Google AI Introduces A Vision-Only Approach That Aims To Achieve General UI Understanding Completely From Raw Pixels
For UI/UX designers, getting a better computational understanding of user interfaces is the primary step toward achieving more enhanced and intelligent UI behaviors. This is because this mobile UI understanding ultimately helps UI research practitioners enable various interaction tasks such as UI automation and accessibility. Moreover, with the boom of machine learning and deep learning models, researchers have also explored the possibility of using such models to further improve UI quality. For instance, Google Research has previously demonstrated how deep learning-based neural networks can be used to enhance the usability of mobile devices. It is safe to say that using deep learning for UI understanding has tremendous potential to transform end-user experiences and the interaction design practice.
However, most of the previous work in this field made use of UI view hierarchy, which is essentially a structural representation of the mobile UI screen, along with a screenshot. Using view hierarchy as the input directly allows a model to acquire detailed information about UI objects, such as their types, text content, and positions on the screen. This makes it easier for UI researchers to skip challenging visual modeling tasks such as extracting object information from screenshots. However, recent work has revealed that mobile UI view hierarchies often contain inaccurate information about the UI screen. This can be in the form of misaligned structure information or missing object text. Moreover, view hierarchies are also not always accessible. Thus, despite view hierarchy’s short-term advantages over its vision-only counterparts, using it can ultimately hinder the model’s performance and applicability.
On this front, researchers from Google looked into the possibility of only using visual UI screenshots as input, i.e., without including view hierarchies, for UI modeling tasks. Thus, the researchers came up with a vision-only approach named Spotlight in their paper titled, ‘Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus,’ aiming to achieve general UI understanding from raw pixels completely. The researchers use a vision-language model to extract information from the input (screenshot of the UI and a region of interest on the screen) for diverse UI tasks. The vision modality captures what a person would see from a UI screen, and the language modality is essentially token sequences related to the task. The researchers revealed that their approach significantly improves performance accuracy on various UI tasks. Their work has also been accepted for publication at the esteemed ICLR 2023 conference.
