Google AI Introduces FRMT: A New Dataset And Evaluation Benchmark For Few-Shot Region-Aware Machine Translation
In recent years, machine translation (MT) has made great strides, with outstanding results for many language pairs, particularly those with many parallel data available. Some earlier work has addressed finer-grained distinctions, such as those between regional variations of Arabic or precise levels of politeness in German, even though the MT job is normally given at the broad level of a language (such as Spanish or Hindi). Unfortunately, most existing methods for style-targeted translation rely on large, labeled training corpora, which are often either unavailable or too expensive to generate.
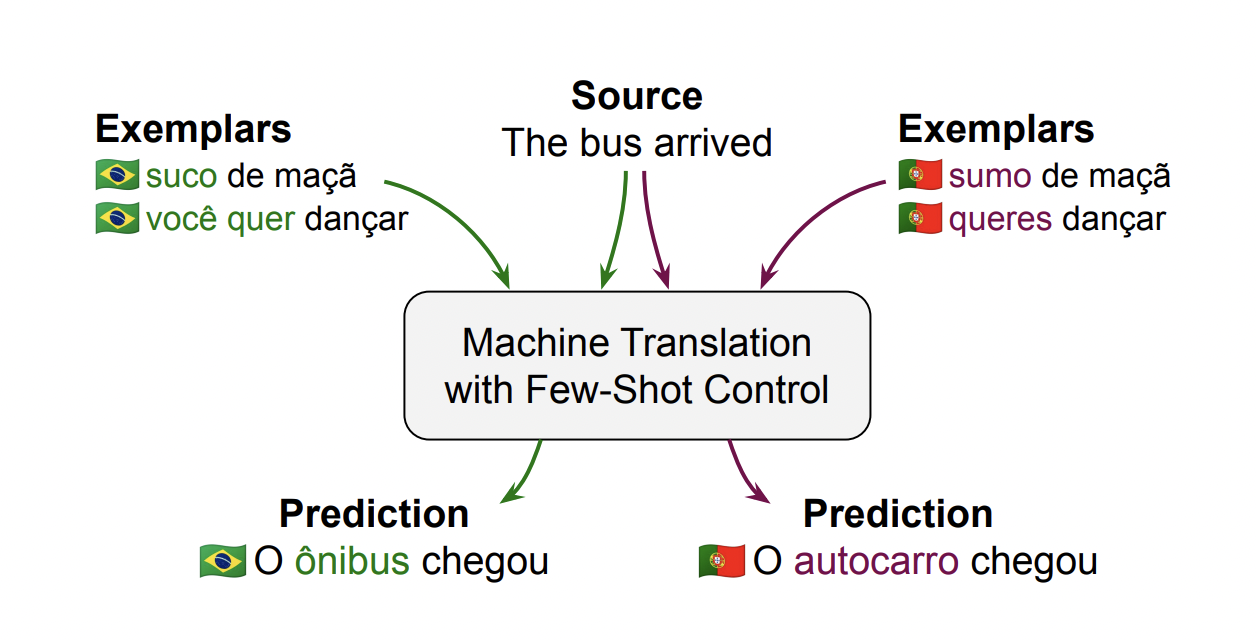
Recently published research from Google introduces Few-Shot Region-Aware Machine Translation (FRMT), a benchmark for few-shot translation that evaluates an MT model’s capability of translating into regional variants using no more than 100 labeled instances of each language variety.
To find similarities between their training examples and the small number of labeled instances (“exemplars”), MT models must employ the language patterns highlighted in the labeled examples. This allows models to generalize, translating phenomena not present in the examples correctly.
The FRMT dataset consists of partially translated versions of English Wikipedia articles into various regional Portuguese and Mandarin dialects taken from the Wiki40b dataset. The team created the dataset utilizing three content buckets to highlight the most important region-aware translation issues:
- Lexical: The lexical bucket focuses on word choices that vary by area. The team manually gathered 20–30 terms that have regionally diverse translations. They filtered and verified the translations with input from volunteer native speakers from each region. They took the final list of English terms and extract texts from the corresponding English Wikipedia articles, each with up to 100 sentences (e.g., bus). The identical procedure was independently carried out for Mandarin.
- Entity: The entity bucket is filled with individuals, places, or other entities strongly connected to one of the two regions in issue for a particular language.
- The Random bucket contains text from 100 randomly selected articles from Wikipedia’s “featured” and “excellent” collections. It is used to verify that a model appropriately handles various occurrences.
The researchers performed a human evaluation of the translations’ quality to make sure they accurately represented the region-specific phenomena in the FRMT dataset. The Multi-dimensional Quality Metrics (MQM) framework was utilized by expert annotators from each region to find and classify translation faults. The framework incorporates a category-wise weighting mechanism to combine the identified faults into a single score that generally represents the number of major errors per sentence.
The researchers invited MQM raters to evaluate translations from each region and translations from the other region of their language. The team discovered that in both Portuguese and Chinese, raters noticed, on average, two more major errors per phrase in the translations that weren’t matched than in the ones that were. This proves that the proposed dataset accurately reflects local phenomena.
The greatest way to ensure model quality is through human inspection, but this process is frequently time-consuming and costly. Hence, the researchers looked at chrF, BLEU, and BLEURT to identify an existing automatic metric that researchers may use to assess their models against the proposed benchmark. The findings suggest that BLEURT has the best correlation with human assessments and that the level of that correlation is comparable to the inter-annotator consistency using translations from a few baseline models that were also reviewed by our MQM raters.
The team hopes their work helps the research community to create new MT models that more adequately serve under-represented language variety and all speaker communities, ultimately leading to more inclusivity in natural-language technology.
Check out the Paper, Github and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.