Google AI Introduces a Novel Clustering Algorithm that Effectively Combines the Scalability Benefits of Embedding Models with the Quality of Cross-Attention Models
Clustering serves as a fundamental and widespread challenge in the realms of data mining and unsupervised machine learning. Its objective is to assemble similar items into distinct groups. There are two types of clustering: metric clustering and graph clustering. Metric clustering involves using a specified metric space, which establishes the distances between various data points. These distances serve as the basis for grouping data points, with the clustering process relying on the separation between them. On the other hand, graph clustering employs a given graph that connects similar data points through edges. The clustering process then organizes these data points into groups based on the connections existing between them.
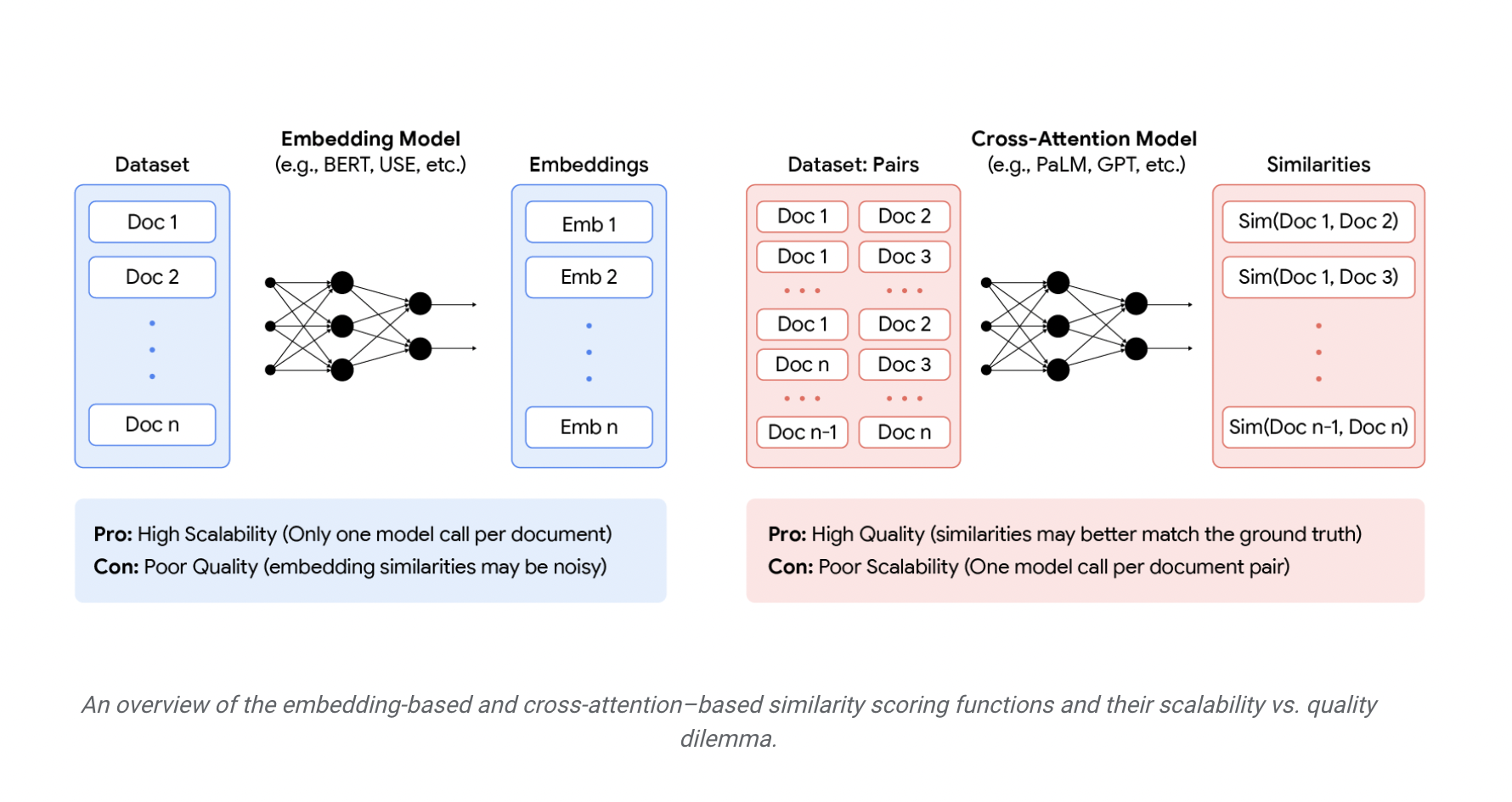
One clustering strategy involves embedding models like BERT or RoBERTa to formulate a metric clustering problem. Alternatively, another approach utilizes cross-attention (CA) models such as PaLM or GPT to establish a graph clustering problem. While CA models can be highly precise similarity scores, constructing the input graph may necessitate an impractical quadratic number of inference calls to the model. Conversely, the distances between embeddings produced by embedding models can effectively define a metric space.
Researchers introduced a clustering algorithm named KwikBucks: Correlation Clustering with Cheap-Weak and Expensive-Strong Signals. This innovative algorithm effectively merges the scalability advantages of embedding models with the superior quality CA models provide. The algorithm for graph clustering possesses query access to both the CA model and the embedding model. However, a constraint is imposed on the number of queries made to the CA model. This algorithm employs the CA model to address edge queries and takes advantage of unrestricted access to similarity scores from the embedding model.
The process involves first identifying a set of documents known as centers that do not share similarity edges and then creating clusters based on these centers. A method named the combo similarity oracle is presented to balance the high-quality information offered by Cross-Attention (CA) models and the effective operations of embedding models.
In this methodology, the embedding model is employed to guide the selection of queries directed to the CA model. When presented with a set of center documents and a target document, the combo similarity oracle mechanism generates an output by identifying a center from the set similar to the target document if such similarity exists. The combo similarity oracle proves valuable in conserving the allocated budget by restricting the number of query calls to the CA model during the selection of centers and the formation of clusters. This is achieved by initially ranking centers based on their embedding similarity to the target document and subsequently querying the CA model for the identified pair.
Following the initial clustering, there is also a subsequent post-processing step in which clusters undergo merging. This merging occurs when a strong connection is identified between two clusters, specifically when the number of connecting edges exceeds the number of missing edges between the two clusters.
The researchers tested the algorithm on several datasets with different features. The performance of the algorithm is tested against the two best-performing baseline algorithms using a variety of models based on embeddings and cross-attention.
The suggested query-efficient correlation clustering approach can only use the Cross-Attention (CA) model and functions within budgeted clustering limits. Using the k-nearest neighbor graph (kNN), spectral clustering is applied to accomplish this. By using embedding-based similarity to query the CA model for each vertex’s k-nearest neighbors, this graph is created.
The evaluation involves the calculation of precision and recall. Precision quantifies the percentage of similar pairs among all co-clustered pairs, while recall measures the percentage of co-clustered similar pairs among all similar pairs.
Check out the Paper and Google AI Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.