Google AI Introduces Improved On-Device Machine Learning (ML) On Pixel 6 With Neural Architecture Search

Machine Learning is a fascinating field that offers AI-powered functionality for apps or websites. It does this by employing models that have either been pre-trained or that need to be trained.
Traditionally, ML models could only run on powerful cloud servers. When one executes inference with models directly on a device, this is known as on-device machine learning (e.g., in a mobile app or web browser). Rather than transferring data to a server and analyzing it there, the ML model processes input data (such as photos, text, or audio) on the device itself.
The on-device ML capabilities can be expanded by designing ML models specifically for the target hardware. Google researchers recently introduced Google Tensor, its first mobile system-on-chip (SoC), that combines various processing components (including central/graphic/tensor processing units, image processors, and so on) onto a single chip. It is custom-built to deliver state-of-the-art machine learning (ML) innovations to Pixel users.
The team used Neural Architecture Search (NAS) to automate the process of creating machine learning (ML) models. According to researchers, NAS encourages search algorithms to find higher-quality models while fulfilling latency and power constraints. The construction of models can also be scaled for various on-device tasks thanks to this automation. The same techniques were used to create a very energy-efficient face identification model, which is at the heart of several Pixel 6 camera functions.
Designing a Search Space for Vision Models
The architecture of the search space from which the candidate networks are sampled is an integral part of NAS. The search space is customized to contain neural network building components that operate quickly on the Google Tensor TPU.
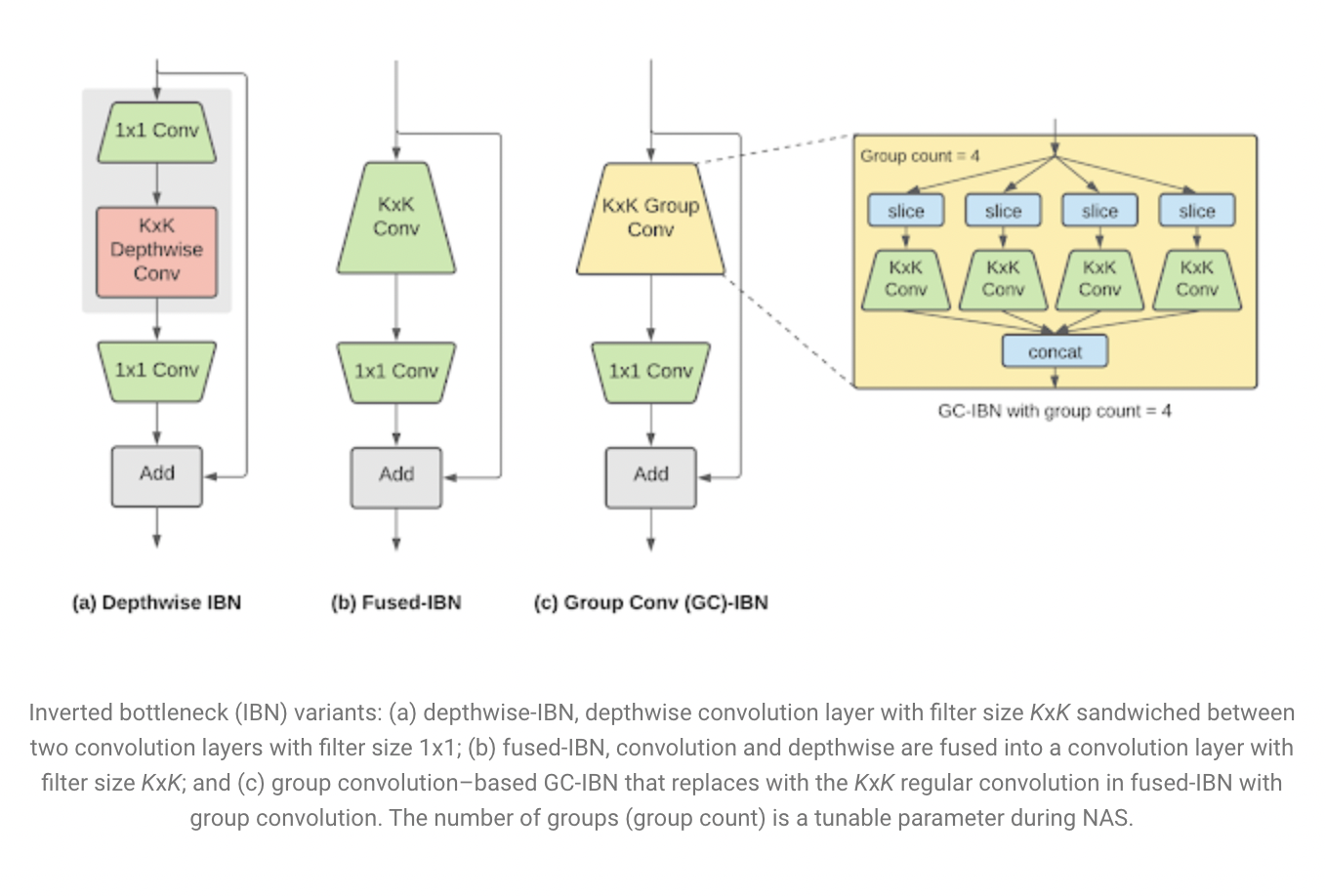
The Inverted Bottleneck(IBN) is a standard building block in neural networks for various on-device vision tasks. The IBN block comprises standard convolution and depthwise convolution layers and comes in multiple variations, each with its own set of tradeoffs. IBNs with depthwise convolution has traditionally been used in mobile vision models due to their low computational complexity. But, fused-IBNs have been shown to improve the accuracy and latency of image classification by replacing depthwise convolution with a regular convolution. However, for neural network layer configurations that are common in later stages of vision models, fused-IBNs can have prohibitively high computational and memory needs. To overcome this limitation, the team introduced IBNs that use group convolutions to enhance the flexibility in model design.
