Google AI Introduces a Novel MoE Routing Algorithm Called Expert Choice (EC) That can Achieve Optimal Load Balancing in an MoE System While Allowing Heterogeneity in Token-to-Expert Mapping
The number of model parameters in the network significantly influences a neural network’s ability to process information. Recent academic work has largely focused on discovering more efficient ways to increase model parameters because the latest technological advancements necessitate more parameters. This increase in model parameters like dataset size and training time has effectively improved the performance of NLP models and computer vision systems.
Mixture-of-experts (MoE), a conditional computation technique that activates network components on a per-example basis, is a method that significantly boosts model capacity without proportionally increasing computation. With sparsely-activated MoE models, the number of parameters can be significantly increased while the computation required for a given token or sample remains somewhat constant. On the contrary, a subpar expert routing method can result in undertraining and under- or overspecializing some experts. Previous research focused on assigning a set number of experts to each token regardless of how important each token is compared to others.
Addressing this issue in their latest research paper titled ‘Mixture-of-Experts with Expert Choice Routing,’ Google AI researchers suggest an advanced MoE routing algorithm called Expert Choice (EC). This innovative method can enable heterogeneity in token-to-expert mapping while achieving optimal load balancing in an MoE system. Instead of choosing the top k experts in classic MoE systems, this method chooses the top k tokens, which makes it possible to route each token to a different expert with a different bucket size. Token-based routing and other routing strategies perform poorly in traditional MoE networks compared to EC’s training efficiency and downstream task results. The team’s paper has also been presented at NeurIPS 2022.
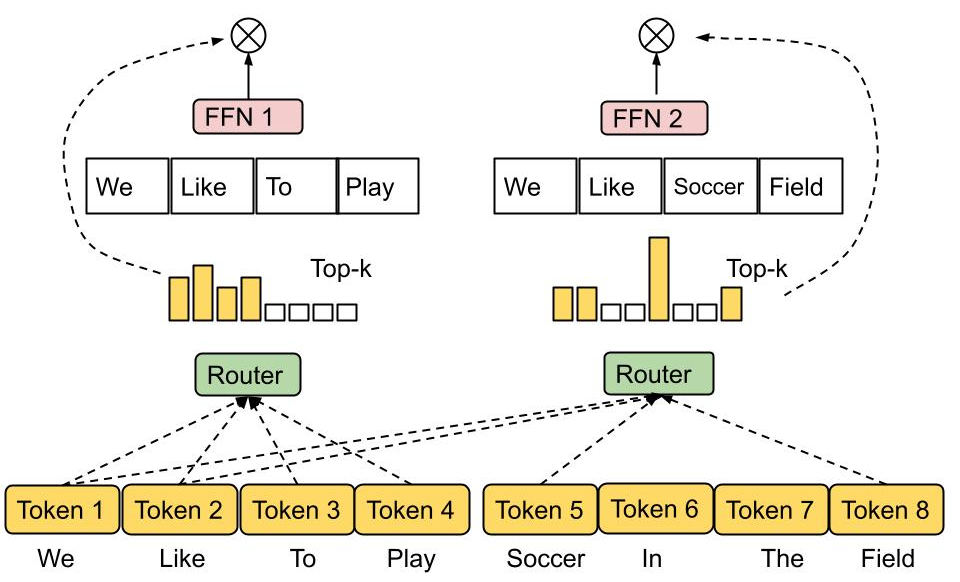
The core of MoE routing employs several experts, and only a small number of these experts are activated for each input token. The next step is to select and optimize a gating network to direct each token to the best appropriate expert. MoE can be classified as sparse or dense in how the tokens are mapped to experts. When routing each token, a sparse MoE only chooses a portion of the experts, which helps lower computing costs compared to a dense MoE. This token choice routing technique has been utilized in numerous earlier works, including Google’s GLaM and V-MoE (which employ top-k token routing with sparsely gated MoE). The problem with this independent token-picking method is that it frequently results in underutilization and an unbalanced load on the experts. In earlier research, additional auxiliary losses were utilized as regularization to avoid routing too many tokens to a single expert. Nevertheless, this technique did not give fruitful results. Moreover, most earlier works utilize a top-k function to assign a fixed number of experts to each token without taking into account the relative value and difficulty of various tokens.
Google’s heterogenous MoE was created to address the problems mentioned earlier. The top-k tokens are awarded the experts with a specified buffer capacity rather than letting tokens choose the top-k experts. This approach is a step forward compared to traditional MoE approaches, as it ensures load balancing and allows a fluctuating number of experts for a single token. Moreover, it achieves significant improvements in training effectiveness and downstream performance. A token-to-expert score matrix indicates the token-to-expert affinity and is used in EC routing to decide routing decisions. This matrix shows the probability that a specific token in a batch of input sequences will be routed to a specific expert.
In the overall workflow, the dense feedforward layer of a Transformer-based network, which requires the most computational resources, is used to apply an MoE and a gating function. Each expert uses the top-k function along the token dimension to select the most pertinent tokens after the token-to-expert score matrix has been established. In order to produce a hidden value with an additional expert dimension, a permutation function is also used depending on the token’s created indexes. For all experts to run the same computational kernel simultaneously on a subset of tokens, the data is divided among several experts.
The researchers concluded that their recently developed strategy enhances training convergence time by more than 2x after carefully analyzing pre-training speedups using the same computational resources as past studies. The heterogeneous mixture-of-experts method performs better in fine-tuning 11 chosen tasks in the GLUE and SuperGLUE benchmarks for the same computational cost. In comparison, the method beats the T5 dense model in 7 out of the 11 tasks for a lower activation cost. With simple algorithmic advances, Google Research’s Expert Choice routing technique enables heterogeneous MoE. The group expects their work to serve as a springboard for future developments in this field at the application and system levels.
Check out the paper and reference article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.