Google AI Introduces An Important Natural Language Understanding (NLU) Capability Called Natural Language Assessment (NLA)

Everything a person learns, for example, a child learning to walk or a person learning to play guitar, requires assessment. Our educators and coaches mostly play this role. These interactions are unique in terms of their characteristics that set them apart from other forms of dialogue. This assessment is also required in the field of Natural Language processing. But, due to its relative freedom and infrequent adherence to rigid rules for computing spelling, syntax, and semantics, natural language input presents significant difficulty for assessment. This field is yet to be researched properly.
Recently researchers at google research came up with the idea of NLA (Natural language assessment). They tried to explore how machine learning can be used to assess answers such that it facilitates learning. NLA evaluates a user’s answers against a certain set of expectations.
NLA consists of components like the question given to the student, its expectation, and context, which is optional. The answer of the student is then analyzed and assessed against the expectation, and an assessment output is obtained.
Let’s take an example, suppose a student is shown a picture of an animal and asked to tell what animal it is. The expected answer is a platypus. Suppose the student answers that though he is not exactly sure what animal it is, he can tell that it’s a mammal. Though the answer is not precise, it cannot be exactly termed as incorrect. In such a case, NLA would tell us that the student’s answer is too general and he is not exactly sure of his answer.
In addition to noticing the student’s acknowledged hesitation, this kind of subtle assessment can be crucial in aiding pupils in developing conversational skills.
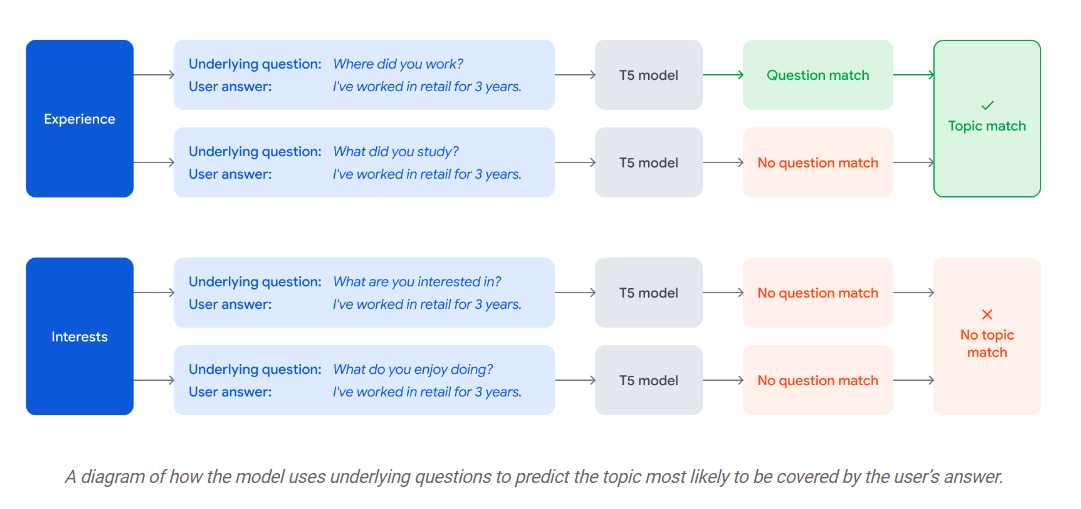
Another important aspect of NLA is topicality. Topicality NLA is a common multi-class task that is simple to train a classifier for using common methods. Though simple, the training data for this task is limited and scarce, and it is very resource-intensive and time-consuming to collect such data for each question and topic.
The researchers found a way to split down each topic into smaller, more easily identifiable parts that can be recognized using large language models (LLMs) with a simple generic tuning.
What they do is that they map each topic to a list of questions, and if a sentence contains an answer to even one of the questions, then it covers that topic.
These underlying questions are created manually and iteratively. Importantly, because these queries are so specific, existing language models (see details below) can represent their semantics.
Thus NLA is a very useful tool and can be used in various scenarios like interview preparations. It has been applied to help job seekers to warm up for interviews.
Check out the Google Source Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Rishabh Jain, is a consulting intern at MarktechPost. He is currently pursuing B.tech in computer sciences from IIIT, Hyderabad. He is a Machine Learning enthusiast and has keen interest in Statistical Methods in artificial intelligence and Data analytics. He is passionate about developing better algorithms for AI.
Credit: Source link
Comments are closed.