Google AI Introduces a Method Called Task-Level Mixture-of-Experts (TaskMoE), that Takes Advantage of the Quality Gains of Model Scaling While Still Being Efficient to Serve
Large-scale language model scaling has resulted in considerable quality gains in natural language understanding (T5), generation (GPT-3), and multilingual neural machine translation (M4). One typical method for creating a more extensive model is to increase the depth (number of layers) and breadth (layer dimensionality), essentially expanding the network’s existing dimensions. Such dense models take an input sequence (split into smaller components known as tokens) and route each token through the whole network, activating every layer and parameter. While these big, dense models have shown cutting-edge outcomes on various natural language processing (NLP) applications, their training costs rise linearly with model size.
Building sparsely activated models based on a mixture of experts (MoE) (e.g., GShard-M4 or GLaM), where each token supplied to the network follows a distinct subnetwork by bypassing some of the model parameters, is an alternative and more common technique. Small router networks that are educated with the rest decide how to distribute input tokens to each subnetwork (the “experts”). This enables researchers to increase the model size (and hence performance) without increasing training costs proportionally.
While this is an efficient technique for training, delivering tokens from a long sequence to several experts increases the computing cost of inference since the experts must be dispersed among a large number of accelerators. Serving the 1.2T parameter GLaM model, for example, needs 256 TPU-v3 chips. The number of processors required to service an MoE model, like dense models, increases linearly with model size, increasing computing needs while also resulting in considerable communication overhead and extra technical complexity.
An approach called Task-level Mixture-of-Experts (TaskMoE) in “Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference” was discovered, taking advantage of the quality advantages of model scaling while being efficient to service. The strategy is to train a big multi-task model. Smaller stand-alone per-task subnetworks suited for inference were extracted while maintaining model quality and considerably reducing inference latency. This strategy is more successful for multilingual neural machine translation (NMT) than previous expert mixture models and models compressed via knowledge distillation.
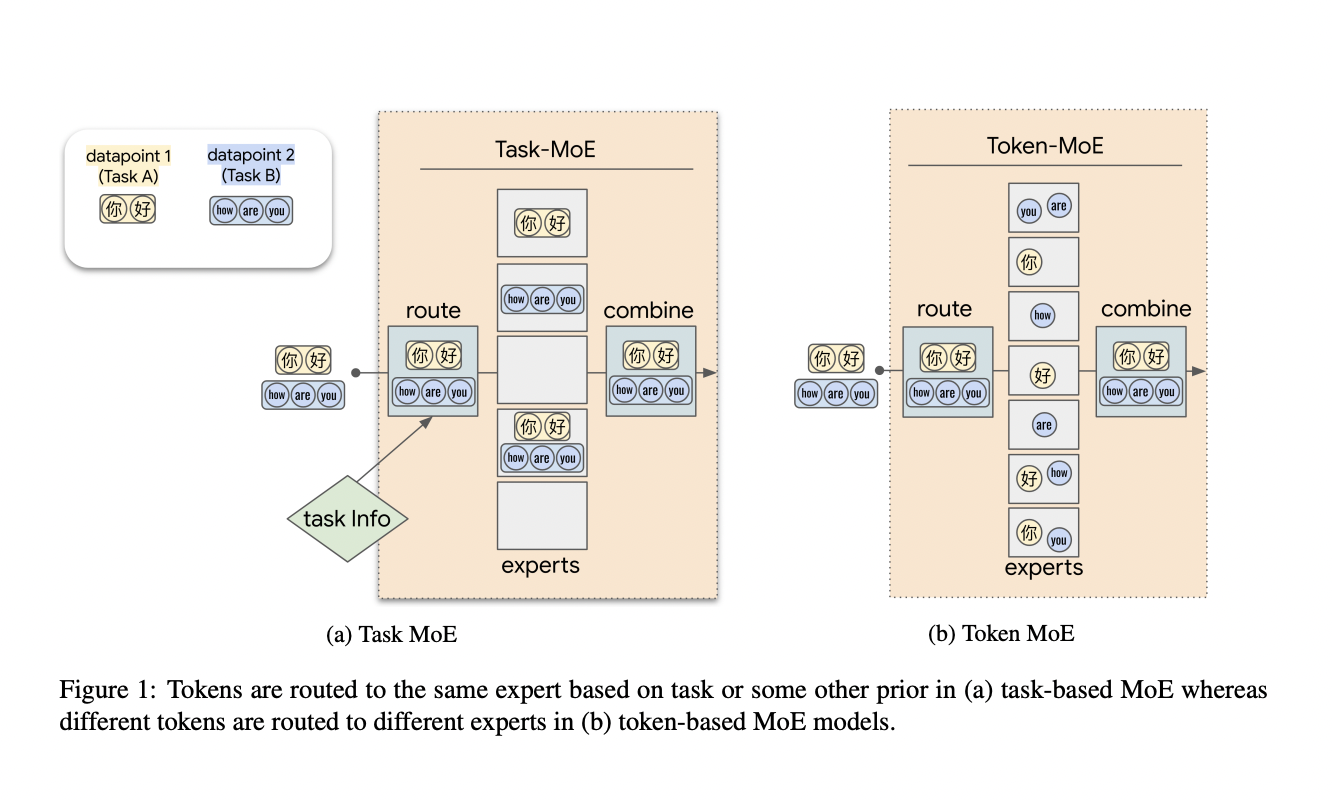
Using Task Information to Train Large Sparsely Activated Models
A sparsely active model was trained in which router networks learn to deliver tokens of each task-specific input to the model’s associated subnetworks. Every token of a particular language is routed to the same subnetwork in the case of multilingual NMT. This contrasts to the sparsely gated mixture of expert models (e.g., TokenMoE), in which router networks learn to deliver distinct tokens in input to different subnetworks independently of the task.
By Extracting Subnetworks, distillation can be avoided.
The difference in training between TaskMoE and models like TokenMoE affects how inference is approached. TokenMoE is computationally costly during inference because it follows the practice of distributing tokens of the same task to numerous experts at both training and inference time.
