Google AI Introduces A Novel Reinforcement Learning (RL) Training Paradigm, ‘ActorQ,’ To Speed Up Actor-Learner Distributed RL Training
Several sequential decision-making challenges, like robotics, gaming, nuclear physics, balloon navigation, etc., have been successfully addressed using deep reinforcement learning. However, despite its potential, prolonged training times are one of its limitations. Although the present method for accelerating RL training on challenging problems uses distributed training to scale up to thousands of processing nodes, it still necessitates the employment of substantial hardware resources. This increases the cost of RL training while also having a negative impact on the environment. However, several recent studies show that performance enhancements on already-existing technology can lessen the training and inference processes’ carbon footprints.
Similar system optimization strategies that can shorten training times, increase hardware efficiency, and cut carbon dioxide emissions are also advantageous for RL. One method is quantization, which involves converting full-precision floating point (FP32) numbers to lower precision (int8) quantities before calculation. It can reduce the cost and bandwidth of memory storage, enabling quicker and more energy-efficient processing. In order to facilitate the deployment of machine learning models at the edge and to speed up training, quantization has been successfully applied to supervised learning. However, quantization has not yet been used in RL training.
Taking a step on this front, Google Research introduced a new paradigm known as ActorQ in their latest publication, “QuaRL: Quantization for Fast and Environmentally Sustainable Reinforcement Learning.” ActorQ applies quantization to speed up RL training by 1.5–5.4 times while preserving performance. Additionally, research shows that the carbon footprint is significantly decreased by a factor of 1.9-3.8x compared to training in full precision. The study’s findings have also been published in the Transactions of Machine Learning Research journal.
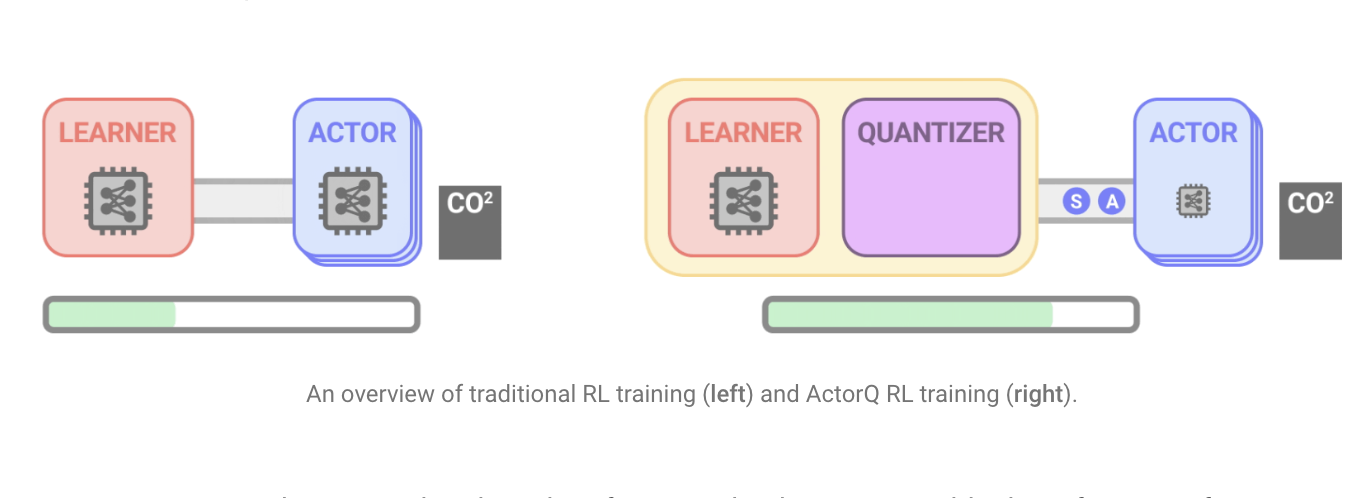
In conventional RL training, an actor is given a learner policy and instructed to explore the environment and gather data samples. The learner then continuously improves the initial policy using the samples the actor collected. ActorQ executes the same pattern, except that the policy update from the learner to the actors is quantized. The actor then uses the int8 quantized policy to explore the environment and gather samples. The researchers also show the two advantages of doing this kind of quantization on RL training. The first is that the policy’s memory footprint is reduced, and the second is that the actors execute inference on the quantized policy to devise actions for a particular state of the environment. The quantized inference process is substantially faster than executing inference with full precision.

ActorQ uses the ACME distributed RL framework and was tested in various settings, including the Deepmind Control Suite and the OpenAI Gym. The team also demonstrates how much faster and more effective D4PG and DQN are. Since DQN is a widely known and accepted RL algorithm and D4PG was the top learning algorithm in ACME for Deepmind Control Suite tasks, it was picked. The training of RL strategies was significantly sped up by the researchers (between 1.5x and 5.41x). Even when actors conduct int8 quantized inference, performance is still maintained, which is more significant. The improvement in the carbon footprint was determined by comparing the carbon emissions generated during training using the FP32 policy to those generated using the int8 policy. The researchers found that, compared to operating with full precision, the quantization of policies reduces carbon emissions anywhere from 1.9x to 3.76x. A reduced carbon footprint directly results from utilizing hardware more effectively through quantization. As RL systems are expanded to run on thousands of distributed hardware cores and accelerators, the absolute carbon reduction (measured in kilos of CO2) can be very considerable.
In summary, ActorQ shows how quantization may be used to improve several RL elements, such as producing high-quality and efficient quantized policies and lowering training costs and carbon emissions. According to Google researchers, making RL training sustainable will be essential for adoption, given the ongoing advances made by RL in problem-solving. In order to achieve effective and environmentally responsible training, they hope their work will be considered a stepping stone in applying quantization to RL training. Future work by the team plans to consider using more aggressive quantization and compression techniques, which could add to the performance and accuracy trade-off that the trained RL strategies have already achieved.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'QuaRL: Quantization for Fast and Environmentally Sutainable Reinforcement Learning'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.