Google AI and Tel Aviv Researchers Introduce FriendlyCore: A Machine Learning Framework For Computing Differentially Private Aggregations
Data analysis revolves around the central goal of aggregating metrics. The aggregation should be conducted in secret when the data points match personally identifiable information, such as the records or activities of specific users. Differential privacy (DP) is a method that restricts each data point’s impact on the conclusion of the computation. Hence it has become the most frequently acknowledged approach to individual privacy.
Although differentially private algorithms are theoretically possible, they are typically less efficient and accurate in practice than their non-private counterparts. In particular, the requirement of differential privacy is a worst-case kind of requirement. It mandates that the privacy requirement holds for any two neighboring datasets, regardless of how they were constructed, even if they are not sampled from any distribution, which leads to a significant loss of accuracy. Meaning that “unlikely points” that have a major impact on the aggregation must be considered in the privacy analysis.
Recent research by Google and Tel Aviv University provides a generic framework for the preliminary processing of the data to ensure its friendliness. When it is known that the data is “friendly,” the private aggregation stage can be carried out without considering potentially influential “unfriendly” elements. Because the aggregation stage is no longer constrained to perform in the original “worst-case” setting, the proposed method has the potential to significantly reduce the amount of noise introduced at this stage.
Initially, the researchers formally define the conditions under which a dataset can be considered friendly. These conditions will vary depending on the type of aggregation required, but they will always include datasets for which the sensitivity of the aggregate is low. For instance, if the sum is average, “friendly” should include compact datasets.
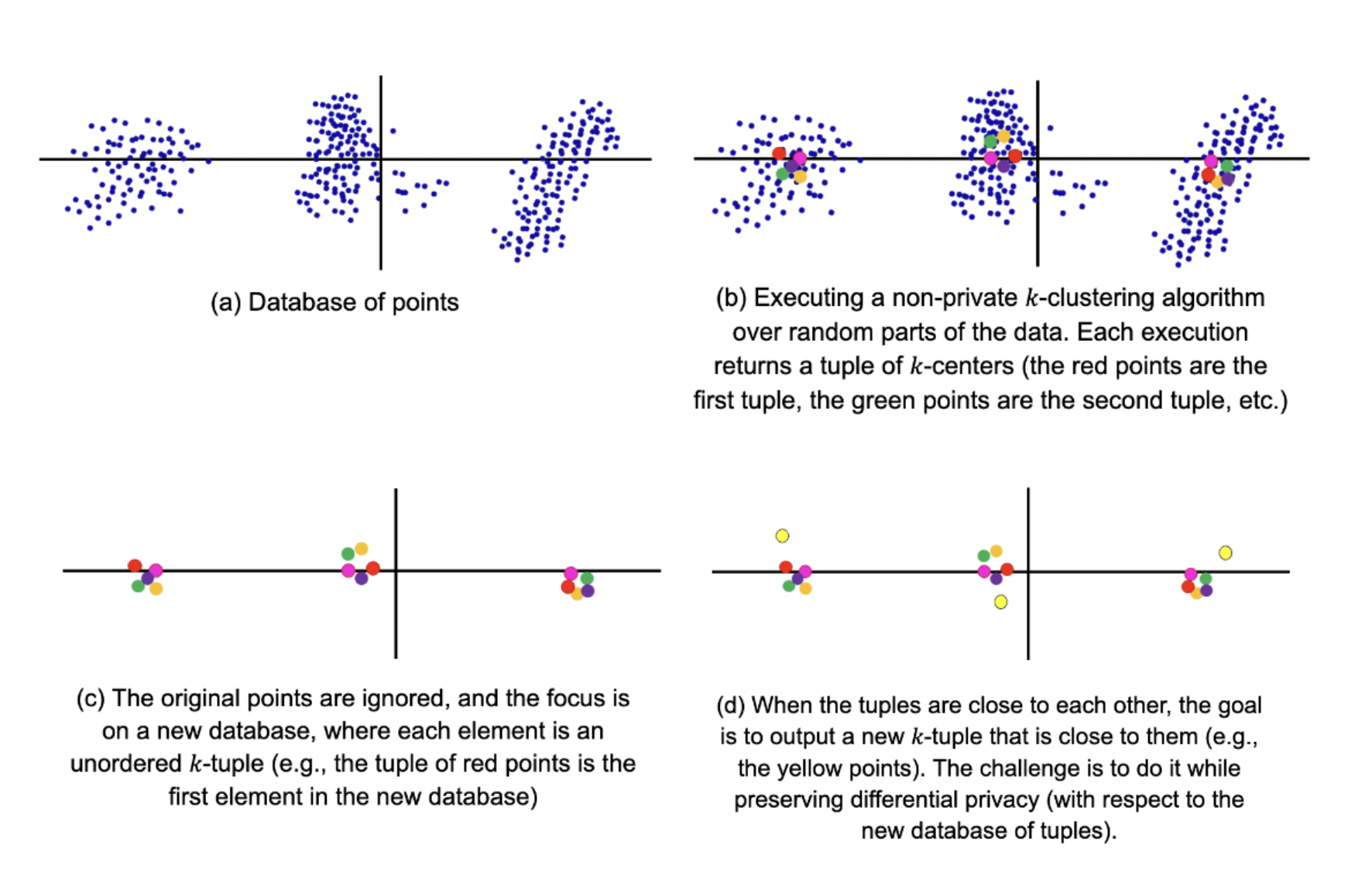
The team developed the FriendlyCore filter that reliably extracts a sizable friendly subset (the core) from the input. The algorithm is designed to meet a pair of criteria:
- It must eliminate outliers to retain only elements close to many others in the core.
- For nearby datasets that differ by a single element, the filter outputs all elements except y with almost the same probability. Cores derived from these nearby databases can be joined together cooperatively.
Then the team created the Friendly DP algorithm, which, by introducing less noise into the total, meets a less stringent definition of privacy. By applying a benevolent DP aggregation method to the core generated by a filter satisfying the aforementioned conditions, the team proved that the resulting composition is differentially private in the conventional sense. Clustering and discovering the covariance matrix of a Gaussian distribution are further uses for this aggregation approach.
The researchers used the zero-Concentrated Differential Privacy (zCDP) model to test the efficacy of the FriendlyCore-based algorithms. 800 samples were taken from a Gaussian distribution with an unknown mean through their paces. As a benchmark, the researchers looked at how it stacked against the CoinPress algorithm. CoinPress, in contrast to FriendlyCore, necessitates a norm of the mean upper bound of R. The proposed method is independent of the upper bound and dimension parameters and hence outperforms CoinPress.
The team also evaluated the efficacy of their proprietary k-means clustering technology by comparing it to another recursive locality-sensitive hashing technique, LSH clustering. Each experiment was repeated 30 times. FriendlyCore frequently fails and produces inaccurate results for tiny values of n (the number of samples from the mixture). Yet as n grows, the proposed technique becomes more likely to succeed (as the created tuples get closer to each other), producing very accurate results, while LSH-clustering falls behind. Even without a distinct division into clusters, FriendlyCore performs well on huge datasets.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.