During training and inference, a smaller subnetwork was assigned to a single task identity in TaskMoE. Subnetworks during inference were extracted by removing unneeded experts for each job. TaskMoE and its variations allowed to train a single extensive multi-task network and then employ a distinct subnetwork for each task at inference time without needing different compression algorithms after training. Below is the figure on how to train a TaskMoE network and then extract per-task subnetworks for inference.
Models were trained based on the Transformer architecture to showcase this method. Similar to GShard-M4 and GLaM, every other transformer layer’s feedforward network was replaced with a Mixture-of-Experts (MoE) layer composed of many identical feedforward networks, the “experts.” The routing network, trained with the rest of the model, maintains the task identity for all input tokens for each task and selects a particular number of experts per layer (two in this example) to build the task-specific subnetwork. TaskMoE and TokenMoE are both 6 layers deep, but with 32 experts for each MoE layer and a total of 533M parameters. Models using publicly available WMT datasets contain over 431M phrases from 30 distinct language families and scripts.
Results
To highlight the benefit of utilizing TaskMoE during inference, compare throughput, or the number of tokens decoded per second. Once the subnetwork for each job is recovered, TaskMoE is 7x smaller than the 533M parameter TokenMoE model and can be serviced on a single TPUv3 core rather than the 64 cores required by TokenMoE.
TaskMoE models have twice the peak throughput of TokenMoE models. Furthermore, in the TokenMoE model, 25% of the inference time is spent on inter-device communication, whereas TaskMoE spends almost no time communicating.
Knowledge distillation, in which a big teacher model trains a smaller student model to match the teacher’s performance, is a common way of constructing a smaller network that nevertheless performs well. This strategy, however, comes at the expense of additional computation required to instruct the student from the teacher. As a result, compare TaskMoE to a baseline TokenMoE model that has been compressed through knowledge distillation. The compressed TokenMoE model is the same size as the per-task subnetwork retrieved from TaskMoE.
TaskMoE outperforms a distilled TokenMoE model by 2.1 BLEU on average across all languages in our multilingual translation model, in addition to being a more straightforward strategy that requires no further training. Distillation preserves 43% of the performance advantages obtained by scaling a dense multilingual model to a TokenMoE, but extracting the smaller subnetwork from the TaskMoE model leads to no quality loss.
The growing requirement to train models capable of generalizing across different tasks and modalities only adds to the demand for scaling models. However, serving these huge models remains a significant difficulty. Efficiently deploying big models is an important area of study, and TaskMoE is a promising step toward more inference-friendly algorithms that maintain scaling-related quality benefits.
For a deep read, refer to google’s post or research paper.
Suggested

Credit: Source link
Comments are closed.