Google AI Introduces ‘FLAN’: An Instruction-Tuned Generalizable Language (NLP) Model To Perform Zero-Shot Tasks

To generate meaningful text, a machine learning model needs a lot of knowledge about the world and should have the ability to abstract them. While language models that have been trained to accomplish this are becoming increasingly capable of acquiring this knowledge automatically as they grow, it is unclear how to unlock this knowledge and apply it to specific real-world activities.
Fine-tuning is one well-established method for doing so. It involves training a pretrained model like BERT or T5 on a labeled dataset to adjust it to a downstream job. However, it has a large number of training instances and stored model weights for each downstream job, which is not always feasible, especially for large models.
A recent Google study looks into a simple technique known as instruction fine-tuning, sometimes known as instruction tuning. This entails fine-tuning a model to make it more receptive to performing NLP (Natural language processing) tasks in general rather than a specific task.
The researchers employed instruction tuning to train a model called Fine-tuned LAnguage Net (FLAN). The instruction tuning phase of FLAN takes a few updates compared to the massive amount of computing necessary in pre-training the model. This enables FLAN to carry out a variety of unseen tasks.

Source: https://ai.googleblog.com/2021/10/introducing-flan-more-generalizable.html
Zero-Shot Prompting
When employing language models to solve problems, zero-shot or few-shot prompting is a popular strategy. This method creates a task based on the text that a language model has encountered during training, and then the language model completes the text to generate the solution. For example, a language model might be given the line “The movie review ‘greatest RomCom since Pretty Woman’ is _” to classify the sentiment of a movie review. and be given the option of finishing the phrase with either the word “positive” or “negative.”
However, this method needs careful prompt engineering to design tasks that resemble the model’s data during training. This approach works well on some but not on all tasks and can also confuse practitioners to interact with the model. Such prompting strategies, for example, did not result in a good performance on natural language inference (NLI) tasks, according to the designers of GPT-3 (one of the most widely used language models today).
Instruction Tuning
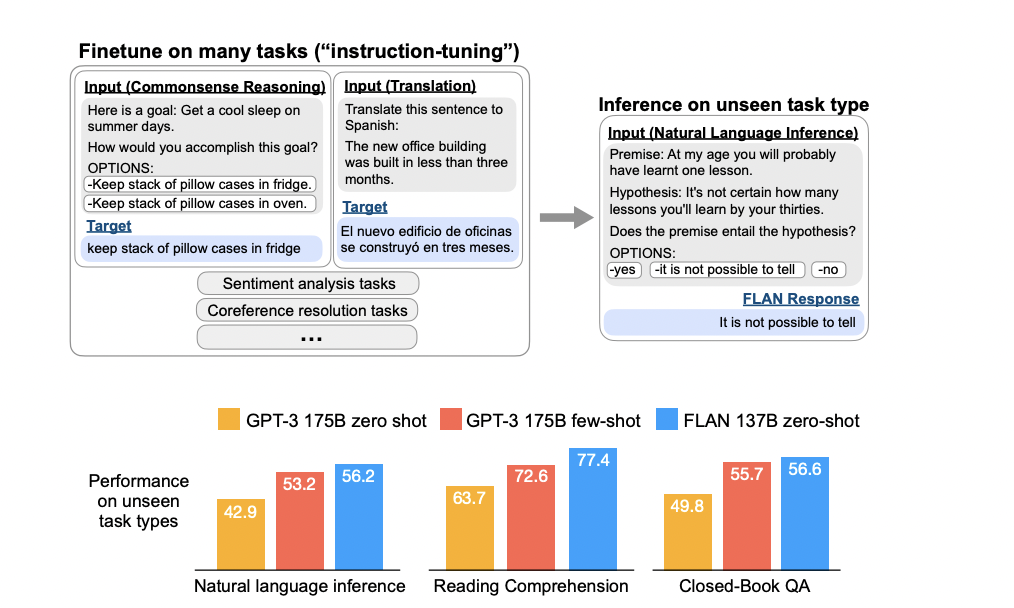
In contrast, FLAN fine-tunes the model using a huge number of different instructions that use a straightforward and intuitive task description, such as “Classify this movie review as favorable or negative,” or “Translate this sentence to Danish.”
The team used templates to convert existing datasets into instructions to fine-tune the model. They suggest that training models on these instructions not only improves its ability to solve the types of instructions it has seen during training but also its overall ability to follow instructions.

Model Evaluation and Performance
The team used established benchmark datasets to evaluate the performance of the model with current models. In addition, they assessed FLAN’s performance without seeing any instances from the dataset during training.
The researchers point out that the performance results could be skewed if the training dataset is too similar to the evaluation dataset. As a result, they organize all datasets into task clusters and hold out the dataset’s training data and the complete task cluster to which the dataset belongs.

They tested FLAN on 25 different tasks and found that it outperforms zero-shot prompting in all but four of them. On 20 of the 25 tasks, the FLAN results were better than zero-shot GPT-3, and on several tasks, they were even better than few-shot GPT-3.

Their findings show that the model scale is critical for its ability to profit from instruction adjustment. The FLAN approach lowers performance at smaller sizes, and it is only at bigger scales that the model can generalize from instructions in the training data to unknown tasks. This could be because models with too few parameters cannot execute a large number of tasks.
FLAN model is the first model that uses instruction tuning at scale and improves the model’s generalization capacity. The team hopes their proposed model will encourage future research into models that can execute previously undiscovered tasks and learn from very little input.
Paper: https://arxiv.org/pdf/2109.01652.pdf
Github: https://github.com/google-research/flan
Source: https://ai.googleblog.com/2021/10/introducing-flan-more-generalizable.html
Suggested
Credit: Source link
Comments are closed.