Google AI Introduces ‘LIMoE’: One Of The First Large-Scale Architecture That Processes Both Images And Text Using A Sparse Mixture Of Experts
This Article is written as a summay by Marktechpost Staff based on the paper 'Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and blog post. Please Don't Forget To Join Our ML Subreddit
Google Research has long been interested in sparsity research. Pathways encapsulate the research goal of creating a single colossal model that can handle thousands of activities and data types. Sparse unimodal models for language (Switch, Task-MoE, GLaM) and computer vision have made significant progress so far (Vision MoE). Today, the Google Al team is researching big sparse models that simultaneously handle images and text with modality-agnostic routing, another major step toward the Pathways objective. Multimodal contrastive learning is a viable option, as it requires a thorough grasp of both images and text to match pictures to their accurate descriptions. The most effective models for this job have relied on separate networks for each modality.
Sparse models stand out as one of the most promising ways for deep learning in the future. Light models using conditional computation learn to route specific inputs to different “experts” in a potentially extensive network, rather than every portion of a model analyzing every information. This has numerous advantages. First, model size can grow while computing costs remain constant, which is a more efficient and ecologically friendly way to scale models, which is typically necessary for good performance. Sparsity also compartmentalizes brain networks organically. For dense models that learn several different jobs concurrently or sequentially, harmful interference, or catastrophic forgetting, where the model worsens at previous functions as new ones are added, are prevalent difficulties (continual learning). Sparse models help avoid both of these problems: by not applying the entire model to all inputs, the model’s “experts” can focus on distinct tasks or data types while benefiting from the model’s shared components.
Google AI team presents the first large-scale multimodal architecture utilizing a sparse mixture of experts in “Multimodal Contrastive Learning with LIMoE: the Language Image Mixture of Experts.” It analyzes images and words simultaneously but with sparsely activated experts who organically specialize. LIMoE outperforms comparable dense multimodal models and two-tower techniques in zero-shot image categorization. LIMoE can scale up gently and learn to handle a wide range of inputs because of sparsity, which alleviates the tension between being a jack-of-all-trades generalist and a master-of-one expert.
Models with a Sparse Mixture of Experts
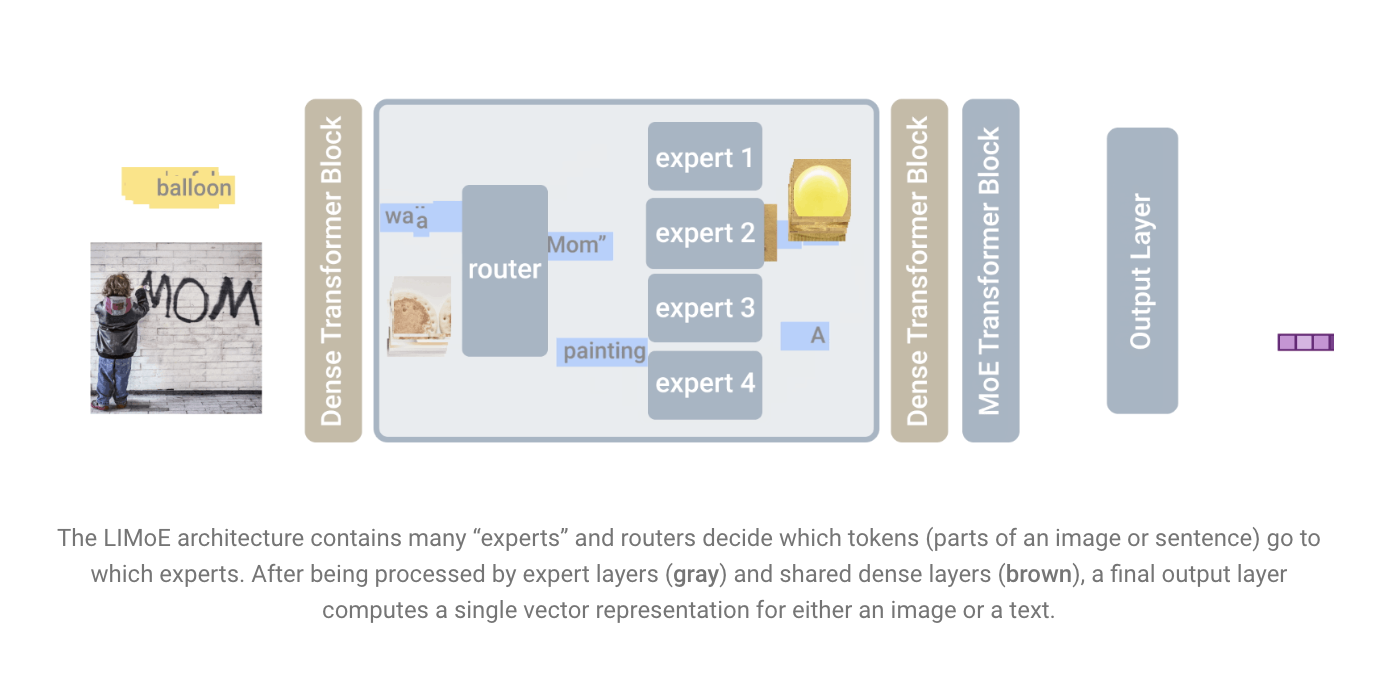
Data is represented by transformers as a series of vectors (or tokens). They can describe nearly anything that can be defined as a series of passes, such as photographs, movies, and sounds, although they were developed for text. In newer large-scale MoE models, expert layers have been added to the Transformer architecture.
