside the domain when they examine it using different data without adaption. To lessen these consequences, they can try so-called “intervention” tactics, although these sometimes need for further training, which can be costly. For many activities, there are already a tonne of finely honed models available. Despite the fact that these models frequently have the same basic structural foundation, there is currently no technique for combining models developed for distinct objectives. Either we’re forced to assemble them, which involves assessing each model separately, or we’re forced to jointly train a new model through distillation, both of which can be prohibitively costly, especially given the current trend of ever-increasing architecture and dataset sizes.
Instead, researchers from the Georgia Institute of Technology considered it would be wonderful if they could just “zip” these models together, eliminating the need for extra training and allowing any duplicate characteristics to be calculated only once. In the vision community, the concept of integrating several models into one has just begun to gain popularity. To increase accuracy and resilience, Model Soups can incorporate numerous models that have been fine-tuned using the same pretrained initialization. With a large accuracy loss, Git Re-Basin generalises further to models trained on the same data but with different initializations. By including additional parameters and, where necessary, modifying model batch norms, REPAIR enhances Git Re-Basin.
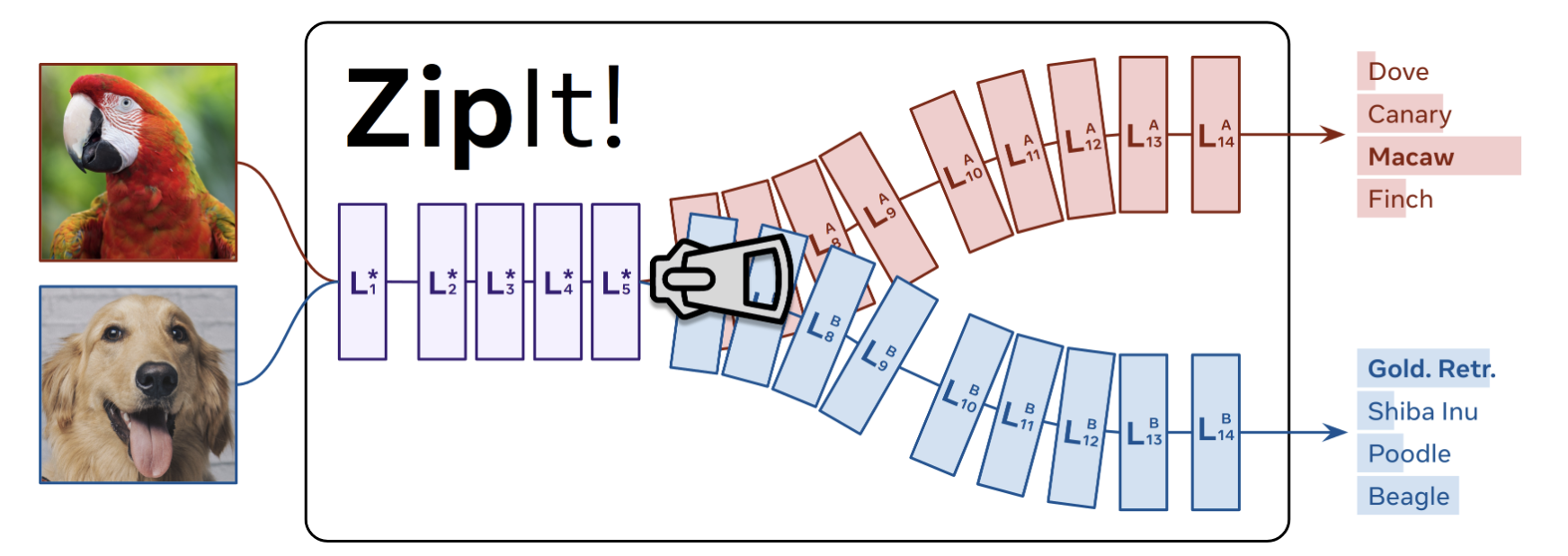
All of these techniques, meanwhile, only merge models created for the same objective. This study pushes this line of research to its logical conclusion by integrating models with various initializations that were developed for quite different goals. Despite the fact that this is a really difficult problem, they use two straightforward methods to solve it. They begin by noting that earlier research has concentrated on permuting one model into the other when combining them. Assuming that most of the characteristics between the two models are redundant, this results in a 1:1 mapping between them. They cannot rely just on permutation, as this isn’t always true for models trained on various tasks. Instead, they make use of redundant parts of every model.
They generalize model merging to permit “zipping” any feature combination both within and between each model in order to achieve this. On some datasets, they discover that this alone increases accuracy by up to 20% when compared to the Git Re-basin plus a more robust permutation baseline that they implement. Second, current techniques combine the whole network. This may work for models that are quite similar and were trained in the same environment, but as a network becomes older, the properties of models that were trained on different tasks become less linked. They introduce partial zipping, where they only “zip” up to a certain layer, to address this. They then automatically create a multi-head model by feeding the intermediate outputs of the merged model to the remaining unmerged layers of the original networks.
This can increase accuracy by over 15% while still keeping the majority of the layers merged, depending on how challenging each assignment is. They introduce ZipIt!, a universal technique for “zipping” together any number of models trained on various tasks into a single multitask model without further training by combining both of these approaches. They may combine models with the same architecture, merge features inside each model, and partially zip them to form a multi-task model by devising a generic graph-based technique for merging and unmerging. By integrating models trained on fully different datasets, completely distinct sets of CIFAR, and ImageNet categories, they demonstrate the efficacy of their method while exceeding previous research by a wide margin. They then analyze and ablate their method’s performance in various instances. They have described their pipeline elaborately in the GitHub repository. The code and datasets also have been made available.
Check out the Research Paper and Code. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.