Image classification that is faster and more accurate
Which IBN version to use at which level of a deep neural network is determined by the latency on the target hardware. It is also determined by the performance of the resulting neural network on the stated job. A search space was created containing these different IBN variants and uses NAS to find image classification neural networks that optimize classification accuracy at the desired latency on TPU.
When executed on the TPU, the resulting MobileNetEdgeTPUV2 model family improves accuracy at a given latency (or latency at the desired accuracy) over existing on-device models.
Improving Semantic Segmentation on Mobile Devices
Many vision models have two parts:
- A base feature extractor that understands general image features
- Head that understands domain-specific features such as semantic segmentation (the task of assigning labels to each pixel in an image, such as sky, car, etc.) and object detection (the task of detecting instances of objects, such as dogs, windows, cars, etc., in an image).
The DeepLabv3+ segmentation head, along with the MobileNetEdgeTPUV2 classification model, increases the quality of on-device segmentation. The bidirectional feature pyramid network (BiFPN) is employed as the segmentation head to further improve the segmentation model’s quality. The BiFPN performs a weighted fusion of multiple features extracted by the feature extractor.
The segmentation model’s last layers add greatly to overall latency. This is mainly due to the operations involved in generating a high-resolution segmentation map. To reduce TPU latency, they employ an approximation method for producing the high-resolution segmentation map that reduces memory usage and gives a roughly 1.5x speedup without compromising segmentation quality.
Higher-Quality, Low-Energy Object Detection
The feature extractor receives 70% of the computing budget in traditional object detection designs, while the detection head receives 30%. For this, they used the GC-IBN blocks in a search space termed “Spaghetti Search Space”1. This allowed them to shift more of the computation budget to the head. The non-trivial connection patterns exhibited in recent NAS efforts such as MnasFPN are also used in this search area to blend distinct but related phases of the network to increase understanding.
Face Detection that is both inclusive and energy efficient
Face detection is a core technique in cameras that enables a slew of extra capabilities, including adjusting focus, exposure, and more. Because mobile cameras consume a lot of power, the face detection model must fit within a power budget. The Spaghetti Search Space is used to find architectures that maximize accuracy at a given energy target to optimize energy efficiency.
FaceSSD, the resulting face detection model, is more energy-efficient and accurate. Real Tone on Pixel 6 has this upgraded model and improvements to auto-white balance and auto-exposure tuning.
Language understanding, speech recognition, and machine translation benefit from deploying low-latency, high-quality language models on mobile devices. A natural language processing (NLP) model tailored for mobile CPUs, MobileBERT is a version of BERT. However, the quality of these models is not as good as the vast BERT models due to several architectural modifications designed to run them effectively on mobile CPUs. Because MobileBERT on TPU is substantially quicker than MobileBERT on CPU. It opens up the possibility of further improving the model architecture and narrowing the quality gap between MobileBERT and BERT. NAS was used to extend the MobileBERT architecture and find models that transfer nicely to the TPU.
With NAS, the team was able to apply the design of machine learning models to a wide range of on-device applications, resulting in models that deliver state-of-the-art quality on-device while staying within the latency and power limits of a mobile device.
Github: https://github.com/tensorflow/models/tree/master/official/projects/edgetpu/
References:
- https://ai.googleblog.com/2021/11/improved-on-device-ml-on-pixel-6-with.html
Suggested
Credit: Source link
Comments are closed.