A typical Transformer comprises several “blocks,” each containing several distinct layers. A feed-forward network is one of these layers (FFN). This single FFN is replaced in LIMoE and the works described above by an expert layer with multiple parallel FFNs, each of which is an expert. A primary router predicts which experts should handle which tokens, given a series of passes to process. Only a few experts are activated on every ticket, which means that while the model capacity is considerably increased by having so many experts, the actual computational cost is kept low by employing them sparingly. The model’s price is comparable to the regular Transformer model if only one expert is activated.
LIMoE performs exactly that, activating one expert per case and matching the dense baselines’ computing cost. The LIMoE router, on the other hand, may see either image or text data tokens.
When MoE models try to deliver all tokens to the same expert, they fail uniquely. Auxiliary losses, or additional training objectives, are commonly used to encourage balanced expert utilization. Google AI team discovered that dealing with numerous modalities combined with sparsity resulted in novel failure modes that conventional auxiliary losses could not solve. To address this, they created additional losses. They implemented routing prioritization (BPR) during training, two innovations that resulted in stable and high-performing multimodal models.
The new auxiliary losses (LIMoE aux) and routing prioritization (BPR) enhanced overall performance (left) and boosted the routing behavior success rate (middle and right). A low success rate shows that the router does not utilize all of the experts available and that many tokens are dropped owing to individual expert capacity being exceeded, which usually suggests that the sparse model is not learning well. The LIMoE combo guarantees high routing success rates for images and text and dramatically improved speed.
With LIMoE, you can learn in a variety of ways.
Models are trained on coupled image-text data in multimodal contrastive learning (e.g., a photo and its caption). Typically, an image model extracts an image representation, while a text model extracts a text representation. The contrastive learning goal encourages image and text representations to be close together for the same image-text combination and far apart for information from other pairs. Such aligned representation models can be adapted to new tasks without further training data (“zero-shot”).
On the popular ImageNet dataset, CLIP and ALIGN (two-tower models) scaled this technique to attain 76.2 percent and 76.4 percent zero-shot classification accuracy, respectively. One-tower models that compute both picture and text representations are investigated. They discovered that this had a detrimental impact on dense models, most likely due to harmful interference or a lack of capacity. A compute-matched LIMoE, on the other hand, outperforms not only the one-tower thick model but also the two-tower dense model. Google AI team used a similar training strategy to CLIP to train a group of models. LIMoE’s use of sparsity, as illustrated below, provides a significant performance improvement over dense models of comparable cost.