The Google researchers decided to proceed with a vision-language model based on the observation that several UI modeling tasks essentially aim to learn a mapping between the UI objects and text. Even though previous research demonstrated that vision-only models generally perform worse than the models using visual and view hierarchy input, visual language models offer some brilliant highlights. Vision-language models with a simple architecture are easily scalable. Moreover, several tasks can be universally represented by combining the two core modalities of vision and language. The Spotlight model intelligently uses these observations with a simple input and output representation. The model input includes a screenshot, the region of interest on the screen, and the text description of the task, and the output is a text description of the region of interest. This allows the model to capture various UI tasks and enables a spectrum of learning strategies and setups, including task-specific finetuning, multi-task learning, and few-shot learning.
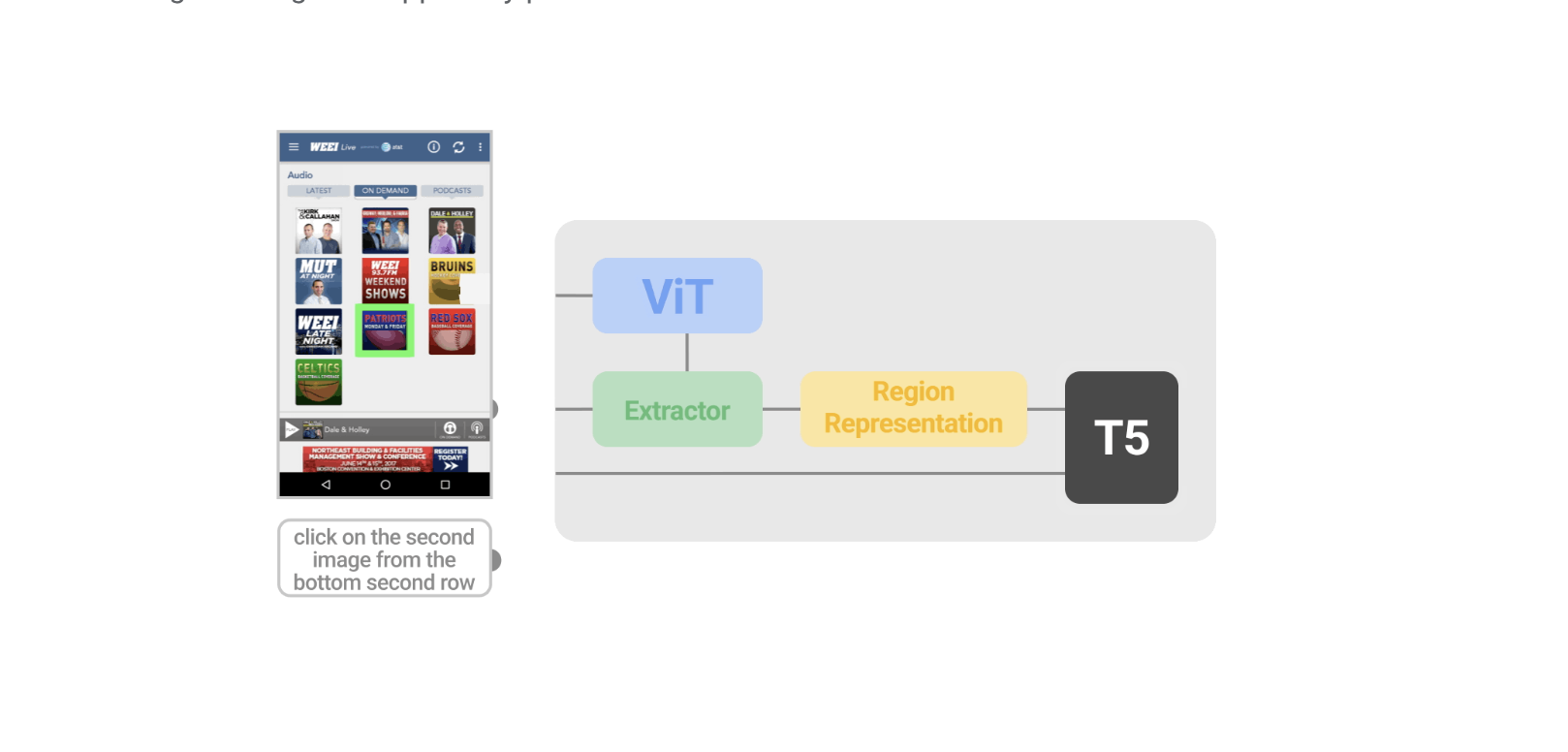
Spotlight leverages existing pretrained architectures such as Vision Transformer (ViT) and Text-To-Text Transfer Transformer (T5). The model was then pretrained using unannotated data consisting of 80 million web pages and about 2.5 million mobile UI screens. Since UI tasks mainly focus on a specific object or area on the screen, the researchers introduce a Focus Region Extractor to their vision-language model. This component helps the model concentrate on the region in light of the screen context. By using ViT encodings based on the region’s bounding box, this Region Summarizer can obtain a latent representation of a screen region. In other terms, each coordinate of the bounding box is first embedded via a multilayer perceptron as a collection of dense vectors and then fed to a Transformer model along their coordinate-type embedding. Cross attention is employed by coordinate queries to attend to screen encodings produced by ViT, and the Transformer’s final attention output is used as the region representation for the subsequent decoding by T5.
According to several experimental evaluations conducted by the researchers, their proposed models achieved new state-of-the-art performance in both single-task and multi-task finetuning for several tasks like widget captioning, screen summarization, command grounding, and tappability prediction. The model outperforms previous methods that use both screenshots and view hierarchies as inputs and is also capable of finetuning multi-task learning and few-shot learning for mobile UI tasks. The ability of the novel vision-language model architecture proposed by Google researchers to quickly scale and generalize to additional applications without requiring architectural changes is one of its most distinguishing features. This vision-only strategy eliminates the requirement for view hierarchy, which has significant shortcomings, as previously noted. Google researchers have high hopes for advancing user interaction and user experience fronts with their Spotlight approach.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.