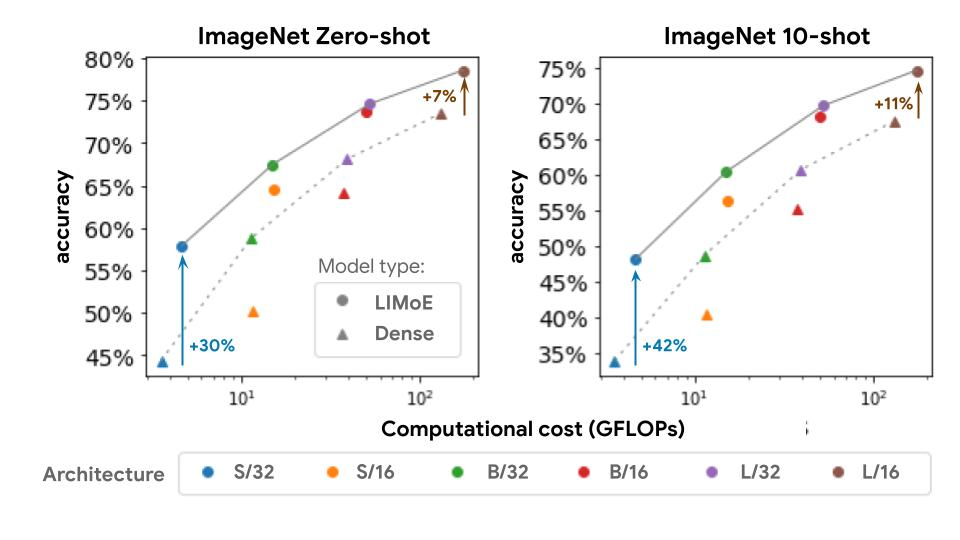
LiT and BASIC methods used specific pre-training procedures in addition to scaling and repurposing image models already of extraordinarily high quality. Despite lacking any pre-training or modality-specific components, LIMoE-H/14 accomplished an 84.1 percent zero-shot accuracy training from scratch. It’s also fascinating to compare the scale of these models: The parameter models LiT and BASIC are 2.1B and 3B, respectively. LIMoE-H/14 contains 5.6 billion parameters, but sparsity allows it to apply only 675 million parameters per token, making it substantially lighter.
Understanding the Behavior of LIMoE
LIMoE was inspired by the idea that sparse conditional computation allows a generalist multimodal model to achieve the specialization required to excel at comprehending each modality while remaining generic.
Distributions for an eight expert LIMoE; percentages indicate the amount of image tokens processed by the expert. There are one or two experts clearly specialized on text (shown by the mostly blue experts), usually two to four image specialists (mostly red), and the remainder are somewhere in the middle.
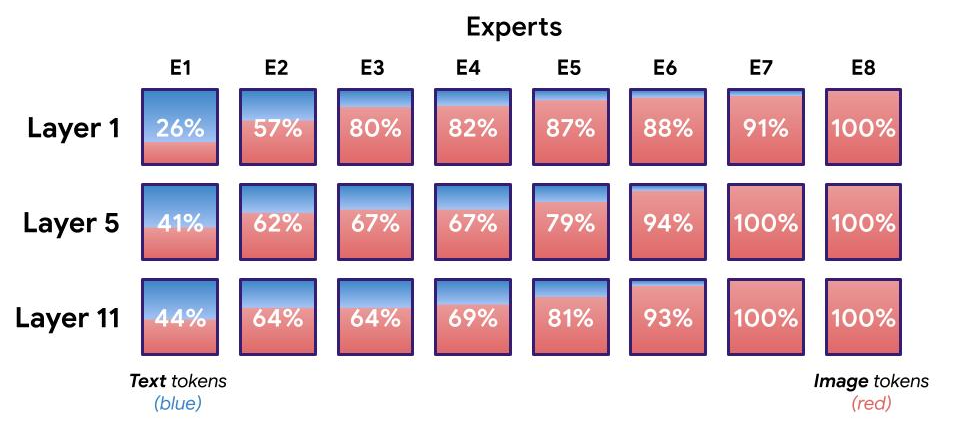
First, they observe the emergence of experts who specialize in specific modalities. Because there are many more picture tokens in their training setting than text tokens, all experts process at least some images. However, some experts process predominantly images, mostly text, or both.Distributions for an eight-expert LIMoE; percentages reflect how many images tokens the expert process. One or two experts are text specialists, two to four image specialists, and the others are somewhere in the center.

For each token, LIMoE selects an expert. They see the emergence of semantic specialists who specialize in specific areas such as plants or wheels despite not being trained.
Taking Action
Multimodal models that manage many tasks are a possible path forward. Two crucial criteria for success are size and the capacity to prevent interference between diverse activities and modalities while leveraging synergies. Sparse conditional computation is a great technique to accomplish both of these goals. LIMoE’s good performance with less computing provides performant and efficient generalist models that nevertheless have the capacity and flexibility for the specialization required to excel at specific tasks.
Credit: Source link
Comments